- The paper introduces a multimodal approach that combines visual inputs from Resnet-50 and textual analysis via PolyLDA to enhance product assortment curation.
- The methodology models assortment generation as a quadratic knapsack problem, yielding a 10.9% improvement in click-through rates during A/B testing.
- The system effectively simulates a curated showroom experience online, leveraging deep learning and topic modeling to ensure stylistic coherence across products.
A Multimodal Recommender System for Large-scale Assortment Generation in E-commerce
Introduction
This paper presents a multimodal recommender system designed to enhance assortment generation for e-commerce platforms, specifically focusing on categories like furniture where visual aesthetics are paramount. The proposed system integrates both visual and textual data to curate assortments, ensuring stylistic compatibility and coherence. This dual-modality approach aims to mimic the curated experience of physical showrooms digitally, offering consumers an enriched shopping experience.

Figure 1: An automatically generated assortment from the multimodal approach is shown.
System Architecture and Methodology
The system architecture utilizes product images and textual descriptions to form a holistic model that combines deep neural networks and advanced topic modeling techniques. This sophisticated pipeline begins by processing raw data through a Hadoop cluster, subsequently utilizing Resnet-50 for visual data processing and Mallet for topic modeling. The training primarily occurs on a GPU server, applying both transfer learning for visual semantic extraction and Polylingual Topic Modeling to interpret multimodal datasets.
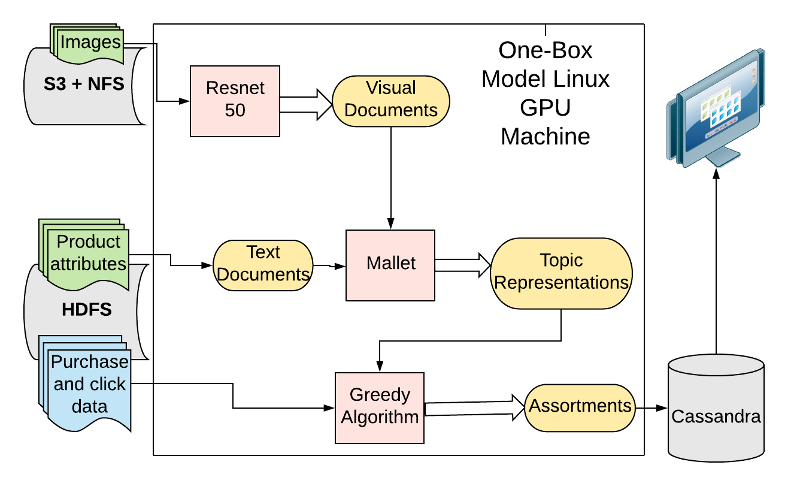
Figure 2: A system overview diagram is presented above. We use product data and user engagement data residing within our Hadoop cluster and our NFS/S3 store to train the model. Most of the training is done on a one box GPU server, which runs the {\tt Resnet-50.
The methodology leverages the transfer learning capabilities of Resnet-50 to extract meaningful visual features that represent style, creating bag-of-visual-words (BoVW) documents. Textual data is processed to remove stopwords and form text documents. These documents are then coupled as tuples for ingestion by PolyLDA, a flexible multimodal topic modeling approach that handles loosely equivalent documents in different languages.

Figure 3: Here we depict activations from the layers used to create our visual documents. The leftmost column is the raw image. The next column to the right is the cropped patch which is passed through the network. In the next 4 columns, we see the response to these patches from 9 channels each of convolutional layers 8, 18, 31 and 43.
Assortment Generation as a Quadratic Knapsack Problem
The assortment generation process is modeled as a 0-1 Quadratic Knapsack Problem (QKP), incorporating budget constraints and pairwise compatibility metrics derived from implicit user feedback. The model initializes with seed items, optimizing the selection process through Mahalanobis distance measures based on purchase data to score and refine the assortments. This approach enables the system to curate collections that are visually cohesive and stylistically diverse.
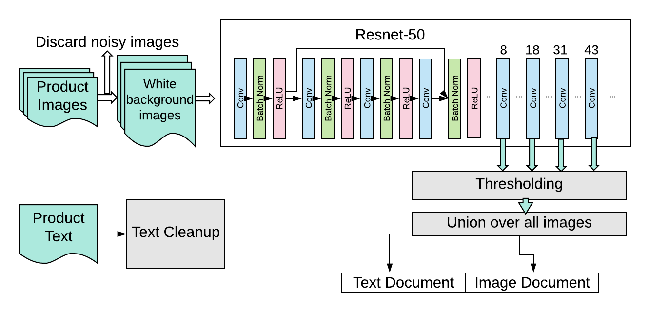
Figure 4: Each product's corresponding text and images are collected. Our system then discards images with noisy scenes, keeping only those with white backgrounds and passing them through {\tt Resnet-50.
Results and Discussion
The proposed system underwent rigorous offline and online evaluations. In an extensive A/B test conducted on Overstock’s platform, the multimodal system demonstrated a statistically significant improvement, with a 10.9% increase in click-through rates compared to the visual-only variant. Offline validations computed the Jaccard coefficient for product compatibility, confirming that the multimodal system achieves superior assortment coherence.
The results indicate the multimodal variant’s ability to generate assortments with a balanced mix of styles, thereby enhancing the user experience by preventing oversaturation with visually similar products. These findings underscore the advantages of leveraging both visual and textual data in recommender systems, facilitating more informed and stylistically diverse product recommendations.
Conclusion
The introduction of a multimodal approach for e-commerce assortment recommendations marks a significant advance in the capacity to simulate the curated showroom experience online. By utilizing both visual and text data, the system can effectively discern and apply style compatibility across products, offering nuanced and cohesive collections that better meet consumer preferences.
This paper concludes that integrating multimodal data not only refines the aesthetic coherence of product assortments but also significantly enhances consumer interaction metrics. The approach exhibits potential for application beyond the immediate scope, extending to various domains where product presentation and compatibility are crucial. Future developments could explore the scalability of this approach across different e-commerce sectors and refine the model for improved personalization.