An Empirical Analysis of Factual Errors in Human-Written Text and its Application
Abstract: Factual Error Detection (FED), which is the task of identifying factually incorrect spans in a given text, has long been recognized as an important research problem. However, with the rapid rise of LLMs, research attention has shifted toward factual errors specific to LLM-generated text (hallucinations) and their detection. As a result, the detection of factual errors in human-written text has been relatively neglected. To address this gap, we first distill a taxonomy of human-induced factual errors by analyzing corrections of newspaper articles, a representative source of text that is guaranteed to be human-written and contains few grammatical errors. Our analysis revealed that there are characteristic categories such as kanji misconversions and numeral classifier errors, which are not focused in existing hallucination benchmarks. Based on the taxonomy, we then evaluate the FED capability of vanilla LLMs on synthesized realistic test cases and real corrections. Experimental results demonstrated that even high-performance LLMs such as GPT-5.4 achieved only word-level F1 score of 52% on the synthetic evaluation data, highlighting the task difficulty. Furthermore, a detailed analysis by detection difficulty revealed the current state of FED.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about finding factual mistakes in text written by people (like newspaper articles), not by AI. The authors study what kinds of real-life mistakes humans make (for example, wrong dates or wrong names) and test whether modern AI LLMs can spot those mistakes. They also build a way to create realistic “fake mistakes” so they can run fair, large tests.
What questions did the researchers ask?
- RQ1: What kinds of factual mistakes do humans commonly make in real writing?
- RQ2: How good are today’s LLMs at detecting those mistakes without looking things up on the internet?
How did they study it?
First, here are two important ideas in simple terms:
- Proofreading vs. revising: Proofreading fixes grammar and typos. Revising fixes factual mistakes (things that are not true, like “the event happened in 2020” when it actually happened in 2021). This paper focuses on revising, specifically on detecting the incorrect parts.
- “Hallucination” (in AI): When an AI makes up facts. Lots of research studies AI hallucinations. But this paper looks at human-made factual errors instead.
The researchers followed these steps:
1) Learn from real-world corrections
They collected “correction articles” from a major Japanese newspaper (Nikkei). These are official notes the newspaper publishes to admit and fix mistakes. Because the original articles are written and proofread by humans, these corrections mainly show factual errors, not grammar slips.
2) Build a simple “map” (taxonomy) of common mistake types
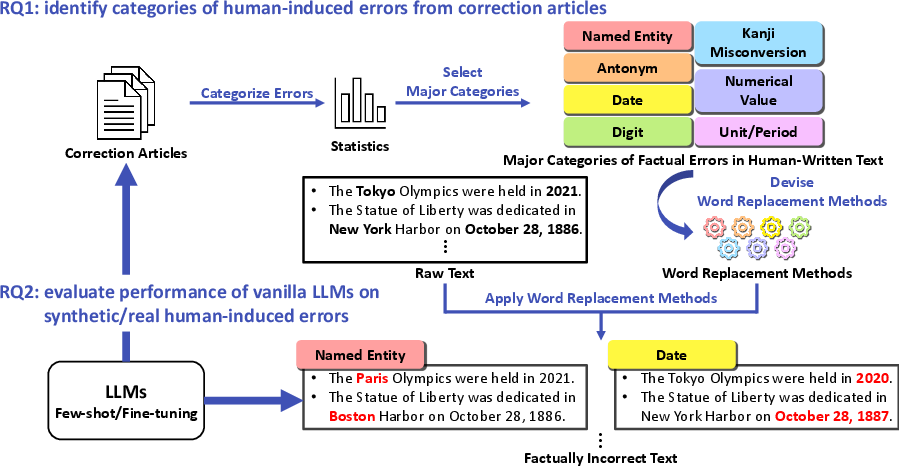
They read 234 correction articles and grouped the errors into categories. Some examples:
- Named entity mix-ups: the wrong person, place, company, job title, or country (e.g., writing “Washington State” instead of “Oregon State”).
