- The paper introduces the MMDP framework that captures the coupled increase in information and reduction in feasible actions as decision stages progress.
- The authors derive an expiring-action priority principle, allowing stage-specific optimization and reduced exploration complexity.
- Empirical results show accelerated learning, higher rewards, and improved sample efficiency compared to traditional flat MDP models.
Maturing Markov Decision Processes: Structural Asymmetry in Sequential Decision Making
Sequential decision problems in operational domains—such as inventory control, resource allocation, and financial management—often display asymmetric trajectories: as a decision cycle advances, available information for decision making is incrementally refined, while the set of feasible actions contracts due to operational deadlines, commitments, or resource constraints. Classical MDP formulations typically encode this structure via enlarged stage-dependent state descriptions and action masks, treating the evolution as auxiliary bookkeeping. This paper introduces Maturing Markov Decision Processes (MMDPs), formally capturing the coupled monotonic increase in information and contraction of the action space within a finite-horizon process.

Figure 1: MMDP schematic; early stage with high flexibility but low information, later stage with more information but reduced action space.
MMDPs are defined by stage-indexed state and action spaces {Sn} and {An}, transition kernels, rewards, monotonic information mappings, and mechanisms governing progression through stages. The critical structural property is the alternating refinement of state representation and diminishment of feasible actions, which are demanded for non-trivial stage separation. This is formally embodied in strict inclusions Sn≺Sn+1 (information) and An⊃An+1 (feasibility).
Structural Consequences and Theoretical Principles
The asymmetry between information evolution and action contraction leads to a fundamental trade-off: whether to act early amid uncertainty for maximal flexibility, or defer action for improved signals at the cost of reduced optionality. The exploration burden for RL is sharply decreased when modeling this structure, as shown by structural hardness proxies; if action shrinkage outpaces information increase (αβ<1), the effective exploration burden O(1−αβS0A0) remains bounded, compared to the combinatorial explosion in flat MDPs.
A central theoretical outcome is the expiring-action priority principle: for stages where persistent actions can be deferred without sacrificing optimality, the stage-level optimization can focus entirely on expiring actions. This creates a sharp reduction in the decision space, charging only for urgent decisions, with effective proxy O(1−αβ(1−β)S0A0)—formally justifying the decomposed interface.
Structure-Aware Reinforcement Learning Framework
Leveraging MMDP structure, the authors propose a structure-aware RL framework built on three pillars:
- Stage-aware Policy Design: Parameterizing policies as πθ(a∣s,n), conditioning explicitly on stage index to accommodate varying state representations and action sets. Representations are shared, but actor heads are stage-specialized for stage-local action selection.
- Expiring-Action Abstraction: Following the theoretical principle, policy interfaces expose only the expiring actions Dn. For hybrid-action spaces (e.g., cash transfers with discrete edges and continuous amounts), the abstraction retains the discrete choice, delegating parameter selection to a state-conditional executor.
- Search-Augmented Learning with Distillation: The reduced stage-local action space facilitates local search around policy proposals. Search selects K candidate actions for rollouts; improved decisions are distilled into the policy, combining RL loss and supervised distillation to accelerate convergence and enhance final outcomes.
Empirical Results and Benchmarks
Experiments span three settings: a controlled multi-supplier replenishment benchmark, simplified cash-management environments, and a production-scale cash-management simulator.
Staged Replenishment Benchmark
This setting evaluates replenishment from suppliers with asymmetric flexibility and cost. Two stages per cycle: early stage with options for regular and flexible suppliers, later stage with only flexible supplier and refined forecasts.
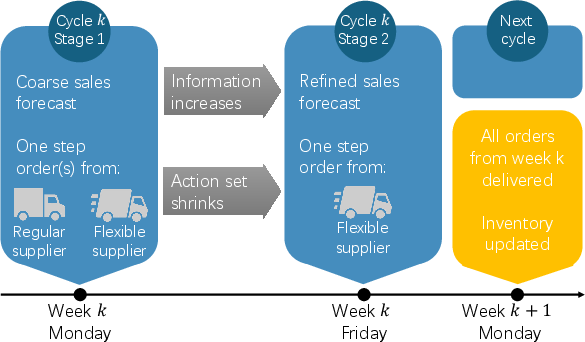
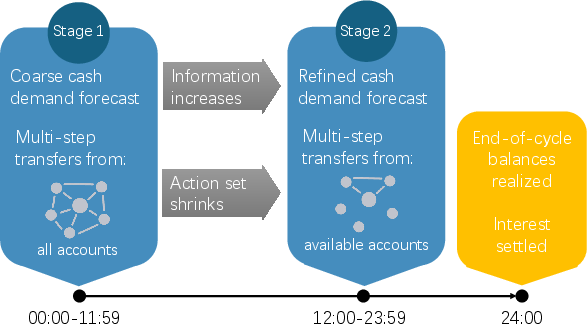
Figure 2: Replenishment problem structure, staged with expiring supplier decisions.
