- The paper introduces a multilayer network model that leverages both intra‐ and inter-layer connections to improve credit risk predictions.
- It employs a personalized PageRank algorithm to capture borrower influence and default propagation across different network layers.
- Experimental results reveal significant AUC improvements when integrating network-derived features into logistic regression and XGBoost models.
Multilayer Network Analysis for Improved Credit Risk Prediction
Introduction
The paper "Multilayer Network Analysis for Improved Credit Risk Prediction" (2010.09559) implements multilayer network models to enhance the accuracy of credit risk predictions across interconnected borrower relationships. The methodology targets scenarios where correlative defaults are suspected due to shared structural risks. The approach leverages the computational capabilities of network science to analyze multifaceted relationships inherent in lending contexts.
Network Construction and Centrality Measures
The framework presented in the paper constructs multilayer networks (Figure 1) by leveraging attributes such as geographical locations and economic activities to depict interconnectedness among borrowers. It employs a supra adjacency matrix to represent both intra-layer and inter-layer connections, with stickiness serving as a weighting parameter for inter-layer transitions.
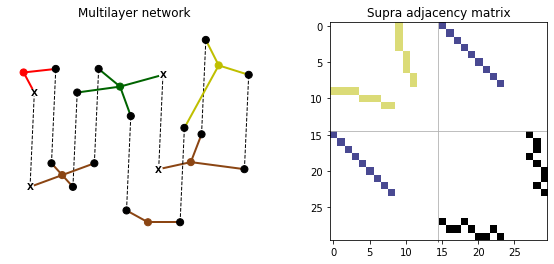
Figure 1: The multilayer network representation showing borrower nodes, location nodes, and product nodes across two layers.
Further, the paper introduces a personalized PageRank algorithm adapted for multilayer networks. Unlike conventional PageRank, which utilizes a uniform random walk approach, the personalized variant biases jumps based on the influence within specific borrower subsets. Three influence matrix scenarios — intra-layer, inter-layer, and combined — guide the algorithm's focus on default propagation within these stratifications (Figure 2).
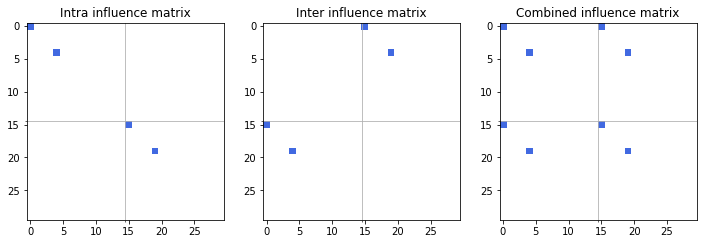
Figure 2: Configuration of influence matrices for personalized PageRank in multilayer networks.
Experimental Setup and Results
The research evaluates the predictive efficacy of multilayer network-derived features against conventional credit scoring models. By extracting features such as default degree and PageRank centrality from the networks, improved scoring accuracy is achieved. Statistical analyses demonstrate substantial AUC improvements when integrating multilayer network variables within logistic regression and XGBoost frameworks (Figure 3).
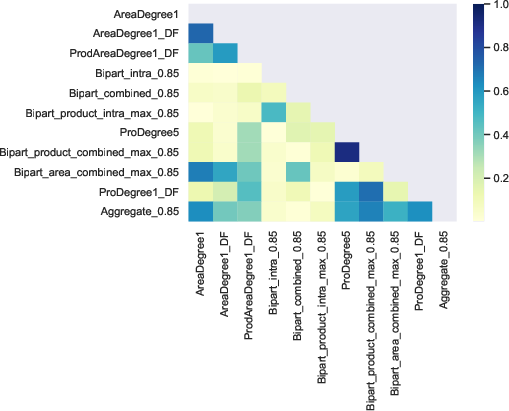
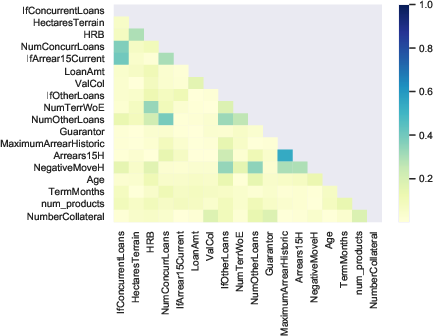
Figure 3: Network variables illustrating centrality and default influence impacting credit prediction models.
Key results reveal that network connectivity, particularly among defaulters, significantly correlates with subsequent risk levels. The algorithms expose sophisticated interactions whereby individual borrower risks are jointly influenced by network position and prevailing structural conditions (Figure 4).
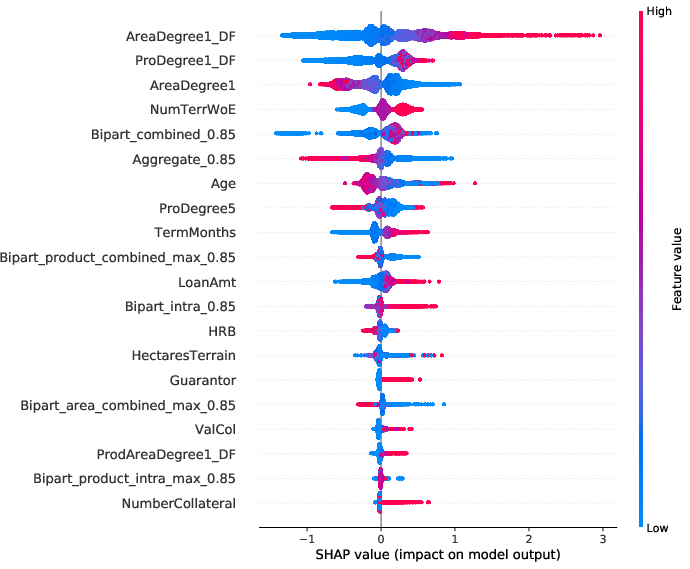
Figure 4: Summary of average Shapley values highlighting variable importance for interpretation of network effects.
