MoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
Abstract: Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: https://lizhiqi49.github.io/MoCA





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces MoCA, a new AI model that can build complex 3D objects and scenes by combining many smaller pieces (called “components”). Think of it like making a LEGO set: each part matters, and you can mix and match to create detailed objects and rooms. MoCA is designed to be both high-quality and fast, even when there are lots of parts—up to 32 in one 3D asset.
The main questions the researchers asked
The researchers focused on two simple questions:
- How can we generate 3D objects and scenes made from many components without the computer slowing down or running out of memory?
- Can we make the model smart enough to focus on the most important parts that need to interact, while still keeping a rough idea of the rest?
How MoCA works (in everyday language)
To explain MoCA, here are the building blocks and the key ideas behind it.
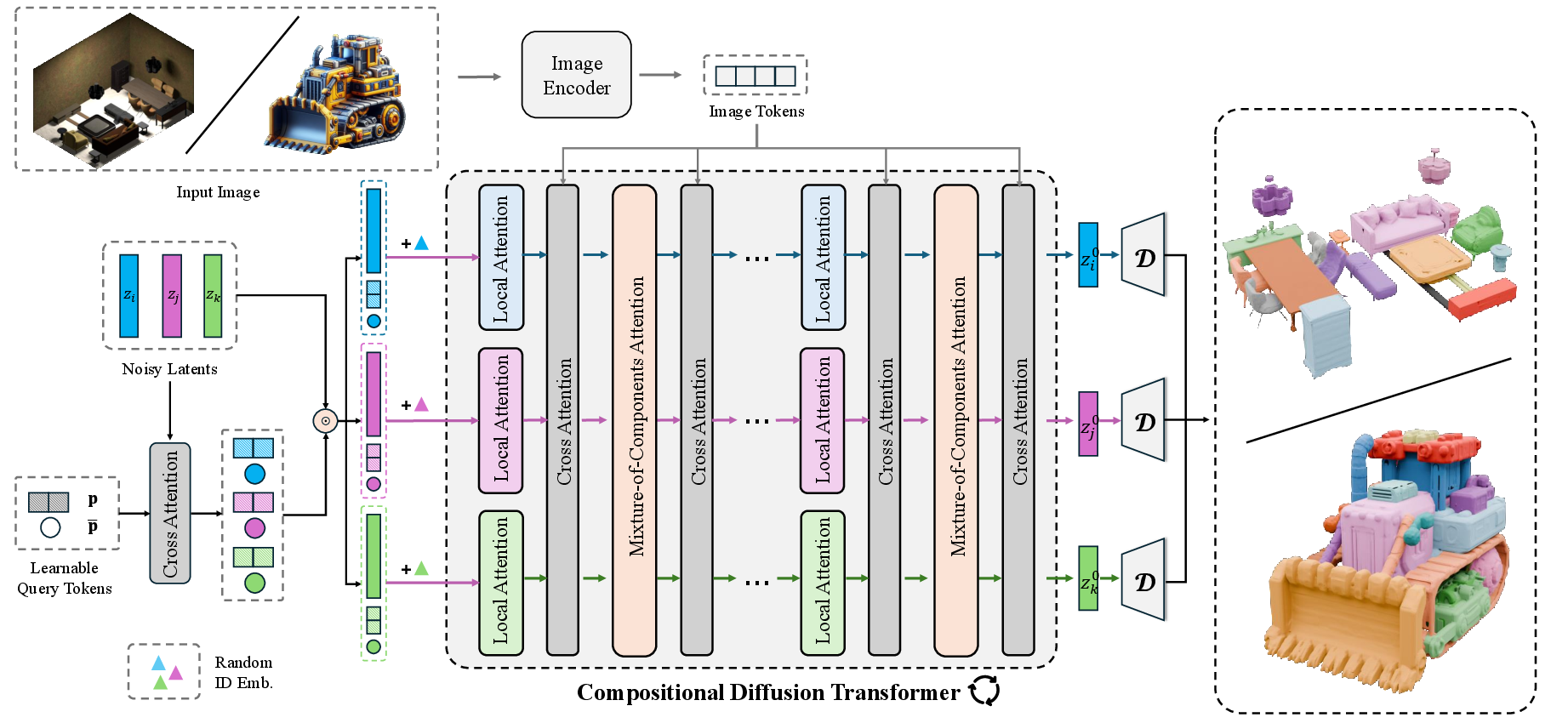
Building blocks: How 3D shapes are represented
- Instead of working directly with 3D meshes, MoCA uses a “latent” format: a set of short vectors (like tiny notes) that describe the shape. This is called a “vecset.”