Learning curves across PPO and DQN show that MMDP modeling starts from higher rewards, accelerates early learning, and achieves greater sample efficiency compared to flat MDP parameterizations.
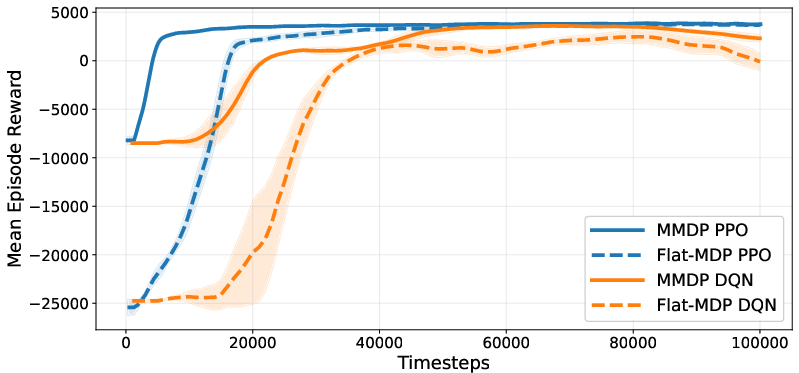
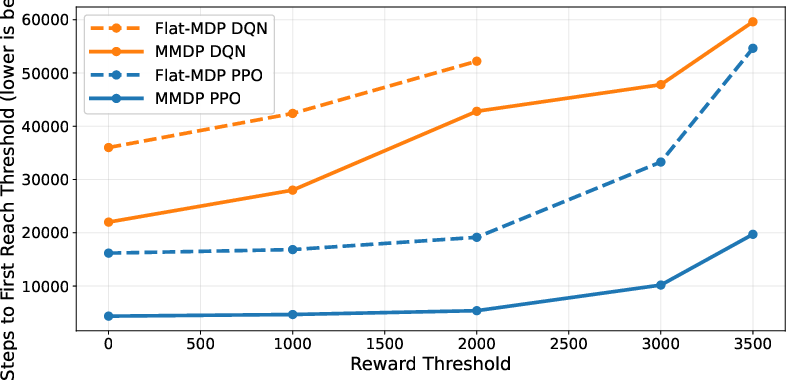
Figure 3: Comparative learning dynamics under flat vs. MMDP parameterizations, highlighting accelerated learning and improved sample efficiency for MMDP.
Cash Management Benchmarks
Five-account and ten-account settings are designed to scale the complexity of cash rebalancing across operational accounts. Each daily cycle unfolds over two stages, with shrinkage in the feasible transfer graph.