Model Interpretations
The model interpretations advanced in the paper utilize Shapley values to underscore how network-induced variables influence predictions. Notably, borrowers densely connected within default-prone networks manifest heightened risk profiles, which nonlinear propagation scores emphasize (Figure 5).
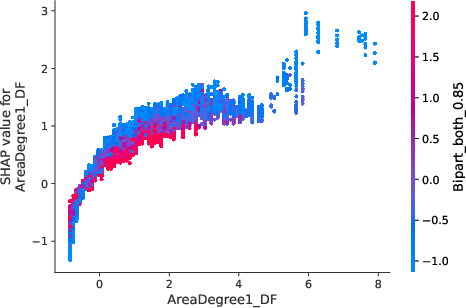
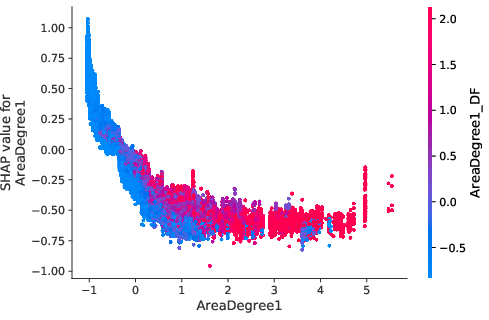
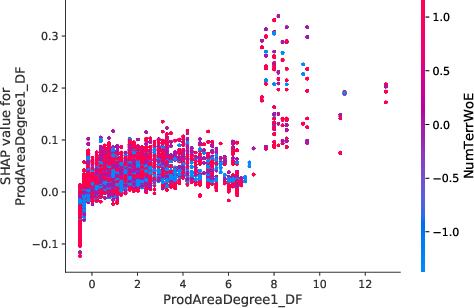
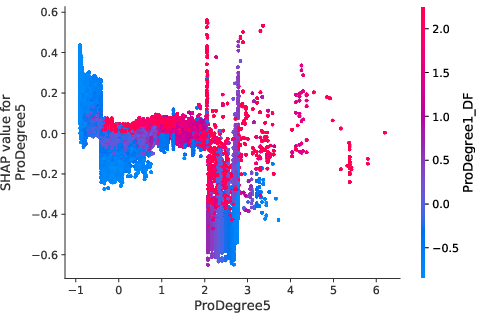
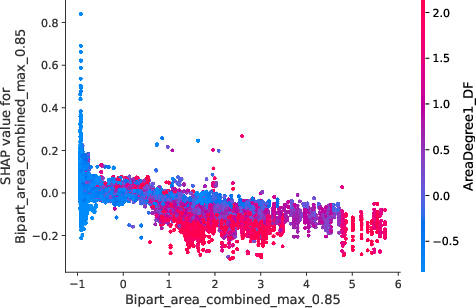
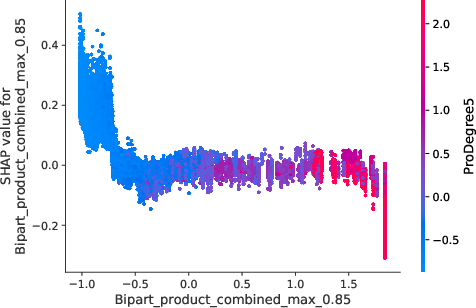
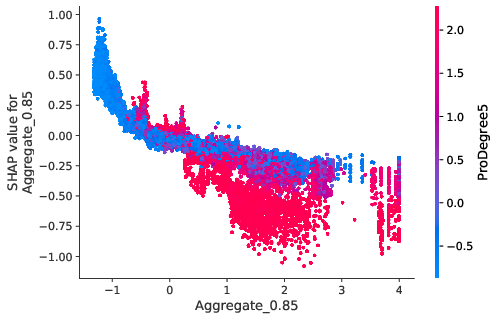
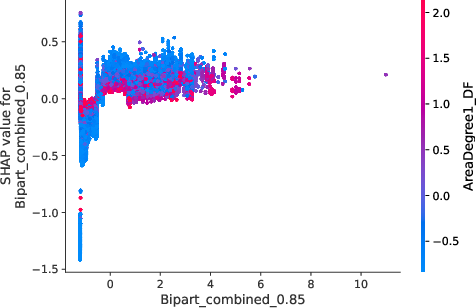
Figure 5: Value distribution for borrowers showcasing centrality metrics and their impact on predictive models.
Conclusion
In conclusion, the multilayer network strategy instituted in this work marks a significant paradigm shift in credit risk evaluation, extending beyond traditional univariate models to capture complex borrower interdependencies. This innovation provides actionable insights for lenders, offering enhanced predictive reliability and enabling preemptive measures against systemic defaults. Future directions may explore deep learning applications to further refine network influence metrics across broader financial datasets.