- A special encoder turns a 3D object into these notes, and a decoder turns the notes back into a full 3D shape. The final surface (the mesh) is extracted with a standard algorithm.
Local vs. global attention: Who talks to whom
- Attention is a way for parts of the model to “look at” other information. Imagine each component asking: “Which other components should I pay attention to?”
- Local attention: each component mostly focuses on itself to improve its own features.
- Global attention: components talk to other components to make sure they fit together properly (like a chair positioned near a table in a scene).
The big challenge and MoCA’s solution
- Challenge: If every component talks to every other component all the time, the cost grows very fast as you add more parts. It’s like trying to have a group chat with 50 people where everyone reads every message—slow and messy.
- MoCA’s solution has two smart tricks:
- Importance-based routing: For each component, MoCA picks only the top-k other components that matter most to it and looks at them in detail. For example, a “hand” might mostly need the “wrist” and “forearm.”
- Compression of less important components: The model makes short summaries of the less important components. It doesn’t ignore them—it keeps a coarse overview so the global layout still makes sense, but avoids wasting time on unneeded details.
How the model picks important components
Each component has an “anchor token,” a small summary of its features.
- The model compares the anchor of one component with anchors of others to get an importance score (a number between 0 and 1 using a sigmoid function).
- It selects the top-k components to look at closely (full detail) and uses compressed summaries for the rest.
Keys, queries, and values (a quick analogy)
- In attention, “queries” ask questions, “keys” help match who to look at, and “values” provide the actual information.
- MoCA multiplies the importance scores into the keys. That way, the attention formula naturally prioritizes important components without causing numerical problems.
Multi-head routing and load balance
- Multi-head routing: Different “heads” (think: small teams) can learn different kinds of relationships between components at the same time.
- Load balance: During training, MoCA sometimes randomly samples which components to focus on (based on importance). This prevents the model from always choosing the same few parts and helps it learn more broadly.
Training in simple terms
- The model learns by starting from a noisy version of the shape’s latent notes and predicting how to “move” back to the clean version step by step. This is a type of diffusion training (here, a “rectified flow” objective).
- It can use an image as a guide (for example, a photo of a chair or a room), and sometimes it trains without the image to make it more robust.
What the experiments found and why it matters
The researchers tested MoCA on two tasks:
- Part-composed 3D object generation: Given a single image, MoCA generates a 3D object split into logical parts (like seat, legs, back for a chair).
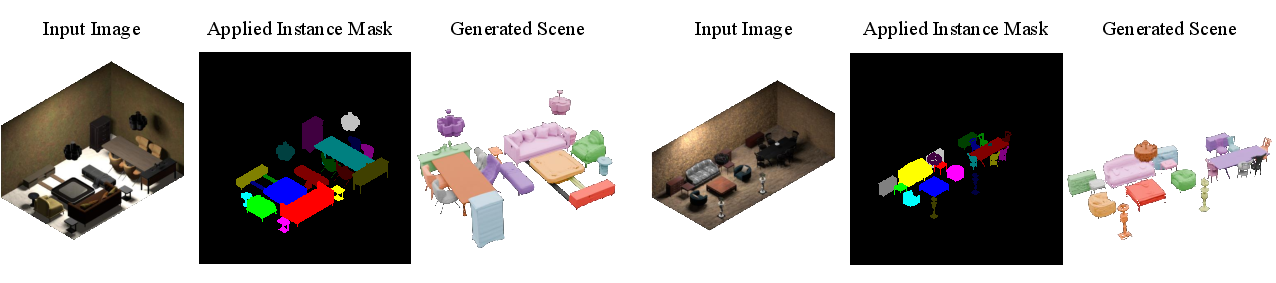
- Instance-composed 3D scene generation: Given a scene image and per-object masks, MoCA builds a 3D room with many objects placed correctly.