- Kanji misconversion (specific to Japanese): choosing a wrong character that sounds the same (like picking the wrong “Hideaki Honda” kanji).
- Antonyms: using a word that means the opposite (e.g., “employment rate” vs. “unemployment rate”).
- Numbers: wrong values (30 million vs. 35 million), wrong dates (2020 vs. 2021), wrong size units (meters vs. kilometers), or wrong scale (2 tons vs. 20,000 tons).
They found that some human errors (like kanji misconversion and certain number/unit mistakes) are common in real writing but are not the focus of many AI “hallucination” tests.
3) Create realistic “fake mistakes” to test AI at scale
To run larger experiments, they automatically made “fake” but realistic mistakes in real newspaper sentences. Think of it like this: take a correct sentence and swap out a name, number, date, unit, or antonym in a careful way so it becomes factually wrong but still looks natural. For example:
- Change “35 million” to “30 million.”
- Change “June 2021” to “June 2020.”
- Change “5.7 m” (meters) to “5.7 km” (kilometers).
- Change a person’s name to a similar-sounding but wrong kanji spelling.
They then built a testing dataset from these modified sentences, plus some untouched sentences to keep the test realistic.
4) Test LLMs on the detection task
They asked several strong LLMs to:
- Sentence-level: pick which sentences contain a factual error.
- Word-level: point to the exact wrong word(s) or number(s).
They used few examples in the prompt (few-shot) and also tried fine-tuning some models on their synthetic data. Importantly, the models did not get to look things up online; they had to rely on what they “know” from training.
5) Analyze what’s easy vs. hard
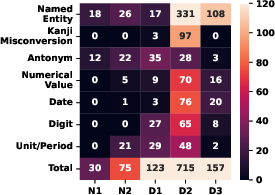
They labeled each test case by how hard it should be to detect:
- Easy by context (D1): You can tell it’s wrong just by reading nearby words.
- Needs world knowledge (D2): You need facts about the world (e.g., history, geography, company info).
- Very hard (D3): Tough even with world knowledge. They also tracked noise (N1/N2): cases with no real error, or ones that look wrong just from the suspicious replacement itself.
What did they find, and why does it matter?
Here are the big takeaways:
- LLMs still miss many human-made factual errors.
- On the synthetic (fake-but-realistic) data, even a top model (called GPT-5.4 in the paper) only found about half of the wrong words correctly (word-level F1 around 52%). In simple terms: it correctly identified the specific wrong word(s) about half the time.
- Models that were smaller and then fine-tuned got better than their starting point but still lagged behind (best word-level F1 around 36%).
- Real-world errors are even harder.
- When tested on actual newspaper corrections, the best model’s word-level score dropped to about 17%. This suggests real corrections often require more background knowledge or are more complex than controlled word swaps.
- What kinds of errors are easier for models?
- Unit/Period and Digit mistakes (like meters vs. kilometers or 2 vs. 20,000) were relatively easier for models, even when world knowledge is needed. Why? Because some numbers or units are obviously unrealistic (a giraffe being “5.7 km” tall is clearly wrong).
- Errors you can catch just by context (D1) had better scores than those requiring outside knowledge (D2). This shows models are better at “does this fit with the rest of the sentence?” than “is this true in the real world?”
- What’s special about human errors?
- Kanji misconversion and certain number/unit mistakes were common in real human writing but not common in existing AI hallucination tests. This means past benchmarks may not represent the kinds of mistakes editors face in real newsrooms.
Why this matters:
- Missing factual errors in news or education can cause real harm (misinforming readers). Tools that can highlight likely errors can save editors time and help prevent mistakes from spreading.
What’s the impact and what comes next?
- For editors and writers: This work moves toward practical tools that flag likely factual mistakes in human-written text. Think of an assistant that underlines suspicious names, numbers, or dates for a human to check.
- For researchers: The paper provides:
- A clear map (taxonomy) of the error types humans actually make.
- A way to build realistic test data by carefully replacing words and numbers.
- Evidence that current models struggle, especially when outside knowledge is needed.
