- The paper introduces a novel GAN that leverages a composition-by-decomposition (CoDe) framework to synthesize composite images using unpaired inputs.
- It employs spatial transformer networks, relative appearance flow, and mask prediction to ensure accurate spatial alignment and occlusion handling.
- Example-specific meta-refinement (ESMR) enhances test-time fidelity, yielding superior results on both synthetic and real-world compositing tasks.
Compositional GAN: Learning Image-Conditional Binary Composition
Introduction and Motivation
"Compositional GAN: Learning Image-Conditional Binary Composition" (1807.07560) presents a generative framework for synthesizing composite images conditioned on explicit object pairs. Conventional GAN and cGAN models typically map from a single input domain, lacking mechanisms to explicitly model multi-object 2D or 3D interactions, spatial layout, occlusion ordering, and viewpoint transformations. The proposed framework directly addresses these limitations by generating a realistic composite image from two input objects sampled from distinct marginal distributions and modeling their joint distribution.
This work introduces a self-consistent Composition-by-Decomposition (CoDe) network, leveraging decomposition as both supervision and test-time refinement. The formulation enables composition without requiring paired data and allows example-specific meta-refinement (ESMR) for improved test-time fidelity. The method is evaluated across synthetic and real domains, including shape-object, face-accessory, and urban scene compositing tasks.

Figure 1: Binary composition examples—top row: background image, middle row: foreground object, bottom row: generated composite.
Model Architecture
The architecture centers on several key modules: (i) a composition generator, (ii) a decomposition network for self-consistency, (iii) relative Spatial Transformer Network (STN) and Relative Appearance Flow Network (RAFN) for spatial and viewpoint alignment, (iv) a mask prediction network for object segmentation, and (v) inpainting mechanisms to address unpaired training scenarios. At a high level, the generation pipeline operates by spatially shifting and scaling input objects, synthesizing their relative viewpoints if necessary, and conditionally generating the composite. The system enforces that the composite can be decomposed back to the constituent objects—a form of cycle consistency that constrains realism and content preservation.
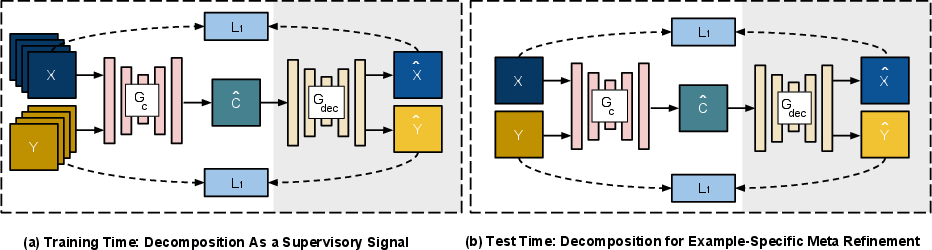
Figure 2: (a) CoDe architecture—composition network receives supervisory signal from the decomposition network (b) ESMR—test-time fine-tuning on a single input pair.
For training, {x,y}→c is modeled, with adversarial and multiple reconstruction losses applied in both composed and decomposed space. For unpaired data, an inpainting network restores occluded segments, effectively converting unpaired samples into pseudo-paired ones. The architecture and data flow are summarized below.
