Critique of Agent Model
Abstract: What is an agent? What constitutes agency? With the rise of LLM systems marketed as coding agents'',AI co-scientists'', and other agentic" tools that promise to drive up productivity, and at the same time,existential" concerns such as AI escaping human control with destructive power under a speculative machine agency" against humans, it has become essential to clarify where automation ends and agency begins, both for building capable systems and for understanding whether and what to fear. Drawing on Descartes' grounding of agency in independent thought, and on portrayals of autonomous beings in science fiction, we survey the current landscape of AI agents, and analyze agent architectures along five dimensions: goal, identity, decision-making, self-regulation, and learning. Specifically, we argue that genuine agency requires these structures to be \emph{internalized within the system itself} rather than assembled through external scaffolding. This distinction between \emph{agentic} systems, whose competence resides in engineered workflows, and \emph{agentive} systems, whose capabilities (including social interaction) arise endogenously, defines the boundary between systems designed for prescribed tasks, and those capable of operating in the open world with true autonomy. Building on this analysis, we propose the Goal-Identity-Configurator (GIC) architecture for a general-purpose agent model, combining hierarchical goal decomposition, identity evolution, simulative reasoning grounded in a separately trained world model, learned self-regulation, and self-directed learning from both real and simulated experience. Furthermore, we share insight on the auditability, controllability, and safety of agentive systems that possess greater autonomy andagency", but remain under human oversight.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: what does it mean for an AI to be an “agent” with real independence, not just a fancy automated tool? It looks at how today’s so‑called “AI agents” are built, explains why most of them are more like carefully scripted assistants, and proposes a new design—called GIC—that could help build AI systems with more genuine autonomy while still staying under human oversight.
Objectives
The paper aims to:
- Draw a clear line between two types of systems: agentic (strong automation built around a model) and agentive (systems with true, internal agency).
- Define the key ingredients that real agency needs: goals, identity, decision-making, self-regulation, and learning.
- Explain why an “agent model” (the part that decides what to do) should be separate from a “world model” (the part that predicts what will happen).
- Propose a general architecture (GIC: Goal‑Identity‑Configurator) that brings these ingredients together.
- Discuss how such agentive systems can be made auditable, controllable, and safe.
Methods and Approach (in everyday terms)
Think of an AI as a player in a game:
- The “agent model” is like the player’s mind deciding the next move.
- The “world model” is like a simulator that predicts what the game board will look like after a move.
The paper builds up this view step by step:
- Goals and subgoals: Instead of feeding the AI tiny instructions every second (“click this,” “type that”), give it a big goal (like “write a science project report”). The AI should break this into smaller steps on its own and adjust as it learns more—like a good student planning homework across a week.
- Identity: The AI should keep track of who it is and what it can do—its skills, limitations, and roles—and update that self‑knowledge over time, like a player who learns they’re better at defense than offense and changes strategy.
- Decision-making with simulation: Before acting, the AI can “imagine” different futures by running its world model—like picturing several chess sequences ahead. This is called simulative reasoning. It’s slower, careful thinking (often called “System II”), while fast reactions (like catching a ball) are quick, automatic actions (“System I”).
- Self‑regulation: The AI needs an internal “configurator”—a kind of coach—that decides when to react fast, when to plan carefully, when to change goals, and when to pause. This prevents blindly following a fixed script and helps the AI adapt effort to the situation.
- Learning from real and simulated experience: The AI should improve continuously, not just during training and then freeze. It learns from real life (like after a mistake) and from practice in its simulator (safer, cheaper, and faster), similar to how pilots train in flight simulators.
Bringing these together, the paper proposes the GIC architecture:
- Goal: The AI can decompose big goals into smaller, manageable tasks and update them over time.
- Identity: The AI’s self‑model evolves as it gains experience—no need to rebuild it from scratch.
- Configurator: A learned controller decides how much to think, act, plan, or learn at each moment.
