- The paper introduces a soft weight-sharing method that leverages a Gaussian Mixture Model to cluster and compress neural network weights.
- It combines quantization and pruning in a single retraining phase, achieving compression ratios up to 162x while maintaining near-original accuracy.
- The approach aligns with the Minimum Description Length principle, offering a scalable solution for deploying models on resource-constrained devices.
Soft Weight-Sharing for Neural Network Compression
Introduction
The paper "Soft Weight-Sharing for Neural Network Compression" addresses the challenge of compressing neural networks for deployment on devices with limited computational resources, such as mobile devices. The authors propose a compression method based on "soft weight-sharing," which simultaneously achieves quantization and pruning through a single retraining procedure. This approach leverages a mixture of Gaussians to cluster neural network weights, effectively reducing the precision and count of stored weights.
Method and Implementation
The central innovation in this work is the use of a Gaussian Mixture Model (GMM) as a prior distribution over the network weights. This method encourages the clustering of weights into groups defined by the Gaussian components, thereby reducing the effective number of unique weight values that need to be stored. The prior is adapted through empirical Bayes, with the GMM parameters being learned alongside network retraining. The objective function combines the prediction error with a compression loss term weighted by a factor τ.
The network weights are initialized using pretrained models, and the GMM is initially configured with 17 components. Notably, one component is fixed at zero to encourage sparsity (weight pruning), aligning the optimization process with the Minimum Description Length (MDL) principle.
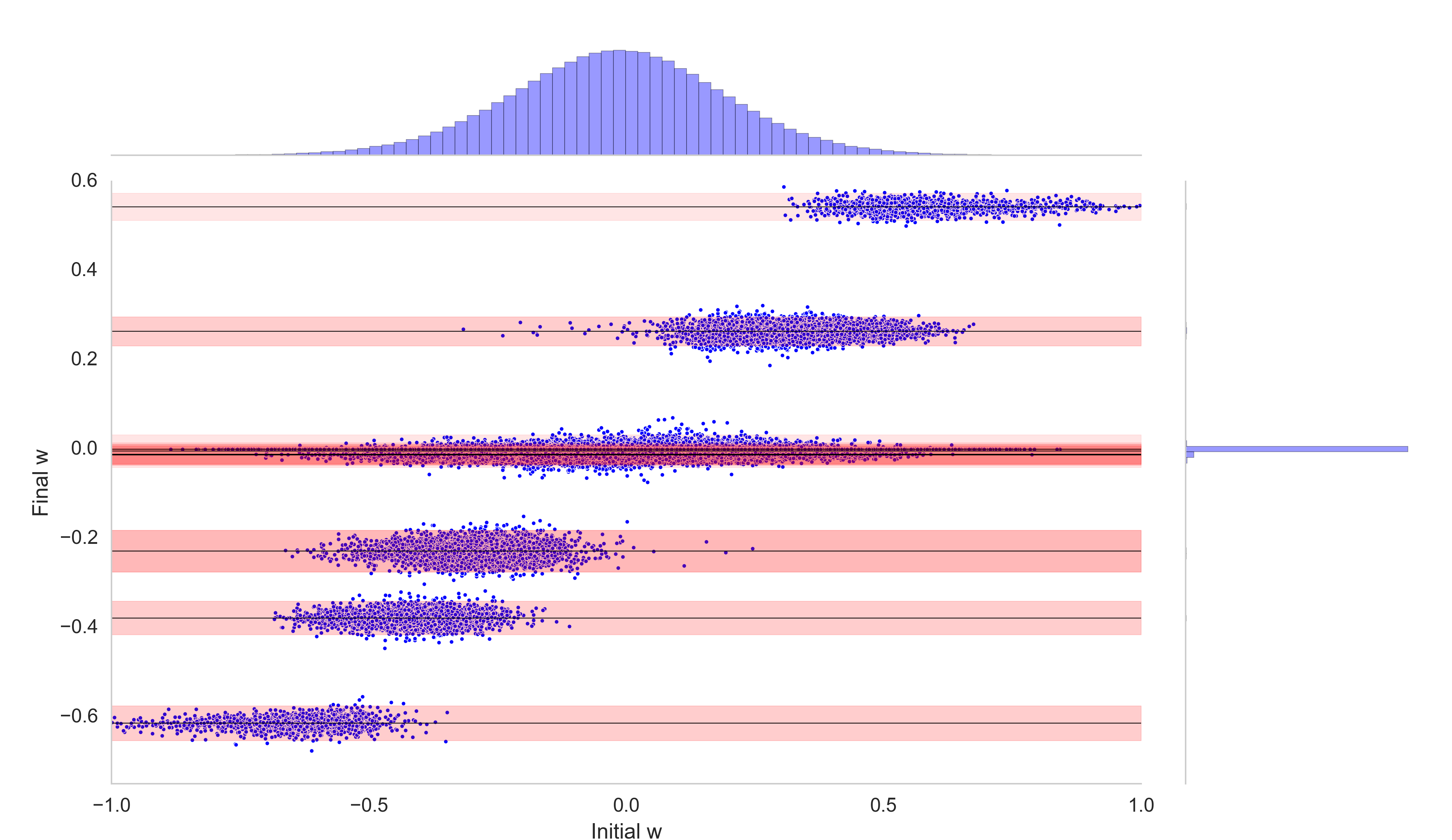
Figure 1: On top we show the distribution of a pretrained network. On the right the same distribution after retraining. The change in value of each weight is illustrated by a scatter plot.
