- The paper introduces a human-in-the-loop framework that uses atomic nugget annotations to ensure precise and accountable LLM evaluations.
- The paper details an iterative process of curation, calibration, and analysis that mitigates biases such as anchoring and criteria drift.
- The evaluation protocol enables live feedback, transparent quality control, and error correction by linking human judgments to LLM output matching.
Human-in-the-Loop Nugget Annotation for Accountable LLM-as-a-Judge Evaluations
Motivation and Background
The increasing deployment of LLM-as-a-Judge paradigms in information access evaluation and system comparison has accentuated the need for robust accountability schemes that control for circularity, anchoring, and criteria drift. Empirical evidence demonstrates that naïve applications—where LLMs both generate and evaluate outputs—exhibit problematic bias, self-preferential behavior, and a lack of reliable agreement with domain experts (2606.29033). Human experts, while essential, are vulnerable to anchoring (rubber-stamp effect) and inconsistency in high-variance annotation tasks.
Automating evaluation with LLMs without precise human oversight or deploying raw holistic scoring by humans each have critical weaknesses. This work formalizes a division of labor where humans specify what information is essential—via atomic, verifiable “nuggets”—while LLMs are restricted to high-throughput, verifiable matching against these criteria. This architecture aims to combine human judgmental authority with the scalability and repeatability of LLM-based matching.