- World model: A separate “predictor” that simulates what likely happens next, keeping planning trustworthy.
- Learning: Self-directed updates from both real and imagined practice.
Key Findings and Why They Matter
- Most “AI agents” today are agentic, not truly agentive. They rely on external scaffolding: human‑designed workflows, tools, and prompts that tell them how to behave. Their “agency” lives outside the model.
- Mixing decision-making and prediction into one big model (combining agent and world models) sounds convenient but can make both parts worse. It blurs the line between “what should I do?” and “what will happen?”, which hurts planning reliability.
- Genuine agency needs internal structures. Goals, identity, decision-making, self‑regulation, and learning should live inside the agent, not in external scripts. That’s how you get systems that can operate in open‑ended, messy real‑world settings.
- The proposed GIC architecture shows a concrete path forward. By pairing an agent model with a separate world model and adding a configurator that governs thinking and learning, you can build agents that plan long‑term, adapt their self‑knowledge, choose when to think hard, and improve continuously—while remaining auditable and controllable.
Implications and Potential Impact
If AI systems adopt this architecture:
- They can handle longer, more complex projects without constant step‑by‑step instructions, breaking big goals into smart subgoals.
- They become more adaptive and resilient: updating their identity, deciding when to plan versus act, and learning from both real life and safe simulations.
- Safety and oversight improve: separating “predict the world” from “choose actions” makes failures easier to diagnose, plans easier to audit, and behavior easier to control.
- Multi‑agent teamwork can become more natural: agents choose when to communicate and collaborate based on goals and identity, instead of following rigid scripts.
In short, the paper argues for building AI that doesn’t just follow clever workflows, but that develops its own organized way of thinking and acting—like a skilled, thoughtful teammate—while still being guided and monitored by humans.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions the paper leaves unresolved, organized to guide future research toward actionable next steps.
- Formalization and representation of identity
- How to represent the latent identity variable (symbolic schemas, embeddings, factorized traits, capabilities/affordances graphs) and map it to the admissible action set .
- How to implement and train the identity transition model so that identity adapts rapidly without requiring full retraining, while avoiding drift or mode collapse.
- Metrics and diagnostics for “identity evolution” quality (e.g., stability, responsiveness, calibration to real capabilities, avoidance of self-delusion).
- Goal formation and hierarchical decomposition
- Learning the decomposition module that maps long-term goals to viable subgoals with dependencies and priorities, including how to discover subgoals without dense supervision.
- Specifying reward/compatibility signals for arbitrary, user-defined goals and ensuring consistent credit assignment across long horizons and changing subgoal structures.
- Conflict resolution when persistent goals and newly formed subgoals disagree, and safe procedures for revising or abandoning goals.
- Belief state and world model design
- Practical belief-state inference in partially observed settings (structure of , memory architecture, uncertainty tracking) and its integration with perception and language.
- Architectures and training signals for a “hierarchical” world model that can forecast effects of subgoals over multiple time scales (physical, social, digital) with calibrated uncertainty.
- Robustness tools (OOD detection, uncertainty quantification, error bounds) and techniques for propagating world-model uncertainty into planning and self-regulation decisions.
- Simulative reasoning (System II) and plan execution (System I)
- Algorithms to approximate (e.g., MCTS, trajectory optimization, model-predictive control) under tight compute budgets and long horizons; criteria for terminating search.
- Representations for plans that support revision, partial execution, and verifiable predictions; triggers for replanning and recovery from plan–reality mismatch.
- Safety-aware planning that enforces constraints during simulation and execution, including formal methods or runtime shielding for hazardous actions.
- Self-regulation and the configurator (System III)
- Learning objectives and supervision signals for the configurator to allocate compute (when to plan vs. act reactively), manage meta-choices (learn, pause, request help), and respect resource budgets.
- Avoiding degenerate regulation policies (e.g., overplanning, underplanning, oscillations) and establishing stability/performance guarantees for System I/II/III interaction.
