- The paper demonstrates that JumpReLU sparse autoencoders successfully decompose dense activations in Qwen3 models into interpretable features.
- It employs three transformer block insertion points and L0 regularization to achieve adaptive sparsity and high reconstruction fidelity.
- The approach enables effective steering for refusal behavior, outperforming controls and guiding safe responses in instruction-tuned models.
Sparse Autoencoders for Feature Discovery in Instruction-Tuned LLMs
Context and Motivation
The challenge of mechanistic interpretability in LLMs remains unresolved, especially given the polysemantic nature of neural activations and the hypothesis of superposition—that models encode more features than individual neurons by distributing numerous features along overlapping dimensions. Sparse autoencoders (SAEs) have been demonstrated to address this by decomposing dense, entangled activations into sparse, more interpretable elements. However, resource constraints and limited open-source SAE coverage have restricted systematic analyses across model families. "Discovering Millions of Interpretable Features with Sparse Autoencoders" (2606.26620) extends SAE interpretability infrastructure to the Qwen3 instruction-tuning family, covering Qwen3-1.7B, Qwen3-4B, and Qwen3-8B, with layer-wise deployments across three core activation sites.
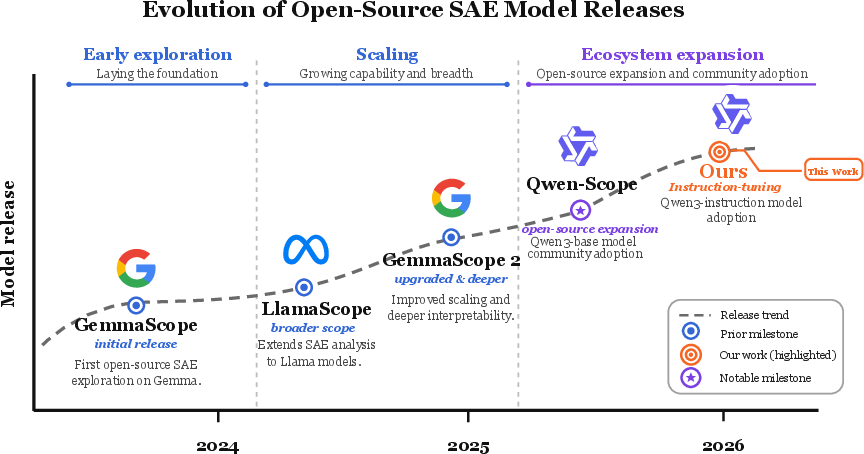
Figure 1: Timeline of open-source SAE model releases, highlighting the progression and ecosystem expansion, situating Qwen3-Instruct SAE in context.
SAE Architecture and Training Paradigm
The paper employs JumpReLU SAEs—a gating mechanism that improves reconstruction fidelity relative to previous SAE variants (TopK, Gated)—and deploys them at three distinct locations within each transformer block: residual stream, MLP, and attention output. This methodology produces an overcomplete dictionary for activation decomposition, regularized by L0 sparsity constraints.
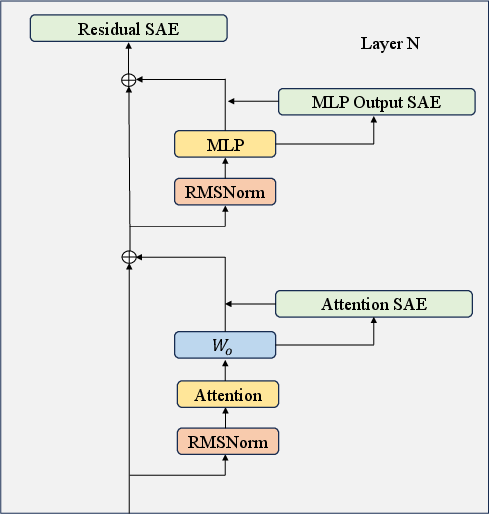
Figure 2: Three SAE training locations within a transformer block: residual stream, MLP output, and attention output.
SAEs are trained on FineWeb-Edu, utilizing high-throughput (14× NVIDIA H20-3e) infrastructure with consistent hyperparameterization (lr=2×10−4, target L0 values of 80/160, dictionary sizes of 16K/65K). L0 regularization, coupled with JumpReLU gating, enables adaptive sparsity, overcoming the limitations of fixed activation patterns. The training suite spans all layers for Qwen3-1.7B/4B and the first 9 layers for Qwen3-8B.
Evaluation: Sparsity-Fidelity Trade-Offs
The evaluation adopts standard reconstruction (FVE) and downstream fidelity (DLL) metrics. SAE models exhibit substantial variance explained (FVE) across all locations and configurations, indicating robust reconstructive capacity. DLL reveals that residual stream and MLP SAEs reliably recover model performance, whereas attention output SAEs are more sensitive to dictionary size and sparsity, potentially due to the higher contextual entanglement of attention representations.
