- The paper presents a novel few-shot sequence learning algorithm using task-specific token embeddings in Transformers.
- It demonstrates comparable performance to advanced techniques while reducing computational cost by avoiding complex second-order derivative computations.
- The approach is validated through extensive experiments on sequence classification, transduction, and compositional tasks.
Introduction
The paper, "Few-shot Sequence Learning with Transformers" (2012.09543), explores few-shot learning for discrete sequence modeling using Transformers. Traditional few-shot learning has predominantly focused on computer vision applications. This paper extends the application to discrete sequences such as token sequences in NLP and actions in RL. The primary contribution is an efficient learning algorithm, task adaptation via task-specific token embeddings, eliminating the need for architectural alterations or complex second-order derivative computations. The proposed method demonstrates comparable performance to current methods with enhanced computational efficiency.
Problem Definition
The few-shot sequence learning problem is defined over tasks sampled from a specified task distribution pdata(T). The training process involves a set of tasks denoted as {Titrain}i=1N, where each task consists of several training examples {(xji,yji)j=1Ni}. The problem is categorized into sequence classification, where sequences are labeled categorically, and sequence transduction, which involves modeling the joint distribution of a sequence of outputs conditioned on input context.
Approach
Our method implements a few-shot learning algorithm using a Transformer architecture. This model introduces a task-specific embedding, z, to condition the model's behavior for varied tasks. The key is to integrate these task embeddings into the token sequence input without modifying the core model parameters θ, as seen in prior works [1shot, vaswani2017attention].

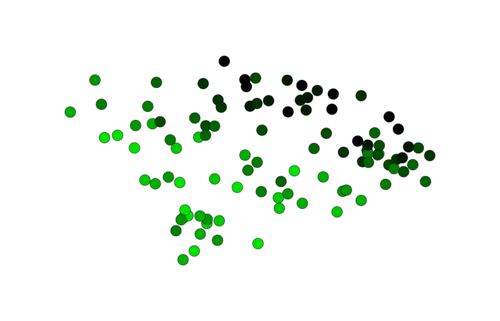
Figure 1: 2D PCA projections of task embeddings learned by our algorithm for the gridworld domain. Tasks visualized here have the same start position (4,4). Points are color-coded based on horizontal (left plot) and vertical (right plot) coordinates of the end position corresponding to each task.
For the transformers, task embeddings optimize via gradient descent, offering simplicity and computational efficiency over complex architectures and more resource-demanding strategies like those that compute second order derivatives.
Figure 1: 2D PCA projections of task embeddings learned by our algorithm for the gridworld domain. Tasks visualized here have the same start position (4,4). Points are color-coded based on horizontal (left plot) and vertical (right plot) coordinates of each task’s end position.
Training and Inference
The training algorithm employs an alternating-minimization approach. Parameters of the model θ, shared among tasks, are adjusted distinctly from a task-specific embedding z, which is optimized using gradient descent without altering θ. Algorithm 1 demonstrates the pseudo-code outline for this training methodology. The model evidences aptitude for unseen task adaptation at test time, enhancing few-shot learnability.
Our approach fits within the context of meta-learning by conditioning model architectures to spark few-shot learning. Unlike adaptive learning algorithms, the introduced method focuses on efficient sample learning by optimizing a task-specific parameter. It distinguishes itself from methods like MAML [3] and CAVIA [4], which involve more computation-intensive optimizations, by relying on a simpler and efficient alternating minimization algorithm.
- Sequence Classification tasks rely on transformers configured similarly to BERT [5] with a classification head, where a task embedding is used instead of the traditional special token.
- For Sequence Transduction, a transformer decoder architecture appends a task-specific embedding to represent task information.
Figure 1: Model performance and computational time, averaged across k∈{1,5,10,20} shots.
Experiments
The experimental evaluation utilized transformer models with four layers and an embedding size of 128, optimized using the Adam optimizer. We incorporated task embeddings with a dimension of 128 within the model structure, and a flexible number of optimization steps for task embeddings, capped at 25 during training.
In sequence classification, the Task-Agnostic Transformer served as a baseline without task signification tokens, whereas the Multitask Transformer, Matching Networks [6], and SNAIL [8] employed different methodologies of task embeddings. Results indicate that while Multitask models improve performance in high-shot learning contexts, they do not perform optimally under few-shot constraints.
The TAM approach showed comparable or superior performance compared to more complex methods like MAML [3] and CAVIA with second order derivatives, while maintaining computational efficiency.
(Figure 2)
Table 2: k-shot sequence classification and transduction experiments performance on non-compositional settings.
Compositional Task Representations
Compositionality was assessed for its impact on few-shot learning, leveraging primitive task descriptions to evaluate generalization on combinations of unknown subsets of primitives. In the compositional path-finding task demonstrated through synthetic simulations (Figure 1), the presence of compositional structure boosted performance considerably for tasks involving discrete sequences when fewer labeled samples (1-shot) were available.
(Figure 2)
Table 3: Compositional models for few-shot sequence classification and transduction.
Ablation Studies
To investigate the role of task embeddings, three configurations were assessed, integrating task embeddings in different ways: direct input token embeddings, adapter layers [6], and normalization parameters. Results demonstrated comparable performance for both input conditioning and adapter parameters, while lateral embedding into Layer Normalization parameters [7, 8] fared sub-optimally.
The upheld importance of employing transformers over recurrent models (LSTMs) attests to the architectural design’s efficacy. As depicted in Figure 2, the transformer consisently outperformed LSTMs across scenarios, with alternated minimization yielding consistent efficiencies over multitask baselines.
(Figure 3)
Table 4: k-shot accuracy for different architectures.
Additionally, task embeddings visualized in Figure 1 illustrate the learned task structure, revealing clusters in the representation space according to task end positions.
Conclusion
This paper introduced an approach enabling transformers to adapt efficiently for few-shot sequence learning by leveraging task embeddings optimized through alternating minimization. Empirical results indicated improved performance over existing methods such as CAVIA in both computational cost and adaptability, with particular strengths in scenarios with minimal labeled data. This paper indicates that applying and simplifying transformer models in few-shot settings not only preserves the model's efficacy but offers optimization advantages relevant for tasks involving discrete sequences. Future research might focus on cross-domain applications of TAC and further exploration into the compositional capabilities of task embeddings across diverse learning paradigms.