- Interpretability and oversight interfaces for decisions (e.g., inspectability, human veto points, and auditable rationales for internal mode switches).
- Endogenous, continuous learning
- Mechanisms for the agent to decide when and what to learn (self-curated and ), balancing real vs. simulated data to avoid simulation-induced bias or self-reinforcing errors.
- Continual learning without catastrophic forgetting, with safe online updates, versioning, rollback, and impact assessment during deployment.
- Separation of signals for training (predictive fidelity) vs. (goal attainment), and methods to prevent reward-hacking or gradient leakage across the separation.
- Safety, alignment, and auditability
- Concrete methods to log and audit internal variables (goals , identity , plans , regulation ) for compliance, post-hoc analysis, and accountability—without undermining privacy or performance.
- Techniques to prevent and detect “goal drift,” identity gaming, or preference misgeneralization during self-directed learning and identity updates.
- Operational safety frameworks for agentive systems with self-initiated learning (sandboxing, staged deployment, red-teaming, and fail-safe shutdowns).
- Multi-agent interaction and social reasoning
- Learning to infer other agents’ goals/identities, negotiate, and coordinate without externally specified team graphs or protocols; emergence of norms and role formation.
- Social world modeling (trust, reputation, commitments) and safety against collusion, manipulation, or harmful coordination.
- Benchmarks and metrics for emergent social organization and cooperative/competitive performance over long horizons.
- Embodiment and sensorimotor competence
- Extending beyond vision to richer sensors (force, tactile, temperature, proprioception) and integrating these modalities into and with sample-efficient learning.
- Sim2real transfer and curriculum design for long-horizon, safety-critical tasks; real-time constraints and latency-aware regulation between System I and II.
- Evaluation protocols and metrics for “agency”
- Operational definitions and measurement for agency-specific properties (goal persistence, identity evolution quality, self-regulation efficacy, autonomy under sparse guidance).
- Long-horizon, open-world benchmarks that probe decomposition, adaptation, and self-directed learning, including standardized ablations isolating GIC components.
- Theoretical guarantees and analysis
- Formal conditions under which separating agent and world models improves reliability vs. joint world–action models; counterexamples and trade-off characterizations.
- Convergence and stability results for intertwined processes (planning under model error, identity updates, configurator policies, continual learning).
- Exploration–exploitation theory tailored to self-regulated, simulative learners operating under compute and safety constraints.
- Tool-use and external system integration
- Treating external tools/APIs as part of the endogenous action space while preserving internal organization; learning when to invoke tools and how to validate outputs safely.
- Security and verification for tool-mediated actions (e.g., filesystem, finance, robotics) and defenses against tool-chain compromise.
- Human–agent interaction and value alignment
- Mechanisms to reconcile persistent internal goals with evolving human instructions and preferences; safe goal updates and preference learning that avoid specification gaming.
- Interfaces that let humans set high-level objectives and constraints while retaining inspectability and override capability for internal decisions.
- Scalability and systems concerns
- Compute/memory scaling strategies for long-horizon simulation and learning; distributed implementations and scheduling across System I/II/III.
- Energy-aware self-regulation and cost-sensitive planning; empirical scaling laws specific to agent and world model capacity vs. agency metrics.
- Data, privacy, and governance
- Sources and curation strategies for training diverse world models spanning physical, digital, and social domains; privacy-preserving learning from human interactions.
- Governance frameworks for self-updating agents (provenance tracking, capability controls, audit trails, and policy compliance).
- Empirical validation gaps
- Lack of concrete implementation details or experiments demonstrating the GIC architecture, its components’ training procedures, or head-to-head comparisons against strong baselines (e.g., chain-of-thought or joint world–action models).
- Absence of ablation studies quantifying the contribution of goal decomposition, identity evolution, simulative planning, and configurator-driven regulation to performance and safety.