Key results:
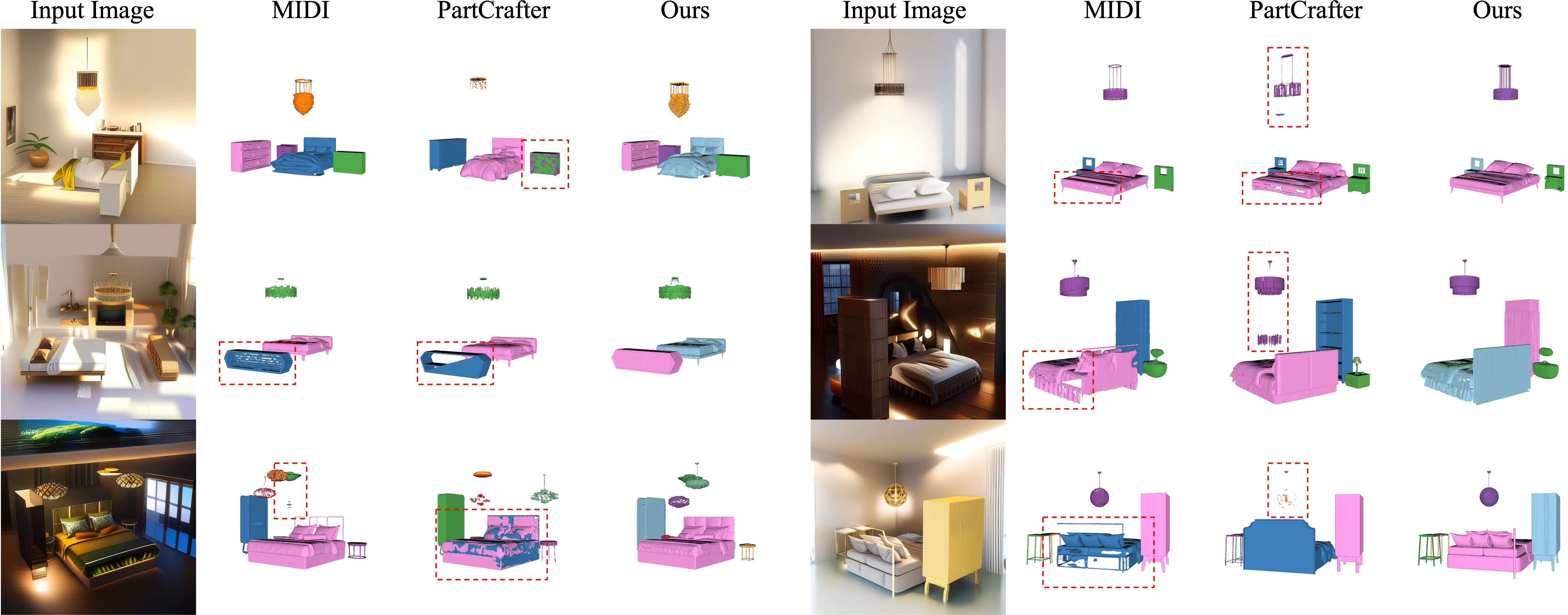
- MoCA produced cleaner, more detailed geometry than other methods.
- It kept parts well separated (fewer overlaps or “stuck-together” pieces).
- It handled more components per asset—up to 32—better than previous systems.
- It worked on real images too, not just synthetic examples.
