- The paper presents AMDP, a novel algorithm that reformulates maximum entropy RL as a stochastic optimal control problem for efficient diffusion policy training.
- It employs reciprocal adjoint matching and simulation-free Gaussian bridge sampling to drastically reduce memory usage and computational costs.
- AMDP demonstrates superior sample efficiency and stability on 63 continuous control tasks, leveraging trust-region regularization and robust architectural adaptations.
Scalable Maximum Entropy RL for Diffusion Policies via Adjoint Matching
Introduction and Motivation
Diffusion-based policy representations have emerged as a promising framework for capturing complex, multimodal action distributions in deep RL. Despite their representational expressiveness, conventional training methods for diffusion policies in online RL, such as score matching and reverse KL divergence minimization, face significant bottlenecks in terms of memory usage, computational efficiency, and theoretical limitations. Score-based methods are inapplicable without static datasets, while backpropagation through the full diffusion chain (as required for reverse KL) incurs untenable memory costs for high-dimensional control, and importance weighting approaches scale poorly in high dimensions.
This work introduces the Adjoint Matching Diffusion Policy (AMDP), a novel algorithmic framework for maximum entropy RL with diffusion policies, grounded in stochastic optimal control (SOC) and adjoint matching (AM). AMDP achieves scalable, simulation-free training by leveraging reciprocal adjoint matching, thereby circumventing direct backpropagation through the diffusion process and eliminating the need for explicit likelihood estimation or importance sampling.
The Adjoint Matching Diffusion Policy Framework
The core insight of AMDP is to reformulate maximum entropy policy optimization for diffusion models as a stochastic optimal control problem. The approach builds on the fact that, under maximum entropy regularization, the policy improvement target is an energy-based distribution proportional to exp(Q(s,a)/α). Diffusion models parameterize this policy implicitly via the terminal distribution of a controlled stochastic process.
The training procedure leverages reciprocal adjoint matching, which provides a fixed-point regression loss whose unique minimizer corresponds to the optimal control generating the desired marginals. Efficient, simulation-free training is enabled by (1) storing only the terminal states of the forward SDE, (2) sampling intermediate states via Gaussian bridges (negating the need for full SDE rollout), and (3) circumventing the computation of action likelihoods.
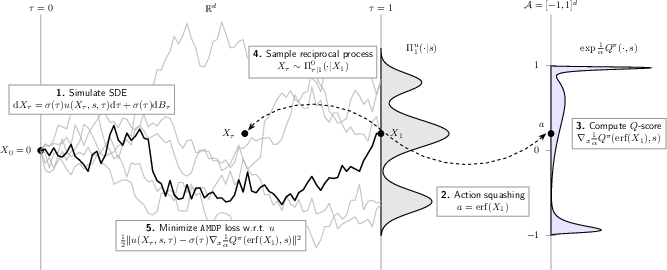
Figure 1: Overview of the AMDP training pipeline, detailing forward SDE sampling, error function squashing to action space, Q-score target construction, simulation-free bridge sampling, and vector field optimization without pathwise backpropagation.
An important architectural adaptation is the introduction of error function (erf) squashing to map unconstrained outputs of the diffusion process into valid action bounds. This bijective transformation, with a state-aligned scaling factor, ensures numerical stability and leads to a cancellation of the Jacobian term in the AMDP objective, simplifying gradient computation. Furthermore, a trust-region penalty is incorporated into policy updates, enforcing stable and monotonic improvement without sacrificing the theoretical properties of the underlying SOC formulation.
Empirical Evaluation
AMDP is benchmarked extensively on 63 continuous control environments from MuJoCo Playground, ManiSkill3, and HumanoidBench, evaluated in both on-policy and high-dimensional off-policy RL regimes. The evaluation policy is based on best-of-N (N=16) sampling, where applicable, for stochasticity reduction.