Practical Applications
Overview
This paper distinguishes “agentic” systems (competence lives in external scaffolding) from “agentive” systems (capabilities are endogenous) and proposes the GIC architecture: hierarchical Goal decomposition (G), evolving Identity (I), and a learned self-regulating Configurator (C) that orchestrates reactive action (System I), simulative planning with a separate World Model (System II), and when/how to learn (System III). Below are practical applications that leverage these findings, organized by deployment horizon.
Immediate Applications
These applications can be implemented today by retrofitting existing LLM-based agents, robots, and automation pipelines with GIC-inspired modules, and by adopting the paper’s separation of Agent Model (AM) and World Model (WM) in design, evaluation, and governance.
Industry
- GIC-style agent SDK for current copilots and workflow agents (software/AI tooling)
- What: Add modules for hierarchical goal decomposition, explicit identity/profiles, a configurable deliberation policy (when to think/plan/act), and an explicit world-model interface (search/emulator/digital twin) to existing LLM agents.
- Tools/products/workflows: Libraries exposing g, i, u_t, c_t as first-class objects; chain-of-thought budget controllers; plan/dry-run APIs; memory/identity stores.
- Assumptions/dependencies: Access to task simulators or “dry-run” backends (e.g., CLI emulators, browser sandboxes), logging and evaluation pipelines, cost envelopes for additional planning steps.
- Simulative planning “dry-run before act” in DevOps, cloud, and RPA (software, IT/Ops)
- What: Route proposed actions through a WM (e.g., Terraform plan, k8s simulator, synthetic dataflow) to predict consequences before execution.
- Tools/products/workflows: Digital twins for infrastructure; trace-comparison (plan vs. actual) dashboards; rollback policies tied to plan mismatch.
- Assumptions/dependencies: WM fidelity vs. production reality; versioning of environment state; guardrails for divergence.
- Reflex–plan switching in embodied control (robotics, manufacturing, warehousing)
- What: Configurator u_t selects between reactive controllers (System I) and simulative MPC-like planning (System II) based on uncertainty, risk, or novelty.
- Tools/products/workflows: Uncertainty estimators; safety envelopes; motion planners backed by physics simulators; “fall back to reflex” triggers.
- Assumptions/dependencies: Reliable state estimation; safe-stop policies; calibration between simulated and real dynamics.
- Long-horizon tasking via hierarchical goals in enterprise automation (back-office, CX)
- What: Replace step-by-step prompting with single long-term objectives decomposed into revisable subgoals (claims processing, order-to-cash, supplier onboarding).
- Tools/products/workflows: Decomposer modules; subgoal queues with dependency graphs; SLA-aware scheduling; human-in-the-loop at subgoal boundaries.
- Assumptions/dependencies: Data access policies; measurable reward proxies for subgoal completion; exception handling.
- Backtesting-as-World-Model for research/trading copilots (finance)
- What: Treat historical simulators/backtest engines as the WM to evaluate candidate strategies before committing capital; configurator gates live execution.
- Tools/products/workflows: Strategy generators; risk-config policies; paper-trade staging; audit trails linking plans to executions.
- Assumptions/dependencies: Stationarity limits; slippage/latency models; compliance sign-off.
- Digital twins for building/HVAC and energy microgrids (energy, facilities)
- What: WM predicts load/comfort/price effects of actions; configurator adjusts planning depth by weather volatility and comfort constraints.
- Tools/products/workflows: BMS digital twins; goal hierarchies (e.g., cost, comfort, carbon); anomaly-triggered replanning.
- Assumptions/dependencies: Calibrated twins; sensor quality; override protocols.
- Structured care-navigation automation (healthcare administration)
- What: Use goal decomposition for multi-step administrative pathways (referrals, prior auth, scheduling) with identity capturing payor/provider constraints.
- Tools/products/workflows: Policy/benefit WM; subgoal trackers; escalation rules to human agents; auditability of plan rationales.