Experimental Results
The proposed method was evaluated on widely-used neural network models, including LeNet-300-100 and LeNet-5-Caffe for the MNIST dataset, as well as a ResNet variant for CIFAR data. For compression evaluation, a combination of pruning and quantization is applied, post-processing the trained models to map weights to their corresponding Gaussian component means.
The paper reports compression ratios of 64.2x for LeNet-300-100 and 162x for LeNet-5-Caffe, effectively maintaining network accuracy near original levels (1.89% to 1.94% error rate for LeNet-300-100 and 0.88% to 0.97% for LeNet-5-Caffe). These results are competitive with other state-of-the-art compression schemes, while providing a unified framework for both pruning and quantization.
Scalability Considerations
Implementing soft weight-sharing in very large models can be computationally intensive due to the need to recompute weight assignments constantly. The authors propose subsampling the weights for the gradient calculation of the prior to alleviate computational costs, particularly advantageous in large-scale networks such as VGG or extensive ResNet variants.
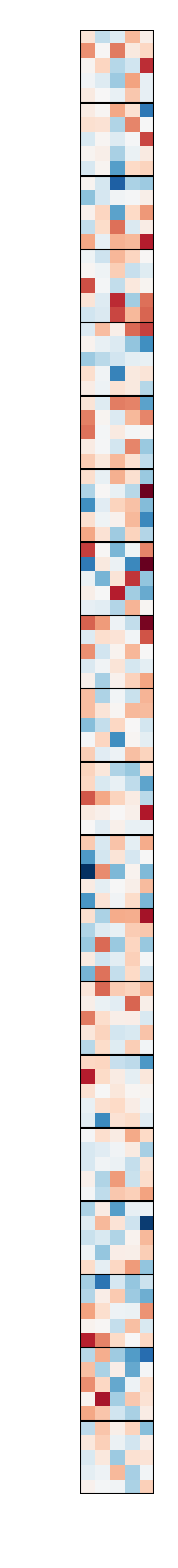
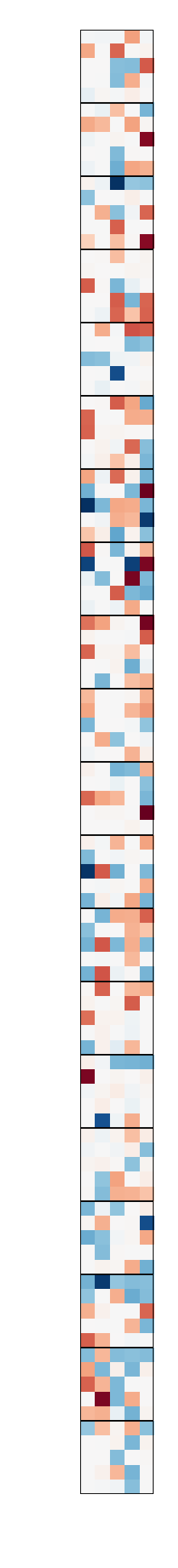


Figure 2: Convolution filters from LeNet-5-Caffe. Left: Pre-trained filters. Right: Compressed filters. The top filters are the 20 first layer convolution weights; the bottom filters are the 20 by 50 convolution weights of the second layer.
Implications and Future Work
The implications of this research are significant for the efficient deployment of neural networks in resource-constrained environments. By aligning network training with the MDL principle, this framework potentially improves not just storage efficiency but also computational efficiency, aiding on-device inferencing.
Future investigations may include integrating soft weight-sharing with advanced resource formats or considering alternative statistical models for the prior, such as structured sparsity inducing priors, to explore potential improvements in both compression rates and computational demands.
Conclusion
The paper "Soft Weight-Sharing for Neural Network Compression" contributes a straightforward yet effective method for neural network compression that merges quantization and pruning into a single retraining phase. By operating under the MDL principle, this approach provides state-of-the-art compression outcomes without critical accuracy loss, paving the way for more practical deployment of deep learning models in limited-resource environments.