AMDP matches or exceeds the data efficiency and final performance of leading baselines:
- On MuJoCo Playground DMC, AMDP matches DIME and reaches asymptotic performance more rapidly than REPPO and PPO.
- In high-dimensional humanoid locomotion, AMDP converges faster in the early regime and, when enhanced with best-of-N sampling, outperforms all baselines.
- For object-centric manipulation in ManiSkill3, AMDP, DIME, and REPPO perform comparably, whereas PPO and SPO underperform.
- In contact-rich, high-DOF HumanoidBench domains, AMDP outperforms all other diffusion baselines, with particularly strong gains even without stochasticity reduction.
AMDP is evaluated on challenging dog and humanoid tasks from DMC suites. It converges as fast as, and often outperforms, DIME and QSM methods, demonstrating that the adjoint matching loss provides a competitive and robust off-policy learning signal for diffusion RL.
Ablation Studies
Controlled ablation analyses show that:
- AMDP's performance is not sensitive to SDE choice; switching to an Ornstein-Uhlenbeck process does not degrade results.
- Replacing erf squashing with tanh has minimal effect in low dimensions but significantly impairs optimization in high-dimensional tasks.
- Trust-region regularization is critical; disabling it causes marked instability and collapse in both low- and high-dimensional settings.
- AMDP scales efficiently with the number of diffusion steps; simulation-free bridge sampling enables cost-effective model scaling.
- AMDP remains computationally competitive with highly engineered Gaussian baselines (≈10% overhead) and is orders of magnitude faster than chain backpropagation approaches for large diffusion step counts.
Theoretical Implications and Practical Impact
AMDP's approach offers several substantial advances over existing methodologies:
- Simulation-Free Optimization: Training requires only the terminal state of the forward process and simulation-free Gaussian bridge sampling for intermediate states, eliminating the need for backpropagation through the diffusion chain. This dramatically reduces both memory footprint and wallclock cost.
- Theoretical Guarantees: The adjoint matching loss is a contractive fixed-point operator with a unique minimizer, obviating the asymptotic and finite-time biases in common Langevin and score-matching methods.
- Robustness to SDE Architecture: AMDP's framework accommodates a wide range of diffusion process architectures, including memoryless Ornstein-Uhlenbeck priors, facilitating offline-to-online RL transfer scenarios.
- Direct Scaling to Large Architectures: Memory efficiency enables scaling the actor model by two orders of magnitude (≥100M parameters) without prohibitive training cost.
- Trust-Region Regularization: Rigorous integration of trust-region constraints into the regression objective ensures stable policy iteration and reliable improvement in nonstationary environments.
Implications for Future AI Research
The demonstrated scalability and robustness of AMDP have practical implications for deploying high-capacity, expressive control policies in real-world robotics, manipulation, and locomotion domains. Theoretically, the bridging of stochastic optimal control and diffusion-based RL enables the exploration of novel, memoryless policy representations for online learning. Future research directions could focus on:
- Generalizing AMDP to discrete and hybrid action spaces via memoryless SDE constructions or Ornstein-Uhlenbeck extensions.
- Unifying diffusion policy pretraining and iterative online improvement in a single memoryless SOC-driven training loop.
- Extending trust-region adjoint matching to multi-agent and hierarchical RL scenarios requiring simultaneous expressive policy modeling and stable improvement.
- Investigating the interplay between kinetic energy regularization, entropy lower bounds, and causal credit assignment in continuous-time RL.
Conclusion
The AMDP algorithm constitutes a theoretically rigorous and computationally efficient methodology for scalable maximum entropy RL with diffusion policies. By leveraging reciprocal adjoint matching and integrating architectural choices for action squashing and trust-region regularization, the approach achieves benchmark-leading sample efficiency and robustness across a diverse set of tasks. AMDP demonstrates that highly expressive, multi-modal diffusion models can be rendered tractable for online RL using mathematically principled, simulation-free optimization, paving the way for broader deployment and continued innovation in generative RL policy architectures (2606.22630).