- What’s needed to improve:
- Connect models to trusted external knowledge (like databases or search) so they can verify facts, not just guess from context.
- Better datasets in multiple languages (this work is in Japanese; the idea likely transfers, but more languages would help).
- Cleaner synthetic data and larger, more varied real-world tests.
- Bigger or better-tuned models, and testing with more in-context examples.
In short: The paper shows that catching factual mistakes in human writing is hard—even for strong AI—and maps out concrete steps to build better detectors that could help real editors keep information accurate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved in the paper, framed to guide follow-up research:
- Cross-lingual generalizability: The taxonomy and dataset are derived from Japanese newspaper corrections; it is unknown whether category prevalence and detection difficulty transfer to languages with different scripts (e.g., alphabetic, abjad) and morphology. Replicate the taxonomy and evaluation across multiple languages and outlets (e.g., English, Chinese, Arabic).
- Domain coverage beyond newspapers: The analysis focuses solely on newspaper articles; it is unclear how human-induced factual errors manifest in other genres (e.g., scientific writing, legal documents, social media, blogs). Construct and compare datasets across diverse domains.
- Selection bias in correction articles: Correction pages reflect only errors detected and publicly corrected by a newsroom; many human errors may never be corrected or published. Quantify and mitigate this bias (e.g., via internal editorial logs or third-party fact-checking archives).
- Limited sample size and source diversity: The taxonomy uses 234 corrections from a single outlet over 2020–2023. Expand to larger, multi-year, multi-newspaper corpora to validate category frequencies and distributions.
- Annotation reliability: Categories and detection difficulty labels were determined without reporting inter-annotator agreement. Establish multi-annotator protocols, measure agreement (e.g., Cohen’s/Fleiss’ kappa), and release detailed guidelines.
- Coverage gaps in taxonomy: Phrase-level and discourse-level factual errors are recognized but not modeled in the synthetic set; only seven word/number categories are used for evaluation. Develop controlled generators for phrase/discourse-level errors and incorporate them into training/evaluation.
- Synonym-related factual errors excluded: Synonym-based replacements were omitted due to quality issues. Design better constraints and filters to safely generate near-synonym substitutions that change truth conditions without breaking fluency.
- Cross-sentence and document-level consistency: The evaluation centers on sentence- or word-local spans; errors that only surface through multi-sentence reasoning (coreference, entity disambiguation, cross-paragraph contradictions) are not tested. Create document-level FED benchmarks.
- World knowledge grounding: Detection is performed without external knowledge. Systematically test retrieval-augmented or KB-linked FED, and identify which sources (Wikipedia, news archives, domain KBs) best reduce Difficulty 2 errors.
- Temporal knowledge and outdatedness: Date errors are synthetically limited (e.g., ±5 years), and broader outdated facts (policy changes, personnel shifts) are not modeled. Develop time-aware FED datasets and evaluate temporal grounding strategies.
- Transfer to real corrections: There is a large performance gap between synthetic (52% word-level F1) and real corrections (16.9%). Pinpoint contributing factors (e.g., implicit background, editorial phrasing, multi-hop reasoning) and design transfer-learning or domain-adaptation methods to close the gap.
- Noise auditing and per-category quality: While overall noise (N1/N2) is reported, the paper lacks a per-category precision/recall audit of the synthetic generation and filter. Quantify noise by category and replacement method; iterate filters to raise dataset precision.
- Synonym filter validation: The LLM-based synonym filter removes ~20% of samples, but its accuracy is not measured. Benchmark the filter’s precision/recall and analyze false positives/negatives to avoid discarding valid hard cases or keeping near-synonyms.
- Replacement validity and falsehood assurance: Named-entity replacements are constrained by NER/type, but are not explicitly verified against evidence to ensure they are false in context. Add automatic factuality checks (e.g., retrieval-based contradiction tests) during synthesis.
- Sentence segmentation and span boundary accuracy: Sentence detection by punctuation can be brittle in Japanese; multi-token span boundary evaluation is not deeply analyzed. Evaluate with robust sentence/word tokenizers and report boundary-specific metrics (e.g., partial span overlap).