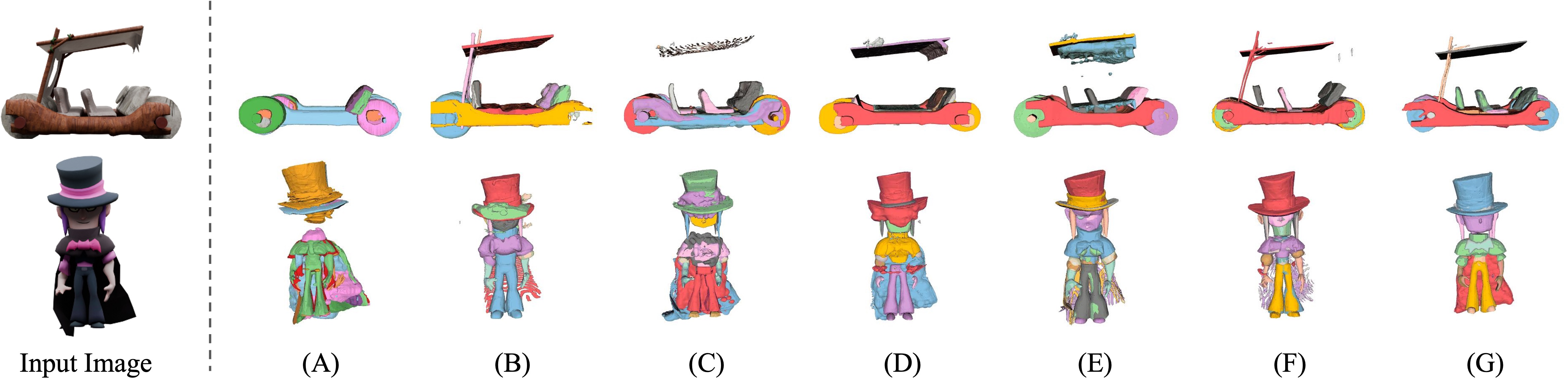
- In “ablation” tests (turning off features to see what breaks), both routing to important components and compressing less important ones were crucial. Changing how scores were applied (to keys vs. values) or using softmax instead of sigmoid made results worse.
Why it’s important:
- It makes complex 3D generation faster and more scalable.
- It allows fine-grained control—great for editing, reusing parts, animating individual components, and customizing materials per part.
- It’s helpful for applications like game asset creation, virtual production, robotics, and computer-aided design.
What this could mean for the future
MoCA shows a practical path to building detailed 3D content made of many parts without overwhelming computation. By focusing attention smartly—deep detail where it’s needed, summaries where it’s not—MoCA opens the door to:
- Creating richer, larger scenes with many objects.
- Easier editing at the part level (swap a chair’s legs or change a cabinet’s handles).
- Faster pipelines for content creators and developers.
Limitations and next steps:
- The decoder (VAE) was kept frozen; very tiny components can be harder to reconstruct perfectly. The authors plan to fine-tune it using part-level data to improve small-part quality.
Overall, MoCA pushes 3D generation toward being more modular, efficient, and controllable—like building with smarter LEGO blocks that know which other blocks they need to work with.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved gaps and limitations that could guide future research on MoCA.
- Missing quantitative efficiency benchmarks: no runtime, FLOPs, or VRAM measurements versus baselines and naive global attention as the number of components N scales; lack of empirical speed-up curves across N, top-k, and compression ratio σ.
- Scalability beyond 32 components remains untested: no systematic study of generation quality, training stability, and memory usage for N > 32 (e.g., 64–128 parts/instances), especially in complex scenes.
- Router interpretability and correctness are unverified: no analysis of whether selected “important” components correlate with spatial proximity, semantic adjacency, or physical interactions; no diagnostics (e.g., routing entropy, selection frequency distributions, per-head diversity).
- Sensitivity to routing hyperparameters is unclear: top-k set to ~25% and σ=8 without systematic tuning; no guidance on choosing k and σ per domain/task, nor adaptive strategies (e.g., content-aware or per-component k/σ).
- Robustness to conditioning signals is untested: scene generation relies on per-instance masks, but there is no evaluation of robustness to mask noise, occlusions, segmentation errors, or missing masks; mask-free alternatives (text or layout constraints) are not explored.
