- The paper introduces a hypernetwork generative model to sample diverse, high-performance neural network weights.
- It employs latent variable techniques and mode connectivity principles to navigate high-dimensional weight manifolds.
- Experimental results demonstrate improved classification accuracy and robustness through ensembles of varied network configurations.
A Generative Model for Neural Networks: An Authoritative Summary
Introduction
This paper explores a hypernetwork approach for generating neural network weights that achieve high performance while maintaining diversity in configuration. It extends the concept of mode connectivity in neural networks' loss landscapes to a higher dimensional manifold. By employing a hypernetwork, represented as a generative model, it constructs a manifold in the weight space where diverse, high-performance configurations can coexist.
Methodology
The central component of this approach is the hypernetwork, a neural network that outputs weights for a target network given latent input. The training objective optimizes for a balance between high accuracy and network diversity. The diversity term integrates trivial symmetries into its calculation, thereby enhancing the meaningful representation of generated network diversity.
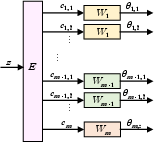
Figure 1: Architecture block diagram of the hypernetwork with latent variable z, extractor E, codes c, weight-generators W, and generated weights θ.
The hypernetwork architecture involves parameter sharing, leveraging convolutional layers to effectively manage the size of the hypernetwork relative to the target network. The architecture of the hypernetwork consists of several sub-networks: an extractor and weight-generators, each with distinct roles in managing and processing the latent representations to produce diverse network configurations.
Results and Evaluation
Experimentation demonstrates that the hypernetwork can generate weights placed on a complex manifold in the space of possible configurations. The diversity of generated networks is illustrated through PCA scatter plots, which display non-trivial manifold structures across layers.
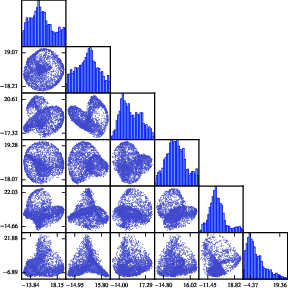
Figure 2: Scatter plots of the generated weights for a specific second layer filter, in PCA space. The (i,j) scatter plot has principal component i against principal component j.
The ability of the hypernetwork to create ensembles of networks is evidenced by improvements in classification accuracy, suggesting the manifold extends into non-trivial dimensions beyond simple symmetries. The hypernetwork's capability to encompass various sub-optimal configurations further justifies the diversity-oriented design.
By not relying on a probabilistic output for the target network, this approach widens its applicability beyond Bayesian settings. Its loss function includes a hyperparameter that controls the trade-off between accuracy and diversity, a flexibility not present in traditional VI-based hypernetworks. This method's facilitation of ancestral sampling positions it as a viable alternative for exploratory and optimization tasks in high-dimensional neural network landscapes.
Implementation Considerations
The practical implementation requires careful calibration of the hyperparameter λ to balance accuracy with diversity, without overwhelming the computational resources. The generator’s modularity—exemplified by the separation of extraction and weight generation tasks—indicates opportunities for optimization through reduced parameterization.
Conclusion
The paper introduces a novel generative model approach for sampling high-performance, diverse weights for neural networks. Future prospects include leveraging hypernetworks for tasks like transfer learning and efficient network compression. These avenues have practical implications for deploying robust, adaptable AI models capable of navigating complex decision landscapes in dynamic environments.