System and Workflow Design
The annotation prototype and workflow are explicitly constructed in three iterative phases: curation, calibration, and analysis. In the first phase, the human expert reads system outputs and identifies critical information items—nuggets—by selection of text spans and the provision of intent-focused free-text annotations. This is strictly performed prior to any LLM support, preserving the independence of human conceptualization.
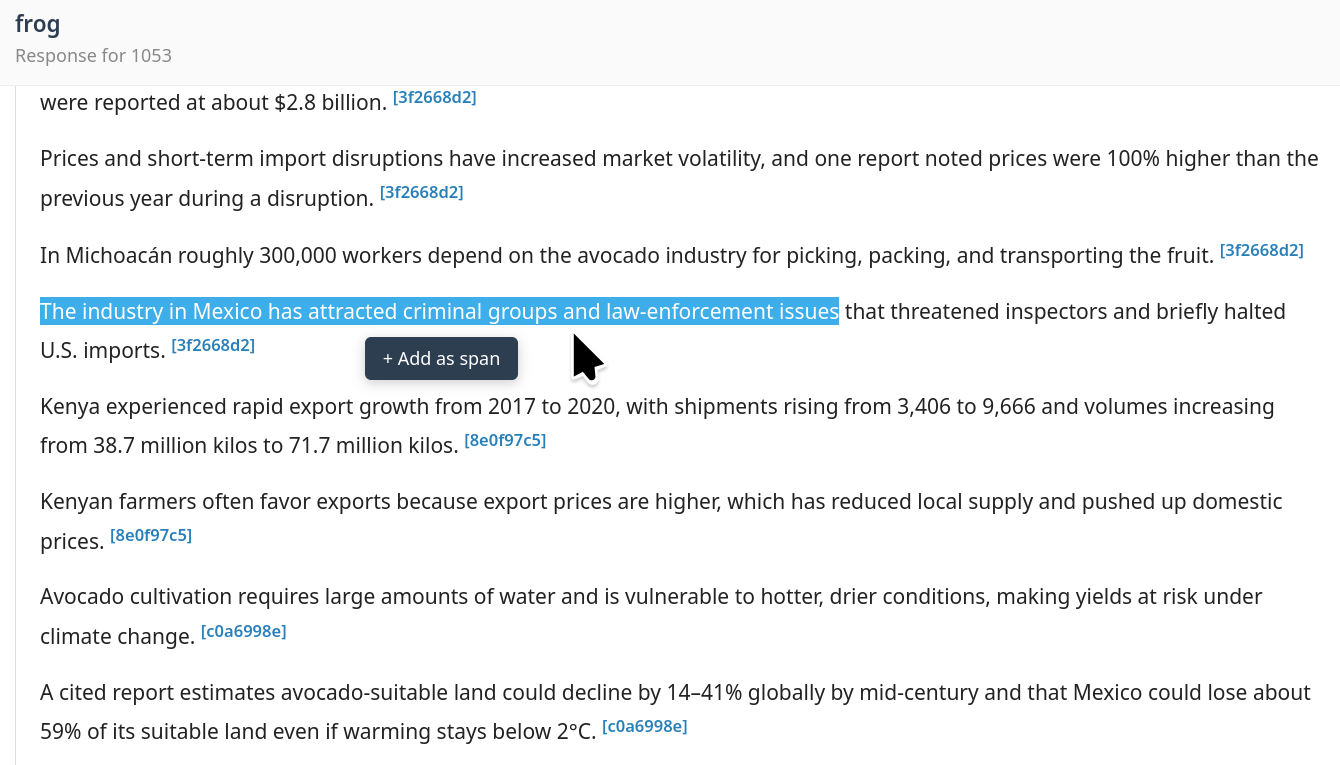
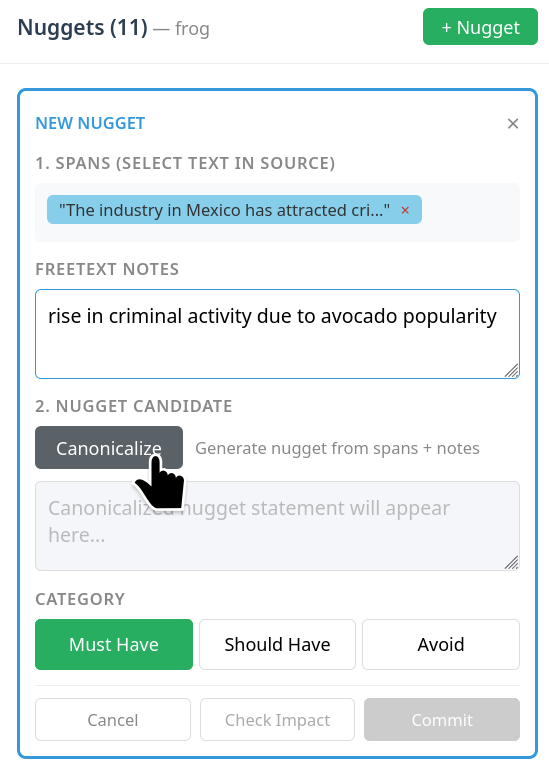
Figure 1: Human experts ground nugget curation by selecting key spans and attaching free-text notes before LLM involvement.
Once nuggets are selected, the LLM can assist in formalizing these free-form human inputs into canonical, atomic, and task-aligned questions or statements. However, the LLM is prohibited from proposing content, ensuring all evaluation criteria are strictly traceable to explicit human actions.
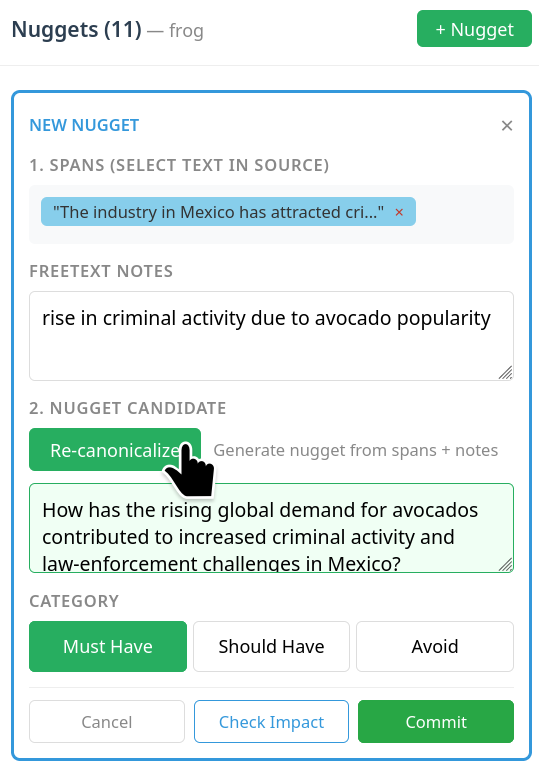
Figure 2: After "Canonicalize," the LLM synthesizes a formal nugget based on human-selected evidence and the task context, subject to further human editing.
The annotator then assesses and assigns each nugget to categories—Must Have, Should Have, or Avoid—reflecting its importance in downstream scoring. The finalized nugget bank forms the set of explicit evaluation criteria for subsequent automated matching.