- Assumptions/dependencies: Regulatory compliance (HIPAA, GDPR); high-precision policy models; strict action gating (no direct clinical decisions).
- Program-of-study planners and tutoring (education)
- What: Hierarchical goals for semester → week → session plans; configurator decides when to quiz vs. explain; identity captures learner profile.
- Tools/products/workflows: Mastery-estimation WM; spaced-retrieval planners; content alignment checks.
- Assumptions/dependencies: Valid mastery proxies; bias/fairness monitoring; content licensing.
Academia
- Benchmark suites that require endogenous goals, identity updates, and self-regulation
- What: Tasks where step-by-step prompting fails, requiring hierarchical decomposition, plan-vs-world checks, and variable deliberation budgets.
- Tools/products/workflows: Partially observable environments; long-horizon dependencies; standardized logs of g, i, c_t, u_t for evaluation.
- Assumptions/dependencies: Community agreement on metrics for agency (value under interruptions, decomposition quality, self-regulation efficiency).
- Experimental protocols separating AM vs. WM training signals
- What: Train WM on prediction error and AM on goal-directed reward; measure interference and robustness vs. single-model baselines.
- Tools/products/workflows: Off-policy simulation datasets; counterfactual rollouts; ablation of shared vs. disjoint parameters.
- Assumptions/dependencies: Sufficient data for both models; stable optimization under dual objectives.
- Configurator learning studies (when/how to think/plan/learn)
- What: Learn policies over computation depth, plan horizon, and learning triggers that optimize task performance under resource budgets.
- Tools/products/workflows: Compute-costed rewards; adaptive chain-of-thought; curriculum schedules controlled by u_t.
- Assumptions/dependencies: Reliable compute metering; reproducible cost–accuracy tradeoff metrics.
Policy and Governance
- Procurement and risk-taxonomy updates distinguishing “agentic” vs. “agentive”
- What: Contractual and assessment templates that treat endogenous goal/identity maintenance, self-directed learning, and self-regulation as higher-risk features.
- Tools/products/workflows: Checklists mapping to g/i/κ/f separation; “frozen learning” vs. “self-learning” deployment modes.
- Assumptions/dependencies: Cross-agency consensus; vendor attestations; audit access.
- Auditability requirements for plan traces and self-regulation decisions
- What: Require retention of goal decompositions, plan simulations, configurator choices, and plan-vs-actual deltas for post-hoc review.
- Tools/products/workflows: Standardized telemetry schemas; red-team re-simulation harnesses; incident reconstruction playbooks.
- Assumptions/dependencies: Privacy-preserving logging; secure provenance.
Daily Life
- Personal assistants with persistent goals and profiles
- What: Set long-term objectives (e.g., fitness, budgeting); assistant decomposes into weekly tasks, adapts identity to user routines, and regulates when to interrupt.
- Tools/products/workflows: Calendar/task WM; notification budget policies; reflective updates to user profile.
- Assumptions/dependencies: Consentful data use; clear failure modes; user override at all times.
- Household project planners (moves, renovations, travel)
- What: Hierarchical plan generation with vendor/constraint-aware identity; simulative checks on timeline/budget before booking.
- Tools/products/workflows: Marketplace WMs (availability, cost); deposit/booking guardrails.
- Assumptions/dependencies: Data freshness; cancellation protection.
Long-Term Applications
These rely on further progress in agentive models: higher-fidelity world models (physical, social, economic), robust configurator learning, safe self-directed learning, and standards for oversight.
Industry
- Agentive co-scientists and autonomous R&D loops (pharma, materials, semiconductors)
- What: Endogenous hypothesis formation, simulative planning with multi-scale WMs (chemistry/biology/physics), self-regulated lab execution, and continual learning.
- Tools/products/workflows: Integrated simulation stacks; robotic labs; safety/sanity gates between simulation and wet lab.
- Assumptions/dependencies: Validated WMs across domains; strict biosafety; legal/IP frameworks.
