- The paper introduces transformer-based architectures for text segmentation, demonstrating that local context can effectively identify semantic shifts.
- It details three models—Cross-Segment BERT, BERT+Bi-LSTM, and Hierarchical BERT—each leveraging different strategies for encoding context.
- Evaluation on standard datasets shows these models outperform previous methods, balancing performance with reduced computational load.
Overview
The paper "Text Segmentation by Cross Segment Attention" presents three transformer-based architectures for text segmentation, addressing both document and discourse segmentation tasks. These models achieve significant performance improvements over existing methods across standard datasets while maintaining fewer parameters, offering potential practical benefits.
Architectures
Cross-Segment BERT
The Cross-Segment BERT model leverages local context around candidate segment breaks. It uses a simple architecture that encodes sequences around a potential break, using BERT's positional embeddings and token representations. This method, while simplistic, achieves surprisingly competitive results, suggesting that subtle semantic shifts can be detected using only local context.
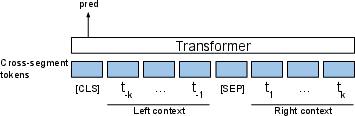
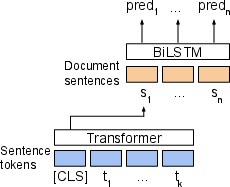
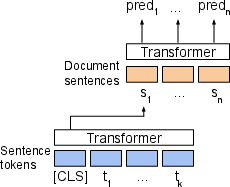
Figure 1: Our proposed segmentation models, illustrating the document segmentation task.
BERT+Bi-LSTM
This model combines BERT with a Bi-LSTM layer, where each sentence is encoded independently by BERT, and the resulting sentence representations are processed by a Bi-LSTM. This hierarchical approach captures sequential dependencies while ensuring efficient modeling of sentence sequences within documents.
Hierarchical BERT
Hierarchical BERT introduces a document-level encoding layer built on BERT encodings of individual sentences. This architecture fully leverages the document context to achieve high-level coherence in segmentation predictions, especially for tasks involving document-level continuity.
Evaluation and Results
The proposed models were evaluated on Wiki-727K, Choi, and RST-DT datasets. Results demonstrated that these models outperformed previous state-of-the-art approaches. Notably, Cross-Segment BERT achieved strong results using local context, challenging assumptions about the necessity of full document context for segmentation tasks.
| Model |
Wiki-727K F1 |
RST-DT F1 |
Choi Pk |
| Cross-Segment BERT |
66.0 |
95.0 |
0.07 |
| BERT+Bi-LSTM |
59.9 |
95.2 |
0.17 |
| Hierarchical BERT |
66.5 |
95.2 |
0.38 |
Analysis and Ablation Studies
Context Length
Further analysis revealed the significance of context size for Cross-Segment BERT. Extending context length affected performance, with diminishing returns beyond a certain point. An ablation paper isolated the impact of leading versus trailing context, confirming the necessity of viewing contexts on both sides of a candidate break.
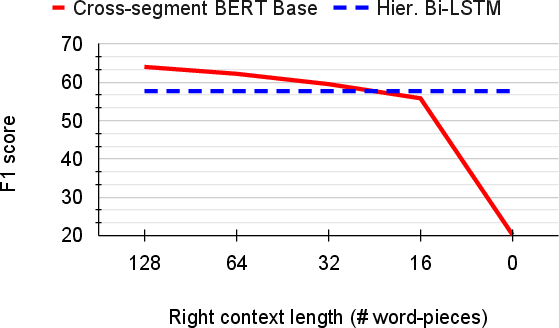
Figure 2: Analysis of the importance of the right context length (solid red line). Dashed blue line denotes the hierarchical Bi-LSTM baseline encoding the full context.
Model Size
Evaluations of model configurations highlighted a trade-off between model size and performance. Distillation methods demonstrated potential in reducing model size without significant loss of performance, thereby improving computational efficiency and applicability in real-world scenarios.
Conclusion
The paper successfully introduces robust models for text segmentation using transformer architectures, with Cross-Segment BERT showing that local context can be leveraged effectively. The findings propose a shift towards simpler models in certain segmentation tasks, encouraging future research to explore these architectures with consideration of context complexity and computational constraints.