- The paper demonstrates that replacing fixed linear connections with learnable univariate functions enhances model expressivity and interpretability.
- It introduces a unified framework supporting both B-spline and Gaussian RBF basis expansions, enabling controlled architectural experimentation and computational tradeoffs.
- Empirical evaluations on the California Housing dataset show competitive predictive accuracy and faster inference times with flexible ablation options.
KANLib: A Modular, Extensible, and Efficient Implementation of Kolmogorov-Arnold Networks
Introduction
Kolmogorov-Arnold Networks (KANs) represent a significant architectural shift from multilayer perceptrons (MLPs) by substituting fixed-weight linear connections with learnable univariate functions. This edge-wise parameterization, inspired by the Kolmogorov-Arnold representation theorem, results in models with theoretically enhanced expressivity and improved interpretability compared to standard MLPs. However, research progress on KANs has been throttled by inconsistent implementations, high computational overhead, and a lack of extensible frameworks. The KANLib system seeks to address these limitations through a unified, modular, and computationally efficient PyTorch-based library that supports the core KAN paradigms as well as architectural experimentation.
In KANs, each connection between input and output neurons is parameterized by a learnable univariate function ϕi,j. Typically, these functions are implemented as linear combinations of spline or radial basis function (RBF) expansions, enhancing the capacity to capture non-linear dependencies per-edge. The KANLib framework supports both B-spline and Gaussian RBF basis expansions, which are central to both interpretability and computational performance.
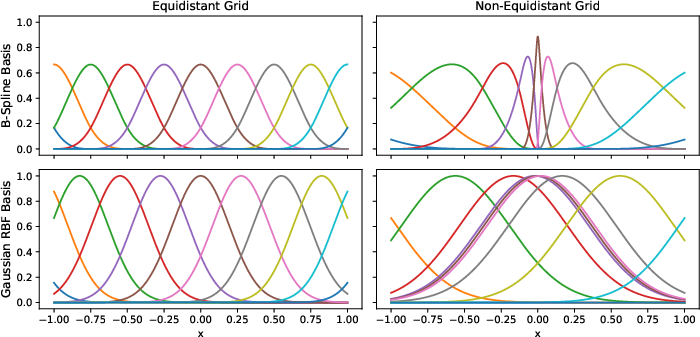
Figure 1: B-spline (left) and Gaussian RBF (right) basis functions, demonstrating their behavior on equidistant (top) and non-equidistant (bottom) grids. Gaussian RBFs only approximate the local support structure of B-splines on equidistant grids.
The difference between B-spline and Gaussian RBF basis is more than an implementation detail; it directly influences expressivity, computational bottlenecks, and the feasibility of adaptive grid mechanisms. Gaussian RBFs, as adopted in FastKAN and now supported in KANLib, offer significant acceleration but their approximation fidelity suffers outside equidistant grids—a limitation not present in spline-based approaches.
Survey of Existing Implementations and Spline Computation Optimizations
Three major KAN variants precede KANLib:
- PyKAN: The reference implementation, leveraging B-spline expansions coupled with a SiLU-based residual branch. PyKAN is designed for interpretability and symbolic regression but exhibits prohibitive computational overhead for large architectures or datasets.
- EfficientKAN: Focused on computational optimization, EfficientKAN reduces memory and compute costs via direct B-spline basis evaluations and fused operations, trading away some intermediate activations (and thus feature richness) for higher throughput.
- FastKAN: This implementation frames KANs as special RBF networks by replacing splines with Gaussian RBFs. This leads to an order-of-magnitude speedup and a reduced parameter set, at the expense of adaptive grid rescaling—compensated via Layer Normalization.
KANLib synthesizes core ideas and optimizations from all three, allowing for controlled architectural and computational tradeoffs within a unified API.