- Component identity embeddings are ad hoc: random ID embeddings (codebook size 50) may collide or break permutation invariance and consistency across samples; no ablation on learned/semantic IDs or persistent identifiers, and no formal analysis of permutation invariance under IDs.
- Local block constraints may limit expressivity: vecset tokens are restricted to self-attention only; the trade-offs of allowing controlled cross-attention (e.g., with compressed tokens) are not studied.
- Compression fidelity and adaptivity are unexamined: information loss in compressed tokens is not quantified, especially for small, thin, or detail-critical components; no content-adaptive σ or per-component compression policy.
- Gating design space is narrow: importance scores multiply keys; alternatives (e.g., attention logit biasing, query scaling, explicit sparse attention masks, learned gates per head) are not explored or compared for stability and performance.
- Training–inference routing mismatch remains unquantified: stochastic routing during training and deterministic routing at test time may induce distribution shift; no study on temperature, sampling strategy, or calibration to mitigate mismatch.
- Evaluation lacks compositional metrics: only scene/object CD, F-score, and self-IoU are reported; no part-level correspondence metrics, semantic correctness, per-component placement/orientation errors, collision/contact quality, or layout consistency with the input image.
- Real-world generalization is only qualitative: no quantitative tests on real images (objects or scenes), nor robustness analyses across lighting, clutter, occlusion, and camera/view variations.
- Materials and textures are unsupported: MoCA focuses on geometry; per-component materials, textures, and appearance control (claimed as a motivation) are not modeled or evaluated.
- Frozen vecset VAE is a bottleneck: acknowledged limitation for small-volume parts; no experiments on component-level fine-tuning, higher-resolution latents, multi-scale decoders, or alternative decoders to improve reconstruction of tiny components.
- Cross-representation generality is unproven: MoCA is demonstrated on vecset latents; applicability to sparse voxel latent spaces (e.g., Trellis/SPARC3D) and comparative benefits are not evaluated.
- Scene-scale layout accuracy lacks measurement: no explicit metrics for 3D layout (e.g., per-instance translation/rotation errors, inter-object distances, contact correctness) relative to the conditioning image/layout.
- Duplicate/near-identical components not analyzed: risk of generating redundant instances or confusing identities (noted in baselines) is not systematically tested under MoCA, especially without masks.
- Dataset scope and bias: training/evaluation are primarily indoor scenes and curated object sets; generalization to outdoor, highly cluttered, or open-world categories is not assessed.
- Multi-modal control is unexplored: text prompts, symbolic/layout graphs, or constraints for compositional editing and placement are not integrated or evaluated.
- Assembly quality and physical plausibility are unmeasured: seam alignment, watertightness, gaps/overlaps between parts, and plausible contacts/joints are not quantified beyond self-IoU.
- Mesh quality/topology consistency not evaluated: effects of Marching Cubes on artifacts, topology errors, and cross-part consistency are not reported.
- Guidance and conditioning schedules lack analysis: classifier-free guidance is used (10% drop rate), but the effect of guidance scale and schedule on compositional fidelity and geometry is not studied.
- Anchor token design is under-specified: no evaluation of the number/structure of learnable queries and anchors, nor integration of explicit geometric features (e.g., component centroids/bboxes) to improve routing accuracy.
- Systems-level scaling strategies are absent: no discussion of distributed attention/sharding, memory-optimized kernels (e.g., flash attention variants), or pipeline-parallel strategies to push N much higher.
Practical Applications
Practical Applications of MoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
MoCA introduces two core innovations—importance-based component routing and compression of less important components—that significantly reduce the quadratic costs of global attention in multi-component 3D generation. The method enables high-quality part-level object generation and instance-level scene synthesis from single images, scaling to 32 components per asset. Below are actionable real-world applications grounded in MoCA’s findings, methods, and demonstrated capabilities.