Feedback-Driven Nugget Calibration
A core innovation is the “Check Impact” feature, establishing a live feedback loop from nugget phrasing to its coverage across system outputs. When invoked, this feature determines, for each candidate nugget, how many and which system outputs would match under current wording, and presents contextual supporting evidence.
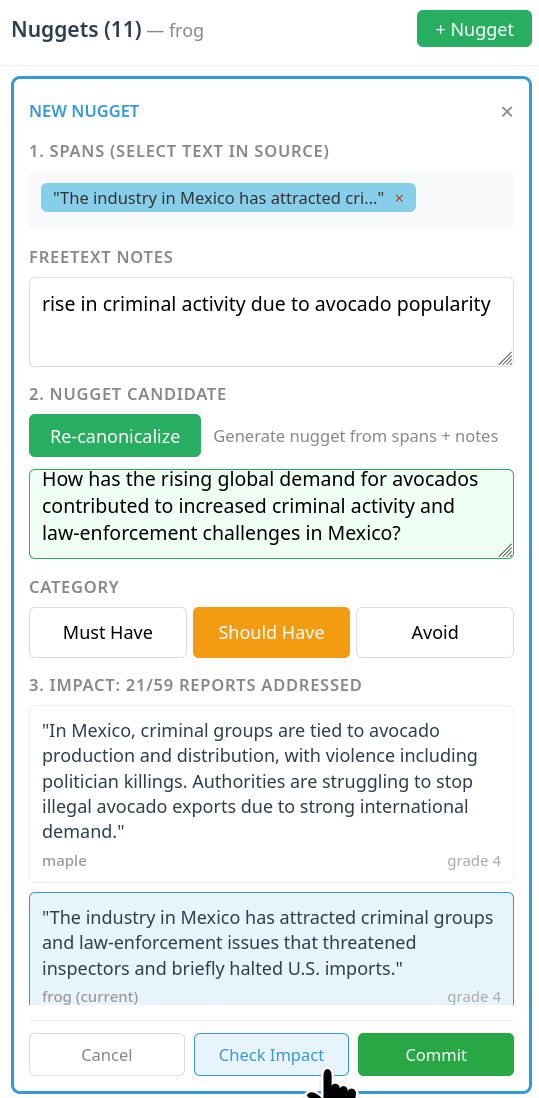
Figure 3: The "Check Impact" view previews which system responses match a nugget, guiding concise and discriminative nugget calibration.
This feedback enables immediate refinement to maximize discriminative power—avoiding both over-specificity (undermatched) and over-generality (uninformative). Human experts iteratively refine nugget text, observing coverage metrics and sampled matching outputs, to ensure granularity and verifiability.
This loop is essential in suppressing criteria drift: misworded or ambiguous nuggets are corrected during nugget creation, not post-hoc. Calibration at this stage ensures that the nugget bank remains interpretable and effective for downstream leaderboard construction and system differentiation.
Auditable Quality Control and Aggregated Reporting
The final phase exposes all scoring weightings, nugget contributions, and leaderboard constructions to the human expert, who can interactively adjust category weights, examine the impact of each nugget or category in isolation (“solo mode”), and disable nuggets to directly inspect their contributions. This enables robust hypothesis testing, error correction, and prevention of ranking artifacts driven by flawed or idiosyncratic nuggets.
