- The paper introduces Centroid Attention, which clusters inputs to reduce computational overhead while preserving critical features.
- It integrates self-attention and centroid attention in a layered architecture to achieve efficiency in tasks like text summarization and point cloud classification.
- Experiments demonstrate that centroid transformers enhance scalability and accuracy, outperforming state-of-the-art methods in multiple applications.
The paper "Centroid Transformers: Learning to Abstract with Attention" (arXiv ID (2102.08606)) introduces Centroid Attention, a novel variant of self-attention tailored to enhance computational efficiency in transformers by reducing the dimensionality of outputs while maintaining critical information. This research extends traditional self-attention mechanisms by framing them in terms of clustering concepts, thereby establishing theoretical connections between attention and clustering algorithms.
Self-Attention Mechanism
Traditional self-attention mechanisms are instrumental in transformers, mapping N inputs to N outputs and thus maintaining the size of data through layers of processing. Within each layer, pairwise interactions among elements are calculated, casting an O(N2) complexity that can become computationally prohibitive for large datasets. The self-attention process assigns weights to relationships between input elements, leveraging these weighted sums to propagate contextual information across sequences.
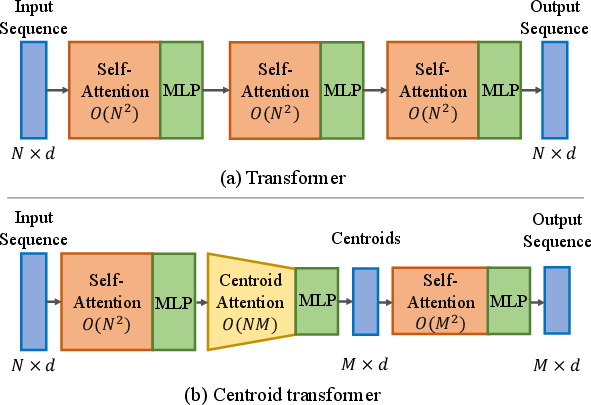
Figure 1: The vanilla transformer (a) which maps N inputs to N outputs; and our centroid transformer (b) which summarizes N inputs into M ``centroid'' outputs (M\leq N) to save computational cost and filter out useless information simultaneously.
Centroid Attention Mechanism
Centroid Attention fundamentally modifies this approach by summarizing N inputs down to M outputs, where M≤N. By operating within this reduced-dimensional space, it creates "information bottlenecks" to filter non-essential information and vastly reduce computational overhead. This process is analogous to clustering where representative centroids encapsulate key input features.
Through deriving gradient descent updates from clustering objectives, an attention-like mechanism emerges, which not only encapsulates the inputs into centroids but also approximates self-attention operations under this new framework.
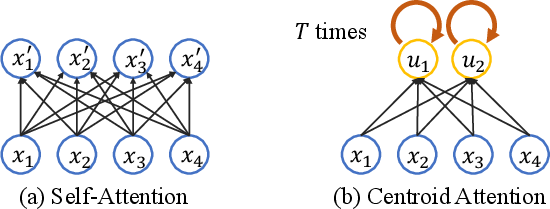
Figure 2: (a) The self-attention module, which modifies the input sequence $\{\vv x_i\}$ into $\{\vv x_i'\}$ by updating them with pairwise interactions. (b) The centroid attention module transforms the input sequence $\{\vv x_i\}$ into a set of centroids $\{\vv u_i\}$ by first initializing the centroids and then updating them.
The architecture leverages alternating blocks of self-attention and centroid attention, interspersed with MLP layers. This strategy capitalizes on the strengths of centroid differentiation at selected layers, progressively abstracting information into increasingly concise representations.