Immediate Applications
- Gaming and VFX (Software/Creative Industries): rapid, controllable 3D asset creation from concept art or single images — “MoCA Composer” plug-ins for Blender/Unreal that generate mesh assets with clean part decomposition, per-component materials, and targeted editing; leverages MoC attention for efficient multi-part modeling; Assumptions/Dependencies: access to robust vecset decoder and iso-surface extraction (e.g., Marching Cubes), integration with DCC toolchains, sufficient GPU memory for up to 32 components.
- AR/VR Interior Design (Real Estate/Design): instance-composed scene generation from a single room photo with instance masks — “Scene-from-Photo Layout” workflow that produces aligned furniture objects and layout consistent with the image; uses instance mask conditioning (e.g., SAM 2) and MoCA’s sparse global attention; Assumptions/Dependencies: quality of instance segmentation masks, handling occlusions and clutter, glTF/FBX export compatibility.
- E-commerce Product Configurators (Retail/Marketing): customizable 3D products at part granularity — per-component materials, variants, and add-ons generated from catalog photos for web viewers; efficient compositional modeling supports scalable SKU variants; Assumptions/Dependencies: product-specific priors/templates, material mapping pipeline, IP/licensing for model generation.
- Robotics Simulation and Synthetic Data (Robotics): part-aware assets and multi-object scenes for grasping, assembly, and manipulation training — “Robotics Dataset Factory” generating physically plausible components and layouts for sim; MoCA’s compositionality aids instance-level annotations and geometry quality; Assumptions/Dependencies: physics engines integration (e.g., Isaac/Unity), domain randomization, accuracy of part semantics.
- CAD Pre-visualization (Manufacturing/CAD): rapid concept meshes with editable parts — “CAD Co-Design Assist” where designers import an image and obtain part-level prototypes for iteration, assembly planning, or PCB/mechanical placement visualization; Assumptions/Dependencies: tolerance and fit not guaranteed, downstream parametric conversion required; VAE finetuning on domain parts recommended.
- 3D Printing (Maker/Hobby/Consumer): printable replacements and props — generate part-separated meshes from photos for customization and material assignment; Assumptions/Dependencies: scale calibration, mesh watertightness, structural integrity checks.
- Education (Education/Training): interactive learning on 3D decomposition, assembly, and articulation — classroom tools that visualize part hierarchies and enable component-level editing; Assumptions/Dependencies: curated curricula, age-appropriate datasets, simple UI for novice users.
- Real Estate Marketing (Real Estate/Media): quick virtual staging and layout adjustments from photos — consistent instance placement and improved geometry for marketing visuals and AR previews; Assumptions/Dependencies: mask generation accuracy, material realism, alignment to camera intrinsics.
- Digital Twins (Facilities/IoT): small-space asset generation and layout capture from images — part-level components aid targeted maintenance simulations and annotation; Assumptions/Dependencies: interoperability with BIM/IFC via mesh-to-BIM workflows, material/semantic mapping.
- Research Tooling (Academia): testbed for compositional generative modeling — reusable MoC attention blocks for long-context attention studies; benchmark pipelines for part-aware evaluation metrics (CD, F-score, self-IoU) and ablation protocols; Assumptions/Dependencies: access to MoCA code and weights, domain-specific datasets.
- Compute/Cost Efficiency Guidance (Policy/IT Procurement): selection of energy-efficient generative pipelines — MoCA’s sparse attention reduces compute vs. naive global attention; immediate impact on internal model selection and budgeting; Assumptions/Dependencies: verification of energy savings at data center scale, monitoring frameworks.
Long-Term Applications
- End-to-end Perception-to-Manipulation (Robotics): real-time, part-aware generation for planning grasps, assembly, and tool use — closed-loop systems that decompose objects on-the-fly for manipulation; relies on MoCA’s routing/compression scaled beyond 32 components; Assumptions/Dependencies: hard real-time performance, physics-informed generation, robust domain adaptation to real-world sensors.