- Class distribution realism: Synthetic category frequencies may not reflect real-world incidence. Align synthetic distributions with observed correction frequencies and study the impact of distribution shift on FED performance.
- Lack of non-LLM baselines: No comparisons with retrieval+NER/KG pipelines or traditional fact-checking baselines. Implement strong non-LLM baselines to calibrate the benefit of LLM-only approaches.
- Human upper bound: The paper does not report human editor performance on the synthetic or real test sets. Establish human baselines to contextualize model performance and identify ceiling effects.
- Explainability and evidence: FED is evaluated as span detection without requiring evidence or justifications. Investigate models that output spans plus supporting evidence/explanations to better support editorial workflows.
- End-to-end revision: Only detection is studied; correction is not jointly evaluated. Build and assess detection-to-correction pipelines to measure downstream editorial utility.
- Model scaling and training regimes: Experiments use 8B open models with 6-shot prompting and QLoRA; the effect of larger models, more shots, chain-of-thought, self-consistency, or preference fine-tuning is unknown. Conduct scaling and prompting ablations.
- Toolchain bias and error propagation: Data synthesis depends on GiNZA (NER), T5 (span generation), MeCab, pykakasi/mozcpy, and word2vec. Quantify how tool errors (e.g., NER mistakes, mis-conversions) affect dataset validity and model training.
- Coreference and entity linking: Replacements may not update all mentions (aliases, pronouns), creating inconsistencies that help detection for the wrong reasons. Add coreference-aware replacements and evaluate models on consistent and inconsistent variants.
- Robustness to text variation: The paper does not assess robustness to paraphrase, style, OCR noise, or domain shifts. Build adversarial and noisy variants to evaluate stability.
- Bias and fairness: No analysis of whether detection performance varies by entity type (e.g., gendered names, minority groups) or topic (politics, finance). Perform bias audits and mitigate disparate performance.
- Data contamination risks: GPT-5.4’s pretraining data is unknown, and Nikkei content may appear in web corpora. Assess potential training–test contamination and its impact on claims about “knowledge-only” detection.
- Reproducibility constraints: Core experiments rely on proprietary articles; only a smaller Wikinews-based dataset is public. Release larger open-source surrogates, standardized evaluation scripts, and detailed prompts to enable reproducibility.
- Evaluation metrics breadth: Only precision/recall/F1 are reported. Add calibration (AUC, ECE), detection confidence, and cost-sensitive metrics relevant to editorial triage (e.g., span-level utility or reviewer workload).
- Difficulty label automation: Detection difficulty labels (D1–D3) require manual annotation. Explore automatic proxies (e.g., evidence availability, retrieval success, NLI confidence) to scale difficulty-aware evaluation.
- Category-level error analysis: Beyond a matrix figure, there is limited qualitative analysis of per-category failure modes (e.g., why Digit and Unit/Period are easier). Provide fine-grained error typologies and propose targeted detectors per category.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s taxonomy, synthetic data generation, and baseline FED results. Given current model performance (best word-level F1 ≈ 52% on synthetic; substantially lower on real corrections), these are framed as high-precision, human-in-the-loop tools, with a focus on error types that the study finds relatively easier (Unit/Period and Digit) and context-detectable cases (D1/N2).
- Bold-span fact-linting for newsrooms (media/publishing)
- A pre-publication assistant embedded in CMS that highlights likely factual-error spans (units, digits/scales, dates, named entities) for editors to review; prioritizes Unit/Period and Digit categories and obvious date inconsistencies.
- Tools/Workflow: Span-level tagger using few-shot GPT or small fine-tuned 8B models; rule-based checks for zero-terminated numbers and unit sanity; GiNZA NER + MeCab for Japanese; risk-based UI with category labels from the taxonomy.
- Assumptions/Dependencies: Japanese language stack; human-in-the-loop sign-off; acceptance of modest recall; no external retrieval (vanilla LLM setting).
