iGniter: Taming GPU Interference for Predictable Cloud Inference
This presentation explores iGniter, a breakthrough system that solves a critical bottleneck in cloud-based deep learning inference: performance interference when multiple models share the same GPU. By predicting and proactively mitigating contention, iGniter maintains strict service level objectives while cutting costs by up to 25% compared to existing approaches, demonstrating that intelligent resource provisioning can transform GPU efficiency in production environments.Script
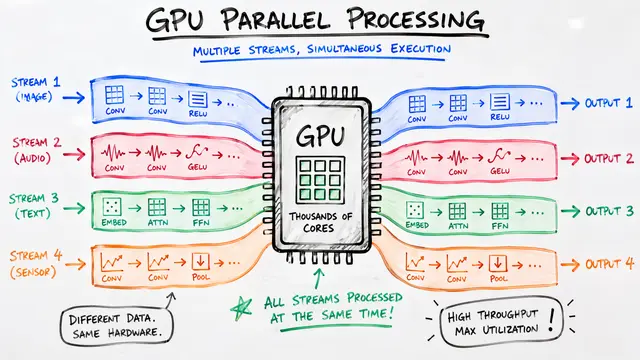
When multiple deep learning models share a single GPU in the cloud, they don't play nice. Contention between workloads creates performance interference that violates service level objectives and wastes money, yet current provisioning strategies either react too late or ignore the problem entirely.
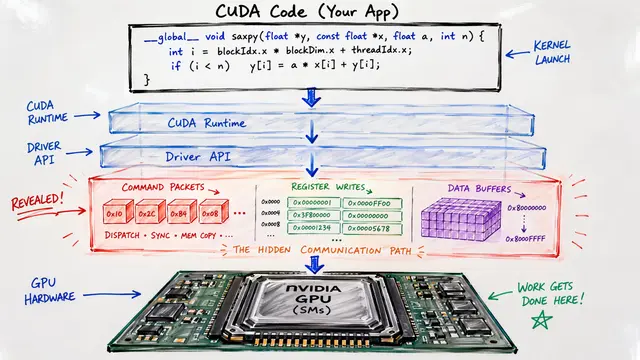
The authors built iGniter around two core components: a lightweight performance model that predicts interference before it happens, and a provisioning strategy that allocates GPU resources and configures batching to prevent contention proactively.
Here's how it works. The performance model analyzes system and workload metrics to forecast interference effects, then guides resource allocation decisions. By configuring dynamic batching and partitioning GPU capacity based on these predictions, iGniter prevents interference instead of scrambling to fix it after service levels degrade.
The researchers tested iGniter on Amazon EC2 using V100 GPUs and production models including ResNet-50 and AlexNet. Against existing strategies like FFD, GSLICE, and gpu-lets, iGniter maintained service level objectives while cutting costs by up to 25 percent.
The results depend on the specific models and datasets tested. The real frontier lies in extending this approach to heterogeneous GPU architectures and hybrid workloads that mix training and inference, where interference patterns grow even more complex.
Proactive interference management transforms how we provision cloud resources for deep learning. If you want to explore how prediction beats reaction in GPU scheduling, visit EmergentMind.com to dive deeper into iGniter and create your own explanatory videos.