- The paper introduces a rigorous KL-divergence-based formulation to unify MaxEnt and Relative Entropy IRL methods.
- It develops an exact forward-backward inference algorithm that efficiently handles variable-length demonstrations and reduces computational complexity.
- Experimental results on synthetic and real-world datasets demonstrate lower Inverse Learning Error and scalable performance compared to existing methods.
Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms
Introduction
This paper introduces new perspectives and algorithms for Maximum Entropy Inverse Reinforcement Learning (MaxEnt IRL), focusing on addressing shortcomings in existing approaches and offering a unified framework for understanding MaxEnt and Relative Entropy IRL. The authors propose a model-free learning algorithm that more rigorously derives MaxEnt IRL for stochastic MDPs, previously based on heuristic arguments. This approach explores the implications of using Kullback-Leibler divergence instead of maximizing entropy, leading to more robust and exact reward learning.
Methodology
The primary contribution lies in reformulating MaxEnt IRL using KL-divergence, providing a more rigorous foundation than earlier heuristic methods. This formulation unifies MaxEnt IRL with Relative Entropy IRL by highlighting the role of reference distributions. The authors demonstrate improved algorithm implementation capabilities by deriving an exact forward-backward inference algorithm allowing for variable-length demonstrations, a notable limitation in earlier methods.
Forward and Backward Message Passing: The core inference process involves using forward and backward message passing variables to efficiently compute partition functions and state-action-state marginals. This dynamic programming approach ensures scalability by applying a "padding trick" to maintain computational efficiency even with large path lengths, reducing time complexity from quadratic to linear in terms of demonstration path length.
Figure 1: An example MDP with four states and a single action. The MDP has a single deterministic starting state s1 and a single terminal state s4.
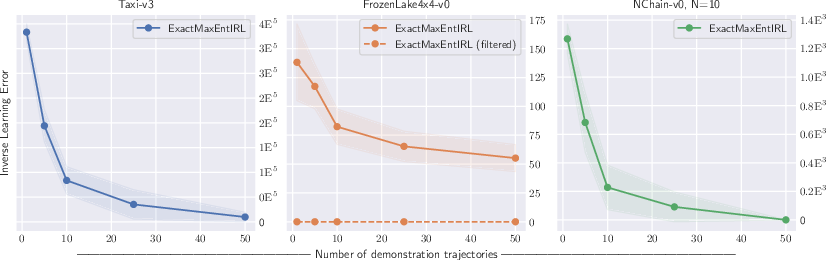
Figure 2: Our ExactMaxEntIRL Algorithm Performance vs. Number of Demonstration Paths, showing means and 90% confidence intervals over 50× repeats.
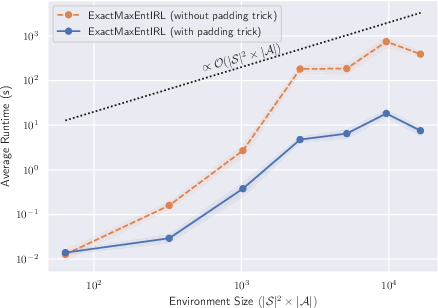
Figure 3: IRL Algorithm Runtime vs. Problem Size. Plots show mean and 90% confidence intervals over 30× repeats.
Experimental Evaluation
The authors conducted experiments using both synthetic and real-world datasets. They verified the accuracy of reward functions recovered by their algorithm using metrics like Inverse Learning Error (ILE) and demonstrated superior performance compared to existing IRL methods, particularly in handling large-scale datasets like the Porto taxi service GPS data.
- Synthetic Environments: The experiments on OpenAI Gym environments showed that the exact inference algorithm yields lower ILE with increasing demonstration paths compared to previous approaches.
- Driver Behavior Forecasting: In a large-scale, real-world application involving driver behavior, the exact algorithm significantly improved predictive accuracy and preference matching over Ziebart's methods and baseline models. The optimization techniques enabled handling large datasets effectively, making this approach applicable to practical, complex domains.
Implications and Future Work
The findings emphasize the potential for improved reward learning in IRL through exact inference and sophisticated handling of demonstration variability. By offering a more principled approach to MaxEnt IRL, this work paves the way for enhanced applications in complex real-world scenarios, such as autonomous driving and behavior prediction.
Potential future directions include:
- Extending exact algorithms to handle more complex features using the sum-product algorithm.
- Exploring model-free importance sampling learning algorithms as an alternative for continuous MDPs.
- Investigating the effectiveness of learned rewards for both stationary and non-stationary policies, enhancing the application scope of MaxEnt IRL models.
Conclusion
This paper presents significant advancements in MaxEnt IRL by introducing a rigorous KL-divergence-based formulation and an efficient, exact inference algorithm. The proposed methodologies demonstrate substantial improvements in reward learning accuracy and scalability. The open-source implementation facilitates further research and development in diverse IRL applications, marking a notable contribution to the field of reinforcement learning.