KANLib Architecture and Feature Set
KANLib is built for extensibility and modularity. All core linear layers expose fine-grained configuration for disabling or enabling the spline weighting and residual branches independently, supporting various ablations. Importantly, KANLib maintains feature parity between B-spline and RBF implementations where mathematically justified, e.g., adaptive grid rescaling is conditionally supported for GRBF layers, restricted to equidistant grids given the analytic limitations demonstrated in FastKAN.
Key architectural features include:
- Extensible basis function support: Switchable B-spline and Gaussian RBF representations.
- Adaptive grid rescaling and extension: Mechanisms for dynamic grid adaption, addressing input domain drift and grid resolution refinement during training.
- Residual branch and spline weighting configuration: Enabling more granular control and ablation.
- Layer normalization integration: Available for both basis types to facilitate stable training, especially critical when adaptive grid rescaling is unavailable (as in GRBFs with non-uniform grids).
- Visualization and interpretability tools: Infrastructure to analyze learned univariate functions and network topology.
Empirical Evaluation: Predictive and Computational Cost Analysis
KANLib and the reference implementations are benchmarked on the California Housing regression dataset, under rigorously controlled experimental conditions using two-layer architectures. Both B-spline (3rd-order, grid of size 10 on [−1,1]) and GRBF representations are compared; identical training procedures ensure faithful comparison.
Empirical findings:
- Predictive accuracy: KANLib's B-spline model achieves RMSE of 0.5376±0.0044 (R2=0.7852±0.0035), slightly outperforming PyKAN and EfficientKAN. KANLib's GRBF variant matches FastKAN's predictive accuracy within 0.6% RMSE.
- Inference time: B-spline KANLib models run ∼32–33% faster than PyKAN, nearly matching EfficientKAN. GRBF models provide an additional ∼43–50% speedup over B-splines, with FastKAN remaining the fastest due to its minimalistic implementation.
Critically, KANLib introduces only minor computational overhead compared to the most optimized existing implementations while offering a superset of features and architectural flexibility. Developers can conduct fine-grained ablation studies on spline weighting and residual branches, with only small impacts on accuracy but potentially meaningful reductions in parameter count and inference time.
Architectural Ablations and KAN Variant Exploration
KANLib enables systematic exploration of KAN architectural variants:
- Default: Spline + residual branch + spline weighting (full expressivity and highest param count).
- No Residual: Residual branch removed.
- No Spline Weight: Spline weighting removed.
- Plain: Both residual branch and spline weighting removed (most minimal; only spline computations).
These ablations consistently produce only minor variations in predictive accuracy (typically less than 2–4% relative difference in RMSE), while offering proportional reductions in parameter count and computational footprint. This highlights the robustness of KAN architectures to architectural simplification, supporting the use of lightweight variants in resource-constrained settings.
Implications and Future Directions
KANLib resolves critical bottlenecks in KAN research by enabling rapid prototyping, reproducibility, and architectural innovation. Methodologically, it validates that core KAN principles—learnable univariate-function-based edge parameterization and grid-based spline or RBF expansions—are not inherently computationally expensive provided careful engineering (basis evaluations, grid management, and operation fusion).
From a theoretical perspective, the ability to flexibly examine the impact of various architectural components (e.g., residuals, grid adaptation) may inform both the neuroscience of distributed representations and the interpretability of deep learning systems. Practically, KANLib supports integration as drop-in replacements for linear layers within generic PyTorch models, facilitating adoption in hybrid systems.
The roadmap includes further computational optimization of the Gaussian RBF path, particularly in the context of adaptive grid rescaling, and the implementation of 1D convolutional KAN layers, which is a natural extension given recent work on convolutional KANs for time-series and image modalities.
Conclusion
KANLib delivers a comprehensive, modular, and performant research platform for KAN development. It replicates the predictive and computational properties of existing implementations while enabling extensive architectural experimentation. The framework can serve as a foundation for future work not only on scaling and speeding up KANs, but also on understanding the relationship between basis function choice, non-linearity allocation, and network interpretability in structured deep learning systems.