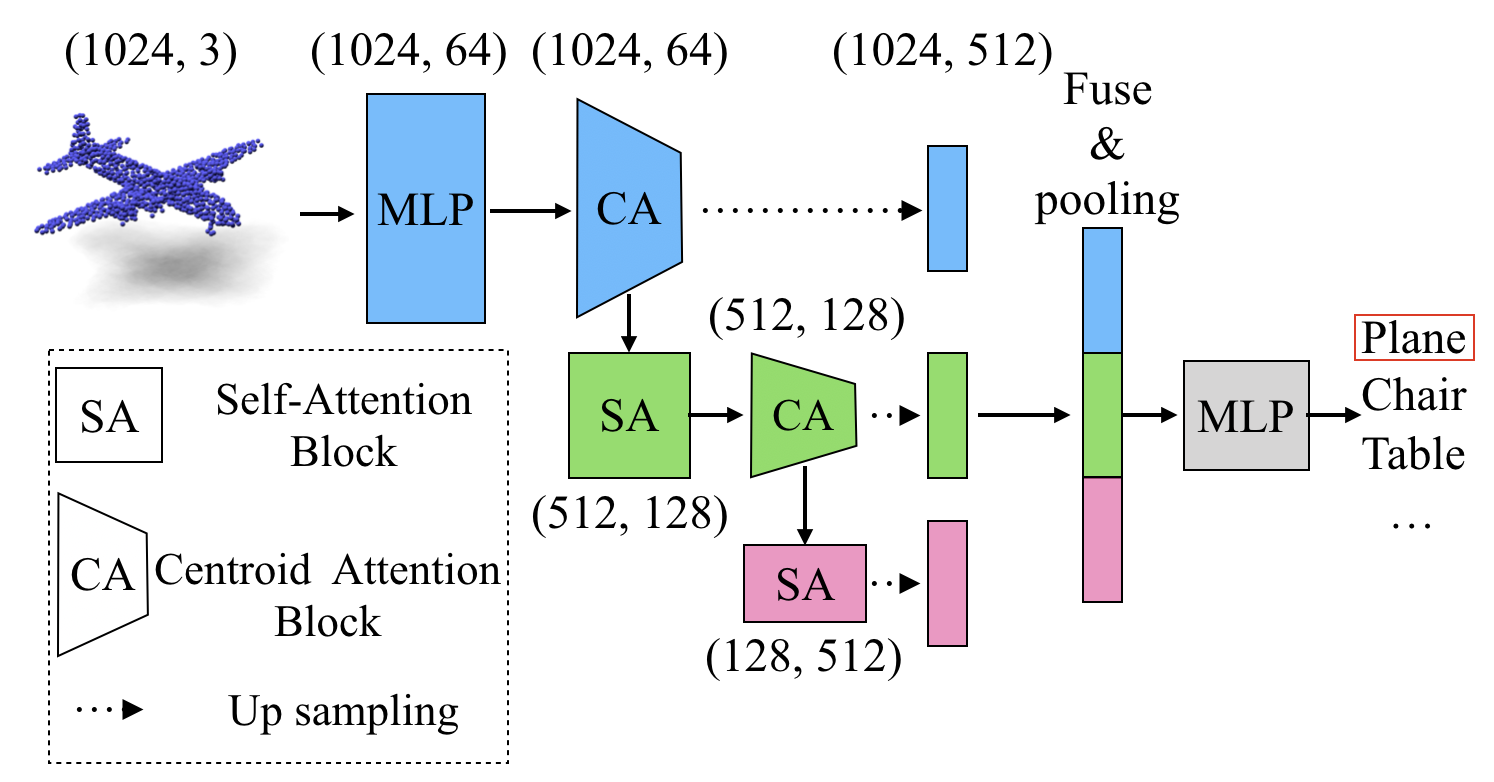
Figure 3: The architecture of the centroid transformer we used for point cloud classification. CA" represents centroid attention andSA" vanilla self-attention.
Experiments and Applications
Abstractive Text Summarization
In tasks of abstractive text summarization using the Gigaword corpus, centroid transformers demonstrated competitive ROUGE scores with significantly reduced MACs, indicating computational efficiency. The study further highlights the effectiveness of initialization strategies such as Mean-Pooling compared to Random Sampling.
Point Cloud Classification
Centroid Transformers were applied to point cloud classification on the ModelNet40 dataset, showing superior accuracy with reduced computational demand compared to state-of-the-art models like SepNet-W15. These results underscore the architecture's ability to manage long sequences by aggregating points into semantic clusters.

Figure 4: Learning classification on ModelNet40 with centroid transformer. We visualize the K-nearest-neighbours (KNNs) points of some sampled points.
Point Cloud Reconstruction
The research explored point cloud reconstruction, using centroid attention to replace dynamic routing in capsule networks for better semantic understanding and reduced reconstruction error. Visualization of reconstruction highlights the semantically meaningful clustering gained through centroid attention.