- Generalist humanoid/industrial robots with self-directed skill acquisition (robotics)
- What: Persistent goals (fleet productivity), evolving identity (capability map), configurator for reflex/plan/learn switching; large-scale sim-to-real adaptation.
- Tools/products/workflows: High-fidelity physics + contact WMs; curriculum generation; fleet-level memory/identity sharing.
- Assumptions/dependencies: Rich sensing (force/texture), robust sim-to-real, certification for human–robot interaction.
- Autonomous enterprise agents that improve themselves under governance (software, operations)
- What: Agents that initiate retraining based on deployment errors, generate simulated curricula, and request approvals for capability updates.
- Tools/products/workflows: “Learning change management” workflows; sandboxed self-play; policy-aware configurators.
- Assumptions/dependencies: Verified update pipelines; rollback; audit-compliant continual learning.
- Adaptive grid and market operations (energy, logistics)
- What: Multi-agent, self-organizing coordination with WMs of demand, markets, and constraints; agents negotiate and reconfigure roles.
- Tools/products/workflows: Multi-agent simulators; mechanism design to align local/global goals.
- Assumptions/dependencies: Data-sharing agreements; stability guarantees; regulatory approval.
- Fully agentive research/trading systems with institutional guardrails (finance)
- What: Endogenous strategy design, multi-WM stress testing, self-regulated deployment scaling.
- Tools/products/workflows: Policy sandboxes; live–paper bridges; continuous risk-limits managed by configurator.
- Assumptions/dependencies: Market impact modeling; compliance-by-design; tamper-proof logs.
Academia
- Unified theory and proofs of separation benefits (AM vs. WM)
- What: Formal results on generalization, safety, and data efficiency from keeping decision-making distinct from prediction.
- Tools/products/workflows: Theoretical frameworks; controlled empirical validations.
- Assumptions/dependencies: Benchmarks with sharp distribution shifts; transparent baselines.
- Social agent emergence and coordination research
- What: Agents that autonomously choose when and how to communicate, form/dissolve teams, and align/interact credibly.
- Tools/products/workflows: Social WMs; signaling/commitment mechanisms; open-ended multi-agent environments.
- Assumptions/dependencies: Ethics review; misuse mitigation; evaluation of emergent behaviors.
- Safety science for self-directed learning
- What: Methods to certify learning triggers, bound exploration risks, and validate identity evolution.
- Tools/products/workflows: Counterfactual testing; causal safety cases; formal verification of configurator policies.
- Assumptions/dependencies: Advances in verifiable ML; standardized safety cases.
Policy and Governance
- Certification regimes specific to agentive systems
- What: Tiered licenses keyed to endogenous goals, identity evolution, self-regulated learning, and multi-agent coordination abilities.
- Tools/products/workflows: Pre-deployment conformance tests; in-life monitoring; sunset clauses for capabilities.
- Assumptions/dependencies: International harmonization; continuous oversight capacity.
- Policy simulators as WMs for decision-support
- What: Government uses calibrated socio-economic WMs to simulate the downstream effects of policy “action sequences” before enactment.
- Tools/products/workflows: Transparent models; scenario libraries; participatory oversight.
- Assumptions/dependencies: Model validity; bias controls; accountability frameworks.
Daily Life
- Lifelong personal coaches with evolving identity and true autonomy
- What: Agents that maintain long-term well-being goals, update their understanding of the user, simulate outcomes, and learn safely over years.
- Tools/products/workflows: Privacy-preserving memory; personal digital twins; consented self-improvement.
- Assumptions/dependencies: Robust privacy tech; clear user control; societal norms for AI companionship.
- Home robots that coordinate tasks and learn new affordances
- What: From cleaning/cooking to maintenance, robots plan, simulate, act, and practice in home-twins, updating identity (skills) without external retraining.
- Tools/products/workflows: Household simulators; appliance APIs; safety-first configurators.