- Post-publication corrections triage and analytics (media/publishing, operations)
- Automatically surfaces candidate corrections from live articles and routes to editors; dashboards summarize error types by taxonomy to guide training and process improvement.
- Tools/Workflow: Batch scanning pipeline; taxonomy-coded counters; weekly KPI reports.
- Assumptions/Dependencies: Access to article streams and correction logs; organizational buy-in.
- Financial report and sell-side research QA (finance)
- “Number and unit sanity check” for earnings notes, models, and research summaries; flags scale errors (e.g., million vs billion), date slippages, and mismatched currency/period units.
- Tools/Workflow: Digit and Unit/Period detectors; date normalization and range checks; Excel/Google Sheets add-in that highlights spans inline.
- Assumptions/Dependencies: Domain dictionaries (currencies, metrics); high precision thresholds; data confidentiality.
- Press release verifier (corporate communications/PR)
- Pre-issue linting of names, job titles, dates, and quantitative claims; reduces costly public corrections.
- Tools/Workflow: Named-entity cross-check against internal org directory; date/digit/unit checks; category-based warnings.
- Assumptions/Dependencies: Access to internal authoritative lists; legal/comms sign-off.
- Translation QA for Japanese content (localization)
- Detect kanji misconversion and named-entity mismatches in JP-target translations; catches homophone-related errors common in human workflows.
- Tools/Workflow: pykakasi + mozcpy to simulate/spot likely misconversions; GiNZA NER validation across source/target.
- Assumptions/Dependencies: Availability of bilingual termbases; Japanese-focused.
- Classroom writing tutor distinguishing proofreading vs revising (education)
- Student feedback that differentiates grammar vs factual revision and labels suspected facts by category (e.g., “unit mismatch” vs “named entity”).
- Tools/Workflow: Lightweight span tagger limited to D1/N2 difficulty; feedback templates derived from taxonomy; private on-device or campus server deployment.
- Assumptions/Dependencies: Conservative scope; educator supervision; JP content focus initially.
- Document ingestion fact-lint in enterprise DMS (software/knowledge management)
- As documents are uploaded, highlight likely scale/unit/date anomalies to content owners; annotate spans with category tags.
- Tools/Workflow: Asynchronous scanner; comment threads for remediation; audit trail of corrections.
- Assumptions/Dependencies: Role-based access; opt-in workflow; acceptable false-positive rate.
- Customer support KB freshness checks (software/support)
- Flag dates and numeric values likely to be outdated or inconsistent across articles.
- Tools/Workflow: Date drift heuristics; cross-article consistency scan; periodic review queue.
- Assumptions/Dependencies: Access to KB; simple rules + span-level detector; human review.
- Data entry guardrails for forms (line-of-business software)
- Inline warnings for suspicious units/scales (e.g., “km” where “m” is typical), and large digit jumps.
- Tools/Workflow: Rule-based validators derived from taxonomy; per-field thresholds; error tooltips.
- Assumptions/Dependencies: Field semantics defined; domain baseline ranges.
- Engineering docs/version notes checker (software)
- Flags inconsistent version numbers, dates, and unit errors in performance claims.
- Tools/Workflow: Date/number detectors; pattern catalogs for “version semantics.”
- Assumptions/Dependencies: Project-specific patterns; conservative deployment.
- Content moderation triage for simple factual slips (platforms/policy ops)
- Quickly separate clear numeric/unit inconsistencies for moderator review, complementing full fact-checking queues.
- Tools/Workflow: High-precision Unit/Period/Digit rules; human adjudication.
- Assumptions/Dependencies: Use as triage only; policy thresholds.
Long-Term Applications
These require further research, scaling, or development—especially external knowledge integration, multilingual expansion, higher-accuracy models, and broader benchmarks aligned with real corrections (where current performance is low).
- Retrieval-augmented revision assistant with provenance (media, enterprise, general productivity)
- Span-level detection coupled with evidence retrieval (Wikidata, newswires, internal KB) and citation-ready justifications; recommends minimal edits.
