- The paper presents an encoder-decoder debiasing framework that preserves inherent gender properties while eliminating harmful stereotypes.
- It categorizes vocabulary into feminine, masculine, gender-neutral, and stereotypical groups and employs denoising autoencoders to project embeddings into a debiased space.
- Experimental results show that this method outperforms existing approaches, improving fairness and ethical compliance in downstream NLP applications.
Gender-preserving Debiasing for Pre-trained Word Embeddings
Introduction
The paper "Gender-preserving Debiasing for Pre-trained Word Embeddings" (1906.00742) addresses the significant challenges associated with bias in word embeddings. These embeddings, which are ubiquitous in NLP tasks, often encode discriminative biases related to gender, race, and ethnicity. Such biases not only misrepresent societal stereotypes but also propagate these biases into downstream NLP applications. This paper specifically focuses on a debiasing methodology that seeks to preserve gender-related, non-discriminative information while eliminating stereotypical gender biases, thereby improving the ethical and legal compliance of NLP systems.
Methodology
The proposed debiasing approach categorizes vocabulary into four distinct types of words: feminine, masculine, gender-neutral, and stereotypical. The method ensures that:
- Feminine and masculine words maintain their gender-related properties.
- Gender-neutral words retain neutrality.
- Stereotypical biases are removed.
In implementing this process, the paper utilizes an encoder-decoder framework through denoising autoencoders to project original word embeddings into a debiased vector space. The encoder part of the model specifically handles the transformation of word embeddings, ensuring the balance between retaining useful information and removing biases. A novel aspect of this method is its categorization of words into those that are inherently gendered versus those that possess unfair biases, thus enabling nuanced treatment of different word types.
Experimental Results
The authors have empirically tested their approach on multiple benchmark datasets, including \textsf{SemBias}. The method shows notable improvements in debiasing performances, outperforming existing state-of-the-art methods like hard-debiasing and GN-GloVe. Remarkably, the proposed method not only effectively debiases stereotypes but also preserves gender-related information intrinsic to particular words, which is critical for various NLP applications.
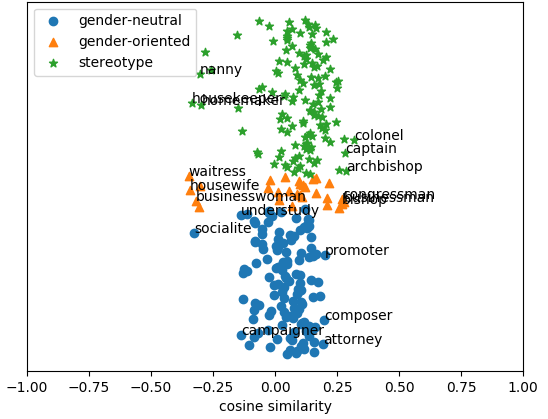
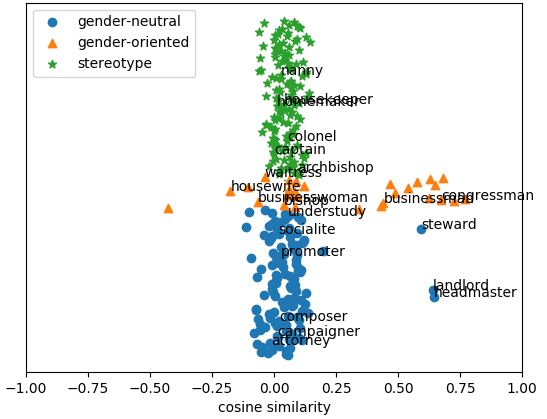
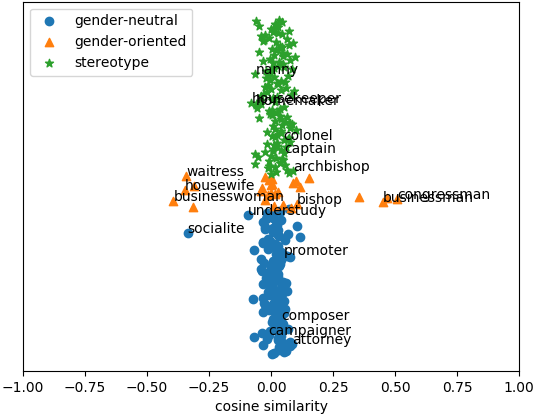
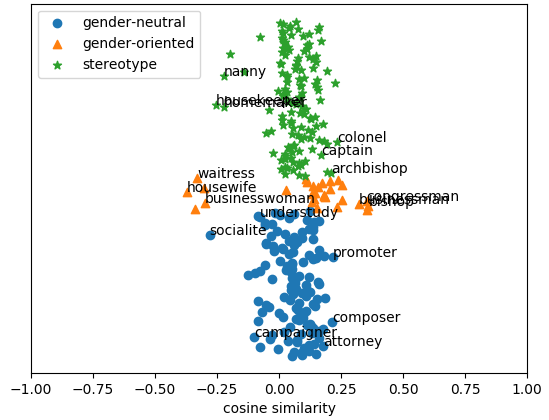
Figure 1: GloVe
In this context, Figure 1 illustrates the word embeddings' behavior following the debiasing process, highlighting the method's ability to maintain intrinsic gender-related qualities while addressing stereotypical biases.
Semantic and Practical Implications
The paper contributes significantly to both theoretical and practical dimensions of debiasing. Theoretically, it presents a robust framework that enhances the understanding of nuanced biases in word embeddings. Practically, it provides a methodology that can be seamlessly integrated into existing NLP pipelines, improving fairness in applications ranging from sentiment analysis to dialogue generation. The method's ability to be applied alongside existing debiasing strategies further underscores its utility.
Conclusion
In summary, this research contributes a sophisticated strategy for debiasing word embeddings, highlighting the necessity for models that can discern between useful gender information and harmful stereotypes. This advancement is crucial in developing NLP applications that are fairer and more robust across demographic dimensions. Future directions hinted at by the authors include extending the method to address other demographic biases such as ethnicity or age, promising broader implications for the field of AI ethics and accountability.