- Assumptions/dependencies: Trusted physical safety; service/repair ecosystems; affordability.
Cross-cutting Assumptions and Dependencies
- World Model availability and fidelity: Domain-appropriate simulators or predictive models (physical, social, economic) must be sufficiently accurate to make simulative reasoning useful and safe.
- Clear separation of AM (decision) vs. WM (prediction): Tooling, data pipelines, and training signals must enforce the separation the paper argues is critical.
- Safety, auditability, and governance: Plan traces, configurator decisions, and identity updates should be logged and reviewable; human override must be preserved.
- Data rights and privacy: Identity and long-horizon goals require durable memory; consent, retention, and minimization are essential.
- Compute and latency budgets: Self-regulation over depth of thought/planning must reflect real cost constraints.
- Human-in-the-loop and staged deployment: Particularly in regulated and safety-critical sectors, move from simulate → shadow → constrained act → full autonomy.
These applications operationalize the paper’s central claims: internalizing goal/identity, separating decision from prediction, using simulative reasoning, and learning under a self-regulating configurator—while keeping systems auditable, controllable, and safe.
Glossary
- Abduction: A form of logical reasoning that infers the most likely explanation from observations. "In contrast to traditional logical reasoning (e.g., deduction, induction, abduction), simulative reasoning provides a general-purpose planning mechanism"
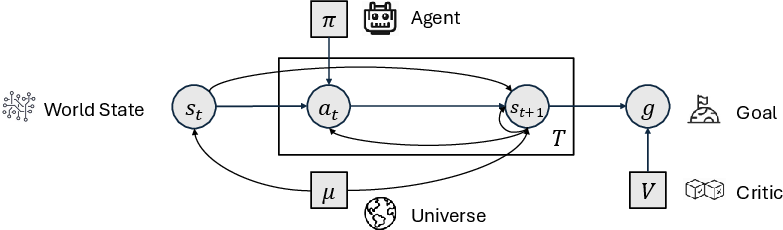
- Actor: The reactive component that maps current belief and plan into concrete actions. "Given a plan c_t, the agent selects concrete actions through an actor α that handles fine-grained reactive execution: a_t ∼ p_α(* | ĥs_t, c_t)."
- Agent Model: A learned model that generates actions based on goals and identity, distinct from the world model. "We refer to such a model as an Agent Model."
- Agentic systems: Systems whose competence largely comes from externally engineered tools and workflows. "Agentic systems, such as those described earlier, complete tasks autonomously through orchestrated tools and workflows; their competence resides primarily in the engineering around a given reasoning model such as a LLM."
- Agentive systems: Systems whose capabilities arise endogenously, maintaining goals, identity, and self-regulation internally. "Agentive systems, exemplified by biological agents and discussed at length in this paper, possess agency in the fuller sense"
- Affordances: Action possibilities available to an agent given its capabilities and environment. "such as capabilities, constraints, affordances, and relationships with other entities."
- Auto research: Using AI systems to automate parts of the research/training pipeline. "or ``auto research''~\cite{karpathy2026autoresearch}"
- Belief space: The space of internal state estimates used for planning under partial observability. "now operating in belief space: it remains a model of the world, distinct from the agent model that queries it."
- Belief state: The agent’s inferred estimate of the true world state from observations. "Instead, it receives observations o_t and infers a belief state ĥs_t representing its best estimate of the world."