- Autonomous Warehousing and Logistics (Robotics/Industrial Software): large-scale scene synthesis and layout optimization (>100 instances) for motion planning and simulation — generative “Warehouse Layout Co-Pilot” that creates compositional scenes at scale; Assumptions/Dependencies: scaling MoC attention (k, σ) and memory efficiency, instance mask automation, integration with WMS and simulation platforms.
- Generative Design Co-Pilot (Manufacturing/CAD): parametric part generation with constraints, materials, and optimization — compositional 3D generation guided by engineering rules and optimization loops; Assumptions/Dependencies: physics/material models, CAD parametric conversion, certification and QA pipelines.
- Medical Device and Prosthetics Prototyping (Healthcare): domain-specific, part-aware modeling of devices and anatomical components — personalized prosthetic parts generated from patient imagery with controllable sub-components; Assumptions/Dependencies: medical datasets, clinical validation, regulatory compliance (FDA/CE), strict dimensional accuracy.
- Building Energy and Sustainability Analysis (Energy/Built Environment): auto-generation of BIM-like models from photos for thermal and daylighting simulations — “Photo-to-BIM” compositional pipeline enabling energy audits and retrofits; Assumptions/Dependencies: conversion to IFC with materials and assemblies, calibrated camera and scale, domain-specific finetuning.
- Urban Planning and Digital Cities (Public Sector/Policy/Urban Design): generation of city block scenes for planning scenarios and pedestrian/traffic simulations — instance-composed environments with semantic components; Assumptions/Dependencies: GIS integration, large-scale compositionality, regulatory datasets, stakeholder review.
- Insurance and Claims Processing (Finance/InsurTech): 3D scene reconstruction with component-level damage assessment from images — faster triage and estimates via decomposed assets; Assumptions/Dependencies: accuracy thresholds, fraud detection, privacy/security controls, auditor acceptance.
- Standards and Governance for Compositional 3D Assets (Policy/Standards): metadata schemas for part identities, licensing, and interchange — guidelines for component-aware 3D assets (materials, provenance, usage rights); Assumptions/Dependencies: multi-stakeholder coordination, alignment with existing standards (glTF, USD, IFC).
- Open 3D Marketplaces (Software/Creative Economy): dynamic asset bundling and per-component licensing — marketplaces that trade reusable components and layouts; Assumptions/Dependencies: IP frameworks for parts, provenance tracking, quality assurance.
- Cross-Domain Attention Efficiency (Software/ML Systems): generalization of MoC attention to other long-context generative tasks (video, multimodal robotics, CAD graphs) — “MoC-Attn” libraries for sparse, routed attention with compression; Assumptions/Dependencies: robust implementations, tuning of k and σ for each domain, evaluation suites to measure tradeoffs.
- Education at Scale (Education/Public Sector): 3D interactive textbooks and labs — generated experiments, assemblies, and scenes supporting STEM education; Assumptions/Dependencies: pedagogical validation, content moderation, accessibility requirements.
Notes on Assumptions and Dependencies Affecting Feasibility
- Model requirements: access to MoCA weights or retraining on domain-specific datasets; high-quality conditioning images; instance masks (for scenes) via tools like SAM/SAM 2.
- Technical constraints: vecset VAE is currently frozen (paper’s limitation); fine-tuning on component-level data may be necessary for small-volume components and precise reconstructions; mesh extraction (e.g., Marching Cubes) quality impacts downstream workflows.
- Scaling: current demonstrated scale is up to 32 components; long-term applications often require scaling beyond that through additional research and optimization of k (top-k routing) and σ (compression ratio).
- Integration: success depends on interoperability with DCC tools (Blender, Unreal), CAD/BIM standards (IFC/USD/glTF), physics engines, and data pipelines for materials, semantics, and measurements.
- Reliability and safety: for regulated domains (healthcare, finance/insurance), require accuracy, validation, auditability, and adherence to compliance standards; ethical use and IP/licensing considerations for generated assets.
- Compute and cost: while MoCA reduces attention costs, deployment still requires adequate GPU resources; enterprise policy adoption may need empirical energy and cost benchmarking.