- Tools/Workflow: RAG pipelines; span-to-query generation; verifiable sources and provenance UI.
- Assumptions/Dependencies: Reliable retrieval, source governance, citation UX; higher-accuracy models.
- Multilingual taxonomy and dataset mining from global corrections (academia, tools vendors)
- Replicate the corrections-mining methodology in English and other languages; produce standardized taxonomies accounting for language-specific phenomena (e.g., homophones in non-Latin scripts).
- Tools/Workflow: Web-scale corrections crawlers; semi-automatic taxonomy induction; expert validation.
- Assumptions/Dependencies: Licensing, access to corrections pages; annotation budgets.
- Standardized FED benchmark suite with difficulty labels (academia/industry)
- Public datasets with span annotations and D1–D3 difficulty tags; leaderboards for human-written text FED beyond hallucinations.
- Tools/Workflow: Data statement, annotation protocols; community evaluation harness.
- Assumptions/Dependencies: Open corpora; sustained maintenance.
- Real-time collaborative editor plugin with low-latency span detection (productivity software)
- Co-authoring environments that “fact-lint” as users type and suggest fixes with confidence estimates.
- Tools/Workflow: Streaming LLM inference; on-device or edge models; incremental span tracking.
- Assumptions/Dependencies: Latency targets; privacy controls.
- High-stakes domain adapters (healthcare, aviation, pharma)
- Dose/unit verification and entity/date accuracy with domain ontologies (e.g., RxNorm, SNOMED CT); strict precision thresholds and auditability.
- Tools/Workflow: Ontology-grounded FED; strong validation layers; governance logs.
- Assumptions/Dependencies: Regulatory clearance; liability frameworks; expert oversight.
- Legal/contract factual consistency checker (legaltech/finance)
- Cross-check parties, titles, dates, and amounts against registries and prior drafts; indicate span-level conflicts.
- Tools/Workflow: Entity resolution to KYC registries; redline-aware span detection.
- Assumptions/Dependencies: Data-sharing agreements; high accuracy demands.
- Cross-document consistency auditor for publications (media/knowledge graphs)
- Ensure numbers, units, and names remain consistent across an issue/series; detect silent regressions.
- Tools/Workflow: Document graph construction; consistency queries tied to taxonomy.
- Assumptions/Dependencies: Unified content graph; content IDs and versioning.
- Multimodal consistency check (text ↔ tables/figures) (software, analytics)
- Verify that numbers mentioned in text match charts/tables; flag mismatched scales/units.
- Tools/Workflow: Chart/table parsers; vision-language alignment; span-to-cell mapping.
- Assumptions/Dependencies: Robust extraction from PDFs/images; table structure recovery.
- Factuality-aware authoring LLMs (software platforms)
- Writing assistants trained with synthetic FED data and difficulty curricula to reduce human-introduced factual errors, not just hallucinations.
- Tools/Workflow: Multi-objective training (fluency + factuality); span-level loss functions; feedback loops.
- Assumptions/Dependencies: Transfer from synthetic to real; evaluation on real corrections.
- Continuous learning from in-house corrections (media/enterprise)
- Auto-generate synthetic training data from internal content using the paper’s replacement methods; QLoRA updates to house models; track category-wise improvements.
- Tools/Workflow: Data pipeline + scheduled fine-tuning; drift monitoring; A/B rollout.
- Assumptions/Dependencies: Model ops maturity; careful noise control and governance.
- Public-sector “Corrections Observatory” (policy/transparency)
- Aggregate government and agency corrections, classify by taxonomy, and publish metrics to improve information quality.
- Tools/Workflow: ETL from agency sites; taxonomy classification; public dashboards.
- Assumptions/Dependencies: Open data access; neutrality and governance.
- Media liability risk analytics (insurance/media)
- Quantify publisher risk from historical factual error profiles (by category, section, author); inform premiums and risk mitigation services.
- Tools/Workflow: Error-type time series, control charts; benchmarking across peers.
- Assumptions/Dependencies: Legal access to historical data; ethical safeguards.