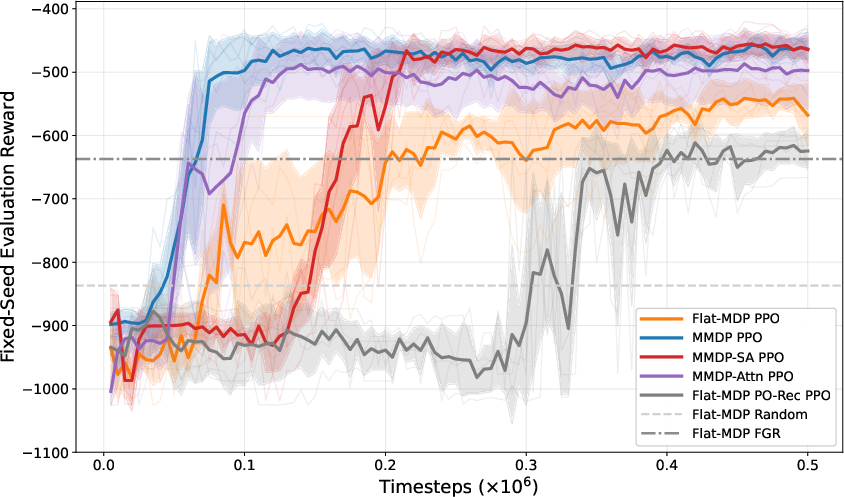
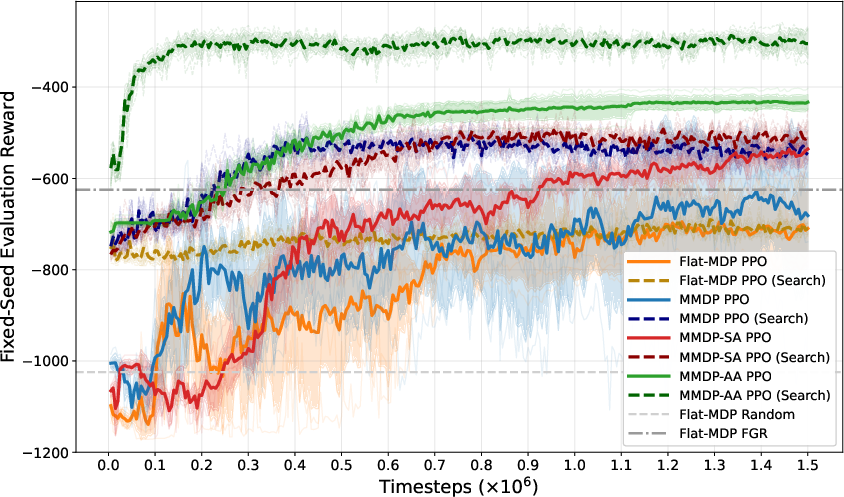
Figure 4: Five-account cash management setting; MMDP-based policies outperform flat baselines.
Flat-MDP PPO lags explicit MMDP-based policies (stage-aware, attention-based, and action-abstraction variants), which exhibit rapid learning and higher final rewards. Recurrent partial-observation baselines, while competitive, are insufficient compared to explicit staged modeling—demonstrating that generic memory doesn't substitute for structural modeling.
Scaling to ten accounts, the action space grows combinatorially, further emphasizing the practical impact of staged modeling, expiring-action abstraction, and search augmentation. Search-improved policies (MMDP-AA Search) attain highest evaluation rewards, with gaps over strong heuristic and LLM-based baselines.
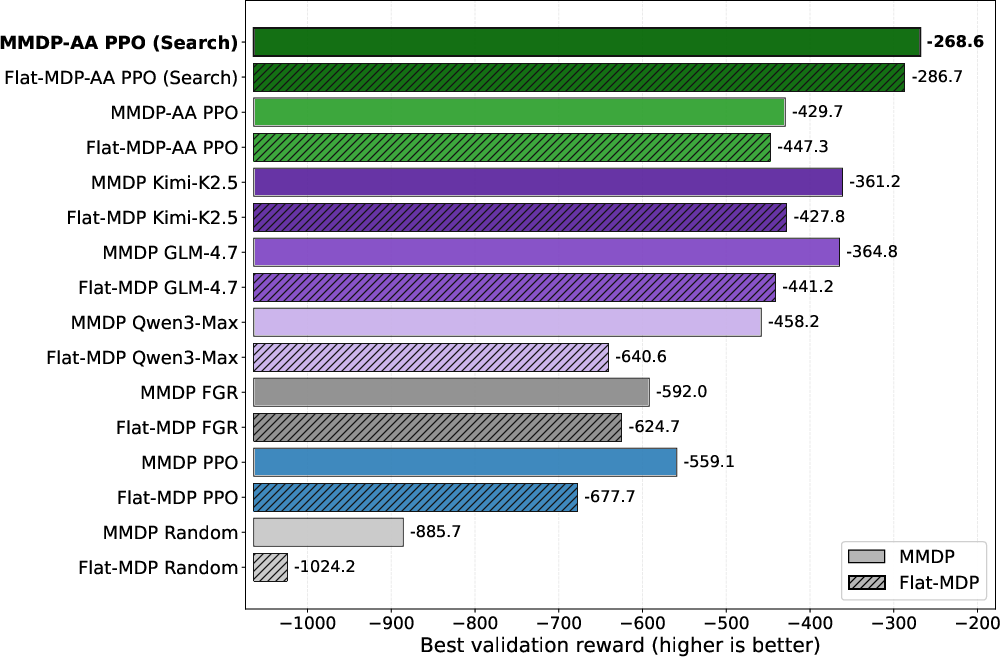
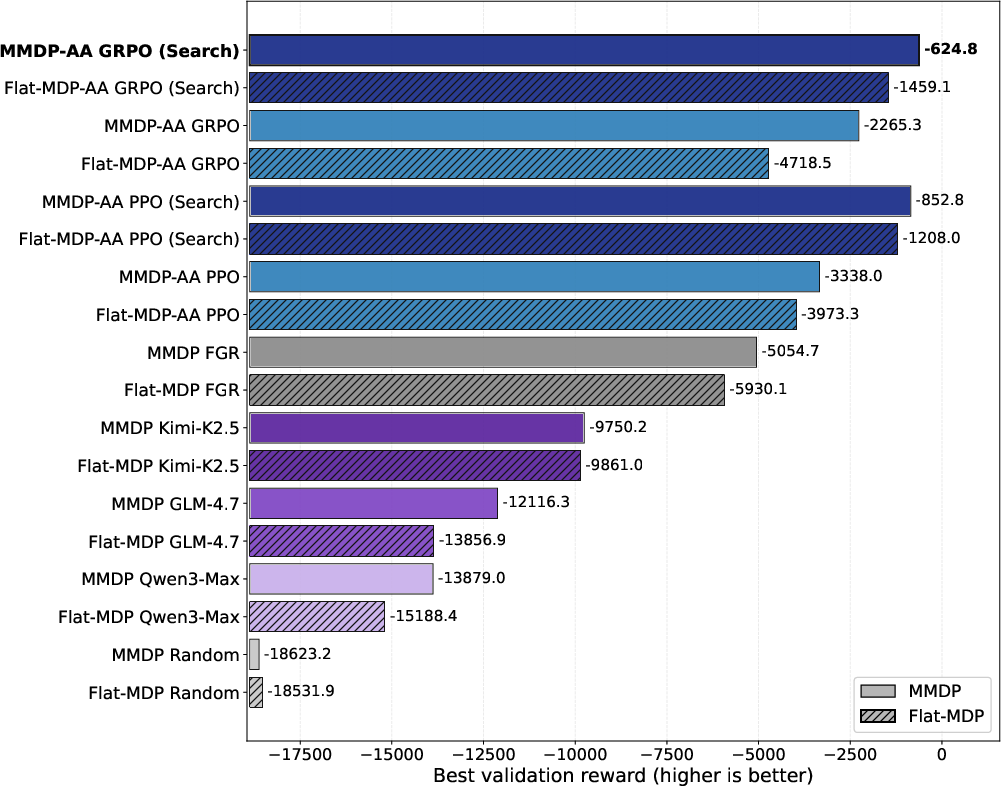
Figure 5: Ten-account benchmark results; structure-aware RL with abstraction and search achieves superior performance, widening with problem scale.
Production-Scale Simulator
In the high-fidelity simulator, MMDP modeling combined with group-relative normalization (GRPO) improves over flat formulations, both in learning and final policy scores. Direct-LLM baselines benefitted from MMDP-style prompts but remained below RL policies. Real-world backtests evidenced a 5.3% revenue improvement and an 18.6% greater adoption rate for model-generated recommendations post-deployment.
Implications and Theoretical Considerations