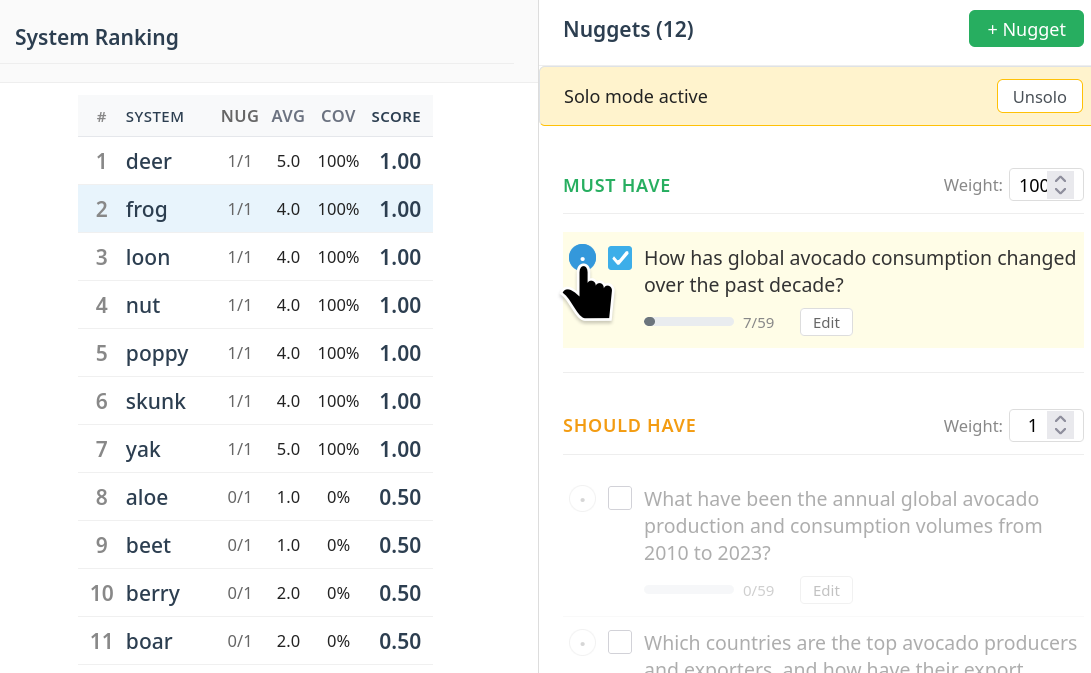
Figure 4: System ranking diagnostics visualize the marginal and aggregate impact of nuggets on leaderboard positions and quality partitioning.
This structured QC allows for differential emphasis (e.g., raising Must Have weight for critical omissions), manual correction of over-penalization or excessive leniency, and empirical validation that system rankings rationally reflect actual response quality.
Comparison to Alternative Evaluation Schemes
Two failure modes are explicitly addressed:
- Rubber-stamp/Anchoring bias: If human confirmation follows LLM “suggestions,” human judgment is susceptible to bias and reduced scrutiny, undermining genuine oversight.
- Black-box holistic scoring: Assigning a single score to complex outputs is cognitively taxing, inconsistent, and yields criteria drift, particularly as fatigue sets in over annotation campaigns.
Empirical studies confirm that default LLM-as-a-judge processes, including verification-based schemes, suffer from systematic anchoring [agudo2024impact, fok2024search]. Likewise, manual scoring without explicit criteria is error-prone and vulnerable to drift [shankar2024validates]. The nugget approach resolves these by enforcing human primacy in criteria generation and providing structured, auditable units for LLM matching.
Implications for Responsible AI Evaluation
The presented framework establishes a reproducible, transparent pathway for human-in-the-loop evaluation at scale, supporting repeatable leaderboards, regulatory compliance, and method comparison. All evaluation artifacts are strictly traceable to explicit human judgements, positioning this protocol as a strong accountability standard for future LLM, IR, and QA benchmarking.
Practical deployment enables:
- Fast, iterative refinement of evaluation criteria without discarding previous work
- Reasoned system diagnostics with error tracebacks to specific criteria
- Simultaneous reproducibility and adaptability in both academic and production settings
Theoretically, the work formalizes a reconciliation between crowdsourced/narrow-scope metrics and fully automated LLM ranking, potentially enabling more robust evaluation pipelines for multitask and zero-shot settings. It addresses salient critiques of “circular” LLM-based evaluation [dietz2026insider, clarke2025stillcant], mitigating self-bias and data contamination effects documented in recent literature [liu2024narcissistic, panickssery2024llm, li2025preference].
Future Directions
The method affords several avenues for future research, including joint refinement of nugget-based metrics, deeper automated nugget proposal (with strict human oversight), large-scale nugget bank aggregation across tasks and domains, and longitudinal tracking of nugget efficacy as LLMs and task requirements evolve. Integration with adversarial testing and cross-benchmarking frameworks will likely further stress-test the approach for robustness.
Conclusion
Human-in-the-loop nugget annotation, as detailed in this work (2606.29033), provides a robust, interpretable, and scalable solution to the deficiencies of current LLM-as-a-Judge methodologies. By assigning intellectual authority to human annotators for evaluation criterion formation and strictly constraining LLMs to verifiable, auditable matching, the architecture eliminates key sources of bias and drift in automated evaluation. This schema is positioned as a generalizable blueprint for accountable human-machine collaboration in AI evaluation and beyond.