Glossary
- Anchor token: A learnable token that aggregates a component’s features into a single representation used for component-level operations. Example: "the anchor token of "
- Chamfer Distance (CD): A point-set distance metric that measures how closely two surfaces match by averaging nearest-neighbor distances between points. Example: "Chamfer Distance (CD)"
- Classifier-free guidance: A diffusion training/inference strategy that stochastically drops conditioning to enable guided sampling at test time. Example: "classifier-free guidance"
- Component-level attention: An attention mechanism that operates at the granularity of entire components rather than individual tokens. Example: "component-level attention-like manner."
- Cross-attention: An attention mechanism where query tokens attend to key/value tokens from another set to aggregate information. Example: "a cross-attention layer"
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion models to process sequences/tokens during generation. Example: "3D diffusion transformer (DiT) models"
- Farthest Point Sampling (FPS): A downsampling technique that iteratively selects the farthest points to preserve coverage of a point set. Example: "farthest point sampling (FPS)"
- F-score: The harmonic mean of precision and recall used to evaluate geometric alignment at specified distance thresholds. Example: "F-score"
- Gating factors: Scalar weights applied to modulate contributions (e.g., keys) of different components within attention. Example: "gating factors"
- Global attention: Attention computed across all tokens/components jointly to model long-range dependencies. Example: "global attention"
- Implicit field: A continuous function (learned by the decoder) from which occupancy or signed distance values can be queried for any 3D point. Example: "an implicit field"
- Importance-based component routing: A mechanism that selects the top-k most relevant components for detailed attention based on learned importance scores. Example: "importance-based component routing"
- Instance masks: Per-object segmentation masks used as auxiliary conditioning to guide instance-level scene generation. Example: "per-instance masks"
- Iso-surface extraction: The process of extracting a mesh surface as the level set of an implicit field (e.g., occupancy or SDF). Example: "iso-surface extraction step"
- Latent diffusion models (LDMs): Diffusion models that operate in a learned latent space rather than directly in pixel or voxel space. Example: "latent diffusion models (LDMs)"
- Load balance: Ensuring routed components (or experts) are utilized evenly during training to avoid collapse and improve diversity. Example: "Load Balance Consideration"
- Marching Cubes: A classic algorithm that converts volumetric scalar fields into triangle meshes by tracing iso-surfaces. Example: "Marching Cubes"
- Mixture-of-Components Attention (MoC): An attention scheme where each component attends to full tokens of important components and compressed tokens of less important ones. Example: "Mixture-of-Components Attention"
- Mixture-of-Experts (MoE): An architecture using multiple specialized experts with a router to select which experts are activated per input. Example: "MoE (Mixture-of-Experts) models"
- Multi-Head Routing: Performing routing decisions independently across attention heads to capture diverse inter-component dependencies. Example: "Multi-Head Routing."
- Occupancy or SDF fields: Implicit shape representations as occupancy probabilities or signed distance functions queried from latents. Example: "implicit occupancy or SDF fields"
- Permutation-invariant: A property where the output does not depend on the ordering of components or tokens. Example: "permutation-invariant across all components."
- Rectified flow matching: A training objective that predicts the velocity connecting noisy and clean latents along a linear trajectory. Example: "rectified flow matching objective"
- Router module: A lightweight network that estimates component importance and decides whether to use full or compressed tokens. Example: "a router module"
- Self-IoU: An intersection-over-union measure assessing overlaps between generated parts within the same object. Example: "self-IoU"
- Sparse voxels: A structured latent representation that stores only non-empty voxels to capture fine-grained geometry efficiently. Example: "sparse voxels."
- Vecset: An unordered set of latent vectors representing a 3D shape in the encoder/decoder pipeline. Example: "vecset latents"
- Vecset diffusion models: Latent diffusion models trained to generate unordered sets of vectors that implicitly encode 3D shapes. Example: "Vecset diffusion models"
- Vecset VAE: A variational autoencoder that encodes point sets into vecset latents and decodes them into implicit fields. Example: "The vecset VAE"
Collections
Sign up for free to add this paper to one or more collections.