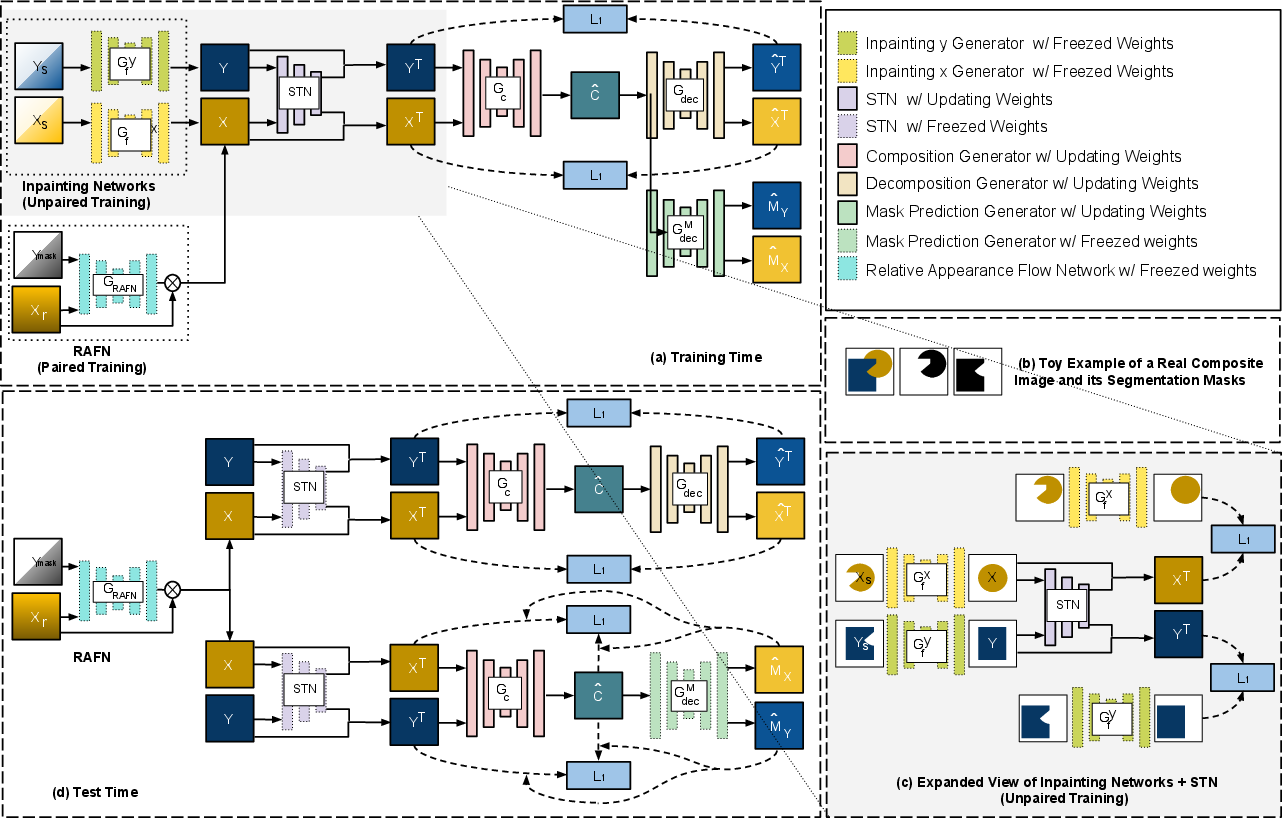
Figure 3: Schematic overview—training pipeline incorporates inpainting, RAFN, STN, and CoDe modules, with masks and viewpoints as auxiliary signals; test-time ESMR refines the predicted composite.
Spatial Alignment and Mask Prediction
Relative STN explicitly learns affine transformations for both objects, conditioned on their joint context. For object domains requiring viewpoint alignment, RAFN predicts appearance flow fields to mediate geometric compatibility. Mask prediction provides per-pixel assignment for occlusion-aware decomposition, informing both the L1 and cross-entropy objectives.
Composition-by-Decomposition (CoDe) and Self-Consistency
A salient innovation is the integration of decomposition supervision: the composition generator's output, c^, is decomposed back to (x^T,y^T), and explicit L1 self-consistency loss is imposed. This approach not only regularizes generation but also enables end-to-end training even without corresponding input-output pairs.
To further improve test-time realism and better preserve input object characteristics (color, texture, geometry), example-specific meta-refinement is employed. ESMR utilizes the decomposition network as a source of gradient signals, fine-tuning the composition network on-the-fly for each test instance. During ESMR, STN, RAFN, and mask network weights are frozen; only the CoDe layers are updated using adversarial and decomposition-based self-consistency losses.