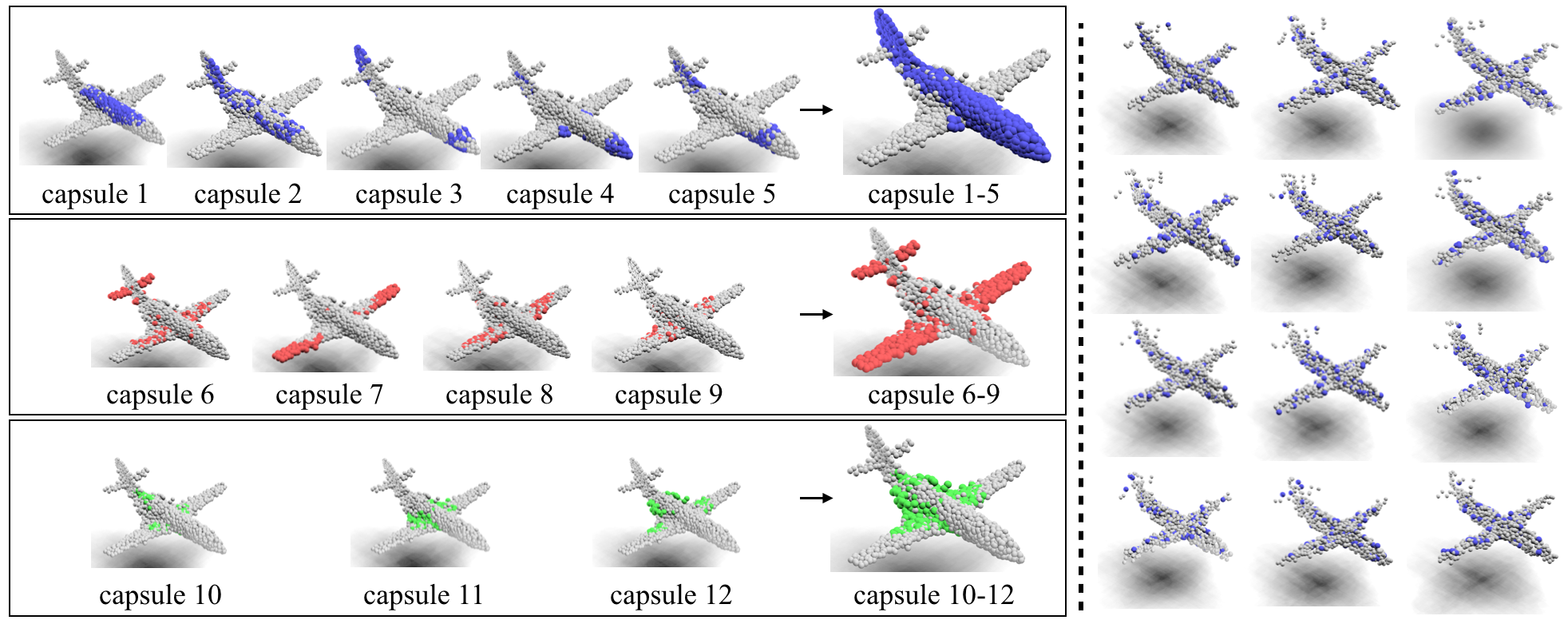
Figure 5: Point cloud reconstruction using 3D Capsule Network with highlighted semantic parts.
When applied to image classification in Vision Transformer settings, the centroid mechanism showed comparable or better performance than DeiT models, with additional computational savings due to dynamic downsampling and centroid attention integration.
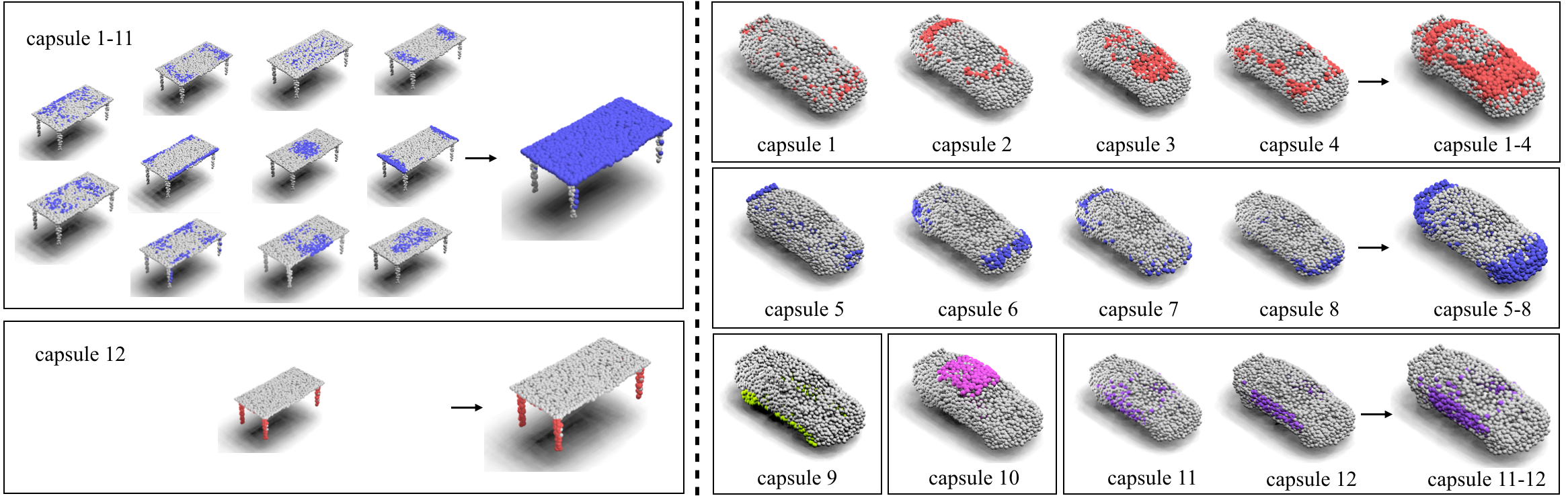
Figure 6: More visualization of capsules learned by our method. Capsules map to semantically meaningful parts.
Conclusion
The paper establishes a nuanced layer for transformers that balances the trade-offs between computational efficiency and model performance. Centroid Attention, conceptualized as a clustering task within transformer architectures, offers implications for processing efficiency, scalability in large datasets, and potential applications in various domains such as vision, NLP, and 3D modeling.
These findings invite future explorations into the adaptability of centroid-based attention systems, targeting newer transformer-based architectures and domains yet to harness full synergistic efficiencies.