MMDPs isolate a recurring operational motif—the nested interplay between information refinement and action expiration—which is ubiquitous across domains that require irreversible commitment and sequential adjustment. Making this structure explicit affords sharper modeling, more tractable search, and substantial algorithmic improvements, especially as combinatorial decision spaces scale.
Expiring-action abstraction is exact under assumptions compatible with the expiring-action priority principle. In realistic settings when persistent and expiring actions interact via resource couplings or feasibility constraints, the abstraction is a structured approximation.
Practically, the framework generalizes beyond RL, as evidenced by improvements even in direct-LLM baselines prompted with MMDP-stage-aware interfaces. Theoretically, the insights extend to structured non-stationarity, continual learning, and hybrid action interfaces, suggesting future integration with advances in adaptive RL or LLM-based decision agents.
Conclusion
The MMDP formalism addresses a persistent structural asymmetry overlooked in classical MDPs, refining sequential decision modeling where information incrementally matures while feasible actions contract. Structure-aware RL leveraging MMDP principles yields accelerated learning, improved sample efficiency, and superior final policy quality, with empirical gains amplifying in large-scale operational domains. The theoretical foundations, interface abstractions, and algorithmic augmentations proposed offer a versatile toolkit for practitioners and researchers confronting structurally asymmetric sequential control.