- Cross-lingual expansion and adaptation (globalization/academia)
- Extend kanji misconversion analogs to other scripts (e.g., Chinese character confusion, Arabic diacritics, Cyrillic homographs); localize units/classifiers.
- Tools/Workflow: Script-specific NER/segmentation; culturally aware unit catalogs.
- Assumptions/Dependencies: Language resources; expert review.
Notes on feasibility and dependencies across applications
- Current capability envelope: Best synthetic word-level F1 ≈ 52%; real corrections much lower. Immediate deployments should prioritize high-precision categories (Unit/Period, Digit) and human-in-the-loop review; wider automation depends on retrieval and stronger models.
- External knowledge: Many D2 cases require world knowledge; retrieval-augmented pipelines and domain ontologies are key dependencies for long-term accuracy.
- Language scope: Methods were developed and tested in Japanese; porting requires language-specific resources (NER, tokenization, unit/classifier lexicons) and local correction corpora to refine the taxonomy.
- Data and governance: Integrations in regulated or confidential settings (finance, healthcare, legal) require privacy, auditability, and clear human oversight.
- Synthetic-to-real gap: The taxonomy-driven replacement methods are valuable for controlled evaluation and training data augmentation, but production systems must be calibrated against real corrections and incorporate stronger filtering and evidence-backed verification.
Glossary
- Fact Verification: Task of determining whether a claim is true or false, typically using evidence retrieval and classification. "Fact Verification, also called fact-checking, is the task of judging whether given text presents misinformation."
- Factual Error Correction (FEC): Task of minimally editing text to fix factual inaccuracies. "Factual Error Correction (FEC) is the task of minimally editing given text to ensure factual correctness."
- Factual Error Detection (FED): Task of identifying spans of text that are factually incorrect. "Factual Error Detection (FED), which is the task of identifying factually incorrect spans in a given text,"
- FEVER: A benchmark dataset for fact verification based on Wikipedia claims with evidence. "One widely used benchmark for this task is FEVER~\cite{thorne-etal-2018-fever},"
- FecData: A dataset for factual error correction derived from FEVER’s intermediate annotations. "A major dataset for this task is FecData~\cite{thorne-vlachos-2021-evidence},"
- Few-shot (prompting): Using a small number of examples in the prompt to guide model behavior. "few-shot () performance of each model"
- Fine-tuning: Further training a pre-trained model on a task-specific dataset to adapt it. "we focus on frameworks independent of external knowledge such as in-context learning and fine-tuning."
- Gemma-4-8B: An 8-billion-parameter instruction-tuned LLM evaluated in the study. "the 8B instruction-tuned Gemma 4 (hereafter, Gemma-4-8B)"
- GiNZA: A Japanese NLP toolkit used here for named entity recognition and name extraction. "We used GiNZA\footref{footnote:ginza} for extracting personal names,"
- Hallucination detection: Detecting factually incorrect content specifically in LLM-generated text. "Hallucination detection literally aims to detect hallucinations, factually incorrect spans in LLM-generated text."
- HaluEval: A benchmark of hallucinated responses used to evaluate hallucination detection. "One example is HaluEval~\cite{li-etal-2023-halueval},"
- HaluEval 2.0: An extended version of HaluEval that categorizes hallucinations into multiple types. "It has been extended to HaluEval 2.0~\cite{li-etal-2024-dawn},"
- In-context learning: Conditioning a model on examples within the prompt without updating parameters. "we focus on frameworks independent of external knowledge such as in-context learning and fine-tuning."
- Instruction-tuned (LLM): A model fine-tuned with instruction-following data to better obey prompts. "the 8B instruction-tuned Qwen3 Swallow (hereafter, Qwen3-Swallow-8B),"
- JTruthfulQA: A Japanese adaptation of the TruthfulQA benchmark used to study hallucinations. "in JTruthfulQA,\footnote{\url{https://github.com/nlp-waseda/JTruthfulQA} the Japanese version of TruthfulQA~\cite{lin-etal-2022-truthfulqa}."
