- The paper presents the TMF framework that integrates visual, textual, and graph data using LLMs to create unified user behavior representations.
- It employs all-modality self-attention and cross-modality attention mechanisms to dynamically weigh features and optimize recommendation accuracy.
- Experiments on Electronics, Sports, and Pets datasets demonstrate significant improvements in HitRate@1 compared to conventional models.
Aligning Visual, Textual, and Graph Data with LLMs for Multi-Behavior Recommendations
Introduction
The integration of diverse data modalities holds the potential for substantially enhancing personalized recommendation systems, which have traditionally depended upon singular data sources. In this context, the research introduces the concept of Triple Modality Fusion (TMF), leveraging visual, textual, and graph data aligned with LLMs. By encompassing sensory-rich visual information, detailed textual data, and complex relational graph data, TMF strives to refine user behavior representations and improve recommendation accuracy.
The primary contribution of this paper is the introduction of the TMF framework, which capitalizes on the sophisticated modeling capabilities of LLMs to align and integrate multimodal data, thus providing a comprehensive representation of user interactions. The innovation lies in the deployment of modality fusion mechanisms—chiefly cross-attention and self-attention—and the design of specialized prompts for LLMs to simulate natural language-based interactions, offering a significant optimization over existing models.
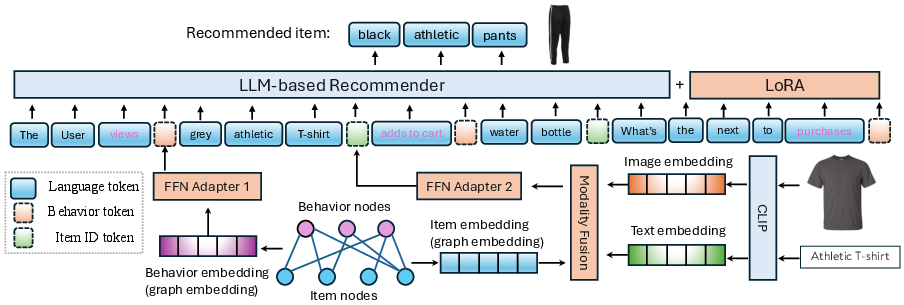
Figure 1: The Triple Modality Fusion (TMF) framework for multi-behavior recommendation. The blue squares are frozen models, and the red models are open to training in the training steps.
Methodology
Triple Modality Alignment
TMF employs a fusion of multimodal data sources: images offer contextual and aesthetic insights, text reveals user interest and item detail, and graph data unravels relationships within item-behavior graph structures. Through LLMs, these modalities are unified in an embedding space to enable holistic modeling of recommendation tasks. The integration utilizes pre-trained encoders for each modality, facilitating efficient generation of representations for further processing in LLMs.
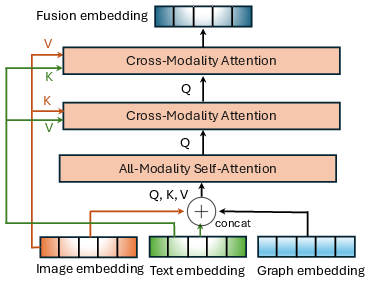
Figure 2: The Modality Fusion module.
All-Modality Self-Attention and Cross-Modality Attention
The fusion process is particularly sophisticated, relying on self-attention and cross-modality attention mechanisms. In the all-modality self-attention (AMSA) layer, the embeddings from different modalities of an item are combined to form a unified representation. Each item sequence is then weighted dynamically, ensuring the nuanced importance of modalities is captured.
Further, the cross-modality attention (CMA) layers enhance the model’s comprehension by contrasting visual and textual representations. Initially, the output of AMSA is conditioned on the visual and textual features to draw rich contextual cues, which are then refined through successive attention layers, ensuring the contextual richness is retained across decision-making processes.

Figure 3: Task complexity and prompt examples.
Implementation and Experiments
Instruction Tuning and Parameter Efficiency
The TMF utilizes instruction tuning to adapt LLMs to the task of multi-modal recommendation, enhancing specificity with instruction prompts. A fine-tuning strategy is adopted using LoRA (Low-Rank Adaptation), which efficiently tunes the model parameters via low-rank matrix updates, significantly reducing computational overhead.
The effectiveness of the TMF framework is thoroughly tested against conventional sequence-based and graph-based models, as well as leading LLMs like LLaRA and Llama-2. Results display notable improvements in HitRate@1, a metric assessing recommendation accuracy across varying datasets—specifically Electronics, Sports, and Pets—demonstrating superior performance in complex user-item interaction scenarios.

Figure 4: Case Study on Sports and Electronics datasets to demonstrate the TMF's capacity on context understanding (shopping topics, user age and gender requirement, design, etc.) and reasoning for next purchase prediction.
Conclusions
The TMF framework innovatively integrates triple modalities into the field of recommendation systems using LLMs as a conduit for advanced multi-behavior insight generation. Through strategic employment of advanced model tuning and multi-level attention mechanisms, TMF illustrates significant leaps in recommendation accuracy and relevance, adaptable to a variety of datasets with intricate user behavior patterns. Future research directions might involve further optimization of modality alignment techniques and exploring additional fusion strategies to cater to even more complex data environments.
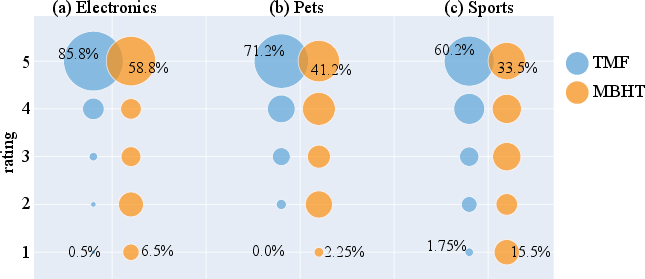
Figure 5: Distribution of Human Rating Scores in a bubble chart.