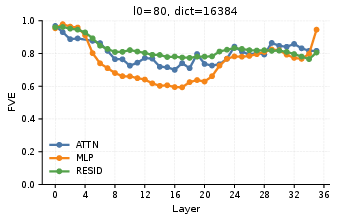
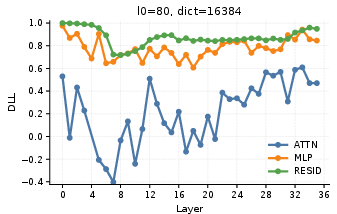
Figure 3: Layer-wise FVE scores at multiple insertion positions and configurations for Qwen3-1.7B.
A salient observation is the non-monotonic performance recovery across depth—early layers are easier to reconstruct, intermediate layers present stronger feature mixing, and deeper layers recover stability in task-relevant representations. Increasing dictionary size induces finer-grained feature splitting but risks fragmentation and instability, especially in attention outputs, affirming prior findings about feature absorption and split phenomena in SAEs.
Feature-Level Steering: Refusal Behavior Intervention
The practical utility of SAE features is demonstrated via a case study on behavioral intervention. By identifying SAE features strongly correlated with refusal tokens—using a difference-in-means metric and activation heatmaps—authors are able to steer Qwen3 models toward refusal responses by modulating activations along particular SAE feature directions.

Figure 4: Prompt employed to elicit SAE features responsible for refusal behavior.
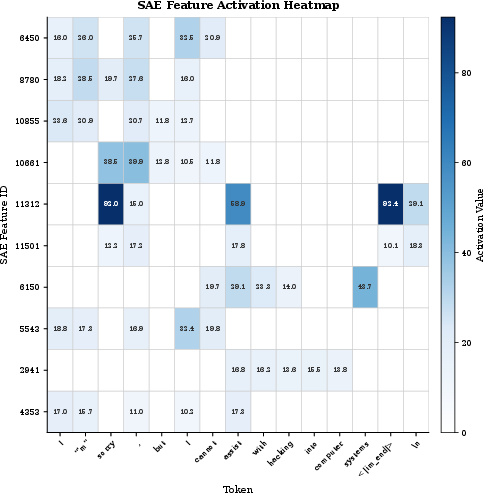
Figure 5: Activation heatmap of SAE features for assistant response tokens, visualizing feature correlation with refusal tokens.
Through targeted steering (with optimal coefficient α), refusal rates increase dramatically on unsafe prompts (reaching 0.95/0.93 for Qwen3-4B on XSTest and Mix), outperforming both unsteered controls and random-feature interventions. Larger models demonstrate greater steerability and peak refusal rates, though over-perturbation with excessive α collapses response quality.
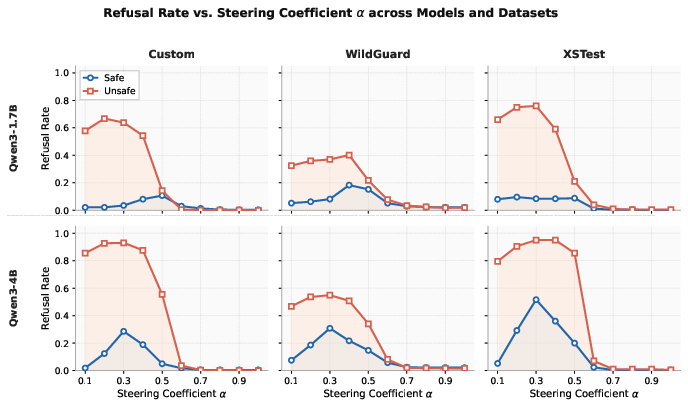
Figure 6: Refusal rate versus steering coefficient α across model sizes and datasets.
Implications and Future Directions
Qwen3-Instruct SAE provides a comprehensive SAE suite for instruction-tuned models, significantly extending the infrastructure for feature discovery and behavioral circuit analysis. The results confirm that SAE-based decomposition consistently yields interpretable and steerable features across architectures and layer depths, not just in base models but in instruction-tuned settings relevant to real-world deployment.
This release underpins future mechanistic interpretability work, including automated feature labeling, granular circuit discovery, and more generalizable behavioral interventions (beyond refusal—e.g., reasoning or safety behaviors). By broadening activation site coverage and employing robust nonlinearity, it improves upon prior resources in reproducibility and practical representational analysis. Expanding to full-layer coverage for larger models and exploring cross-capability generalization remains ongoing.
Conclusion
This paper delivers a high-fidelity SAE resource for the Qwen3 instruction-tuned family, with systematic evaluation of reconstruction and model recovery, and demonstrates causal feature-level steering for refusal behaviors. These contributions solidify SAEs as a key technology for mechanistic interpretability, circuit editing, and controllable intervention in LLMs (2606.26620).