- Kanji Misconversion: Errors from choosing an incorrect kanji with the same reading during input conversion. "We target kanji misconversions of personal names because they were the most frequent among the kanji misconversions in correction articles."
- kana-kanji conversion: Converting phonetic kana script into logographic kanji characters (and vice versa) in Japanese text processing. "mozcpy\footnote{\url{https://github.com/ikegami-yukino/mozcpy} for kana-kanji conversion."
- LLMs: High-capacity LLMs trained on large corpora, often capable of broad knowledge and reasoning. "with the rapid rise of LLMs,"
- Llama 3.1 Swallow: An instruction-tuned Japanese-capable LLM variant used for candidate generation and filtering. "the 8B instruction-tuned Llama 3.1 Swallow~\cite{fujii-etal-2024-continual}\footnote{"
- mC4: A multilingual web-scale corpus used for pre-training T5-style models. "pretrained on a Japanese portion of mC4~\cite{xue-etal-2021-mt5} and Wikipedia"
- MeCab: A Japanese morphological analyzer used for extracting specific word types (e.g., verbal nouns, classifiers). "We used MeCab\footnote{\url{https://taku910.github.io/mecab/}\label{footnote:mecab} for extracting verbal nouns,"
- micro-F1: An F1 score computed globally over all instances, aggregating contributions from all classes. "First, we focus on the micro-F1 for each detection difficulty."
- mozcpy: A tool/library used to perform kana-to-kanji conversion in Japanese text. "mozcpy\footnote{\url{https://github.com/ikegami-yukino/mozcpy} for kana-kanji conversion."
- Named entity recognition (NER): Automatically identifying and classifying named entities (e.g., people, organizations) in text. "we apply named entity recognition to each candidate and retain it as a replacement if it belongs to the same category as the target word."
- Numeral classifier: A linguistic unit that co-occurs with numbers to quantify nouns (common in Japanese), e.g., units and counters. "We extract a numeral classifier for a target word and substitute it with another similar word using word2vec."
- Pre-training: Initial large-scale training of a model on raw text before task-specific adaptation. "Since LLMs have acquired immense world knowledge through pre-training on large-scale raw corpora"
- pykakasi: A tool for converting between kanji and kana scripts in Japanese (kanji-kana conversion). "pykakasi\footnote{\url{https://codeberg.org/miurahr/pykakasi} for kanji-kana conversion,"
- QLoRA: A parameter-efficient fine-tuning method for quantized LLMs using low-rank adapters. "fine-tuned using QLoRA~\cite{dettemrs-etal-2023-qlora}"
- Qwen3-Swallow-8B: An 8B-parameter instruction-tuned LLM variant evaluated in the experiments. "the 8B instruction-tuned Qwen3 Swallow (hereafter, Qwen3-Swallow-8B),"
- Regular expression: A formal pattern language for matching and extracting text strings. "We extract a number using a regular expression and replace it with a random number within the same number of digits."
- Retrieval-augmented systems: Systems that augment model generation with information retrieved from external knowledge sources. "Examples include databases or retrieval-augmented systems, which are often crucial in on-the-ground editorial work."
- Span-level (detection): Operating at the level of contiguous text spans rather than whole sentences or documents. "Our work uniquely focuses on span-level detection of human-induced factual errors."
- Subject–predicate–object triple format: Representing facts as structured triples (entity, relation, entity) for extraction or checking. "subjectâpredicateâobject triple format"
- T5: A text-to-text transformer model used here for masked span generation. "a text generation model, T5~\cite{raffel-etal-2020-exploring}, which can complete a masked span with multiple tokens."
- TruthfulQA: A benchmark assessing whether models avoid imitating common falsehoods. "the Japanese version of TruthfulQA~\cite{lin-etal-2022-truthfulqa}."
- Word2vec: A distributional word embedding method used to find semantically related (including antonymous) words. "using word2vec~\cite{mikolov-etal-2013-distributed}"
Collections
Sign up for free to add this paper to one or more collections.