- Chain-of-thought: A prompting/training technique where models produce intermediate reasoning steps. "often with chain-of-thought~\cite{wei2022chain}"
- Configurator: A learned meta-controller that regulates when and how the agent deliberates, plans, acts, and learns. "We model this through a configurator κ, which outputs a regulation variable u_t governing the agent's decision mode at each step"
- Decomposition module (δ): The component that breaks a long-term goal into subgoals. "This hierarchical structure isolates the difficulty of long-horizon planning in the decomposition module δ"
- Discounted cumulative reward: The sum of rewards over time with future rewards geometrically discounted. "A common way to evaluate goal-directed behavior is through a reward function ... and the long-term performance of a policy is evaluated by the expected discounted cumulative reward"
- GIC architecture: The Goal-Identity-Configurator architecture proposed for general-purpose agent models. "we introduce the GIC (Goal-Identity-Configurator) architecture"
- Hierarchical goal decomposition: Breaking a long-term objective into ordered, revisable subgoals. "hierarchical goal decomposition"
- Identity (in agent modeling): A latent, possibly evolving self-model of capabilities, constraints, and relations that conditions decisions. "We next introduce identity: a latent variable i_t capturing persistent properties that influence decision-making across time"
- Imitation learning: Learning policies from expert demonstrations rather than explicit reward signals. "increasingly adopt vision-language-action (VLA) architectures trained from demonstrations, imitation learning, and large-scale simulation"
- Latent variable: An unobserved variable within the agent (e.g., goal g_t or identity i_t) that influences decision-making. "We next introduce identity: a latent variable i_t capturing persistent properties"
- Model-predictive control: A control strategy that repeatedly plans actions over a receding horizon using a predictive model. "always-on model-predictive control"
- Never-ending learning: Systems that continually learn over time without a fixed endpoint. "``never-ending learning''~\cite{mitchell2018never}"
- Policy: A mapping from (belief) states to action distributions that defines the agent’s behavior. "an agent is modeled as a policy π that produces an action distribution p_π(a_t | s_t)."
- Recursive self-improvement: An AI system improving its own capabilities iteratively. "``recursive self-improvement''~\cite{patel2026darioamodei}"
- Reinforcement learning: Learning to act by optimizing cumulative reward through interaction with an environment. "train them via reinforcement learning, % with the expectation that planning capabilities will emerge"
- Self-directed learning: The agent autonomously improves from real and simulated experience under its own control. "self-directed learning from both real and simulated experience."
- Self-regulation: The agent’s ability to allocate internal computation, decide when to plan or act, and manage its own modes of operation. "We refer to the capacity to control these internal modes of operation as self-regulation."
- Simulative learning: Training from trajectories generated by an internal world model rather than the real environment. "Simulative learning is particularly valuable when real-world trial-and-error is dangerous, expensive, or slow."
- Simulative planning: Planning by proposing actions and predicting their consequences using a world model. "simulative planning through an internal world model (System~II) alongside reactive action (System~I)"
- Simulative reasoning: Deliberation that uses a world model to simulate outcomes of candidate actions before acting. "We refer to this form of deliberation as simulative reasoning (a form of System~II reasoning)"
- System I: Fast, reactive execution mode for immediate action without heavy deliberation. "reactive action (System~I)"
- System II: Slow, deliberate reasoning mode used for simulative planning. "We refer to this form of deliberation as simulative reasoning (a form of System~II reasoning)"
- System III: The regulation layer that decides when and how to deliberate or learn (the configurator). "via a learned configurator (System~III)"
- Trajectory distribution: The probability distribution over sequences of states and actions induced by the agent and environment. "the interaction between π and μ induces a trajectory distribution:"
- Transition distribution: The environment’s stochastic dynamics mapping current state-action to next state. "The environment defines a transition distribution p_μ(s_{t+1} \mid s_t, a_t)"
- Value function: Expected discounted cumulative reward from a state under a policy and goal. "also known as the value function"
- Vision-Language-Action (VLA): Architectures that jointly handle perception, language, and control for embodied tasks. "increasingly adopt vision-language-action (VLA) architectures"
- World action models (WAMs): Architectures that jointly predict future states and actions within a shared model. "world action models (WAMs; e.g., DreamZero~\cite{ye2026dreamzero}) jointly predict future states and actions"
- World model: A learned model of environment dynamics used to predict next states and simulate outcomes. "the agent model must be kept functionally distinct from a world model"
Collections
Sign up for free to add this paper to one or more collections.