Experimental Evaluation
Synthetic Datasets
The framework is evaluated on composite scenes involving ShapeNet objects (chairs+tables, baskets+bottles), entailing challenges in 3D rotation, scaling, placement, and occlusion. Results indicate the approach produces realistic composites that qualitatively and quantitatively resemble ground truth, outperforming baseline CycleGAN and Pix2Pix translations, which lack explicit compositional mechanisms.

Figure 4: Test results on chair-table and basket-bottle domains; comparison of generator outputs (before/after ESMR), outputs without inpainting, and nearest neighbor samples from the training data.
Ablation studies demonstrate that inpainting and mask modules are critical in handling occlusions, and the absence of ESMR or self-consistency degradation leads to color bleed, misaligned objects, or incorrect occlusion ordering.
Real-World Datasets
The model generalizes to real-world tasks such as adding sunglasses to faces (CelebA) and placing cars into street scenes (Cityscapes), domains characterized by strong spatial dependencies and variable occlusion.

Figure 5: Test examples from the face-sunglasses composition task—our model's output (paired/unpaired training) compared to ST-GAN results.
In all setups, the model is both data-efficient (requiring fewer or unpaired examples) and delivers superior AMT user preference scores compared to ST-GAN.

Figure 6: Test street scenes-cars composition—progression from input objects, pre/post ESMR outputs, summation of masked inputs, ST-GAN, and nearest neighbor visualizations.
Ablation and Baseline Comparisons
Head-to-head visualizations highlight clear qualitative superiority over domain-translation baselines, which are not designed for explicit binary composition and fail to capture plausible spatial/occlusion relationships.
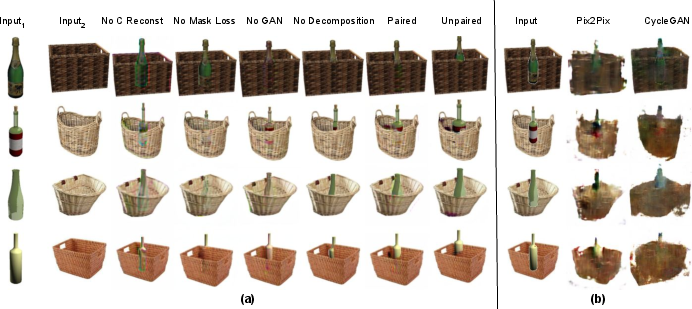
Figure 7: Ablation—effect of removing loss terms or whole modules (pixel loss, mask, GAN, decomposition cycle); baseline Pix2Pix and CycleGAN outputs for direct comparison.
Implications and Future Directions
The compositional GAN architecture demonstrates that decomposition consistency is a powerful self-supervisory signal, enabling robust, flexible composition across varied datasets and under both paired and unpaired supervision. This work suggests that future generative systems should incorporate more structured multi-entity modeling. The explicit modeling of spatial relations and occlusion hierarchies will be instrumental for controllable scene synthesis, image editing, and cross-domain translation tasks.
Potential extensions include scaling to compositions of more than two objects, handling non-rigid or articulated entities, and integrating photometric interaction modeling (e.g., inter-object lighting/shadow). Furthermore, the ESMR test-time adaptation paradigm is general and may benefit other conditional generation tasks suffering from generalization bottlenecks or appearance drift.
Conclusion
This paper introduces a structured binary compositional generation framework that supersedes prior GAN approaches by integrating explicit modules for spatial arrangement, viewpoint alignment, and object-aware self-consistency. The strong empirical results, both on synthetic and real datasets, highlight the effectiveness of composition-by-decomposition and meta-refinement strategies in generative image modeling. The paper's approach provides a scalable foundation for future work on compositional and multi-object image synthesis.