- The paper introduces a mean-field theory demonstrating that deep transformers perform adaptive, distributed inference via function vectors.
- It shows that depth and nonlinear MLP routing critically enhance performance in hierarchical latent settings, particularly reducing MMSE loss.
- Empirical experiments with Gaussian and tree priors validate that sequential, multi-layer strategies outperform single-layer approaches in contextual tasks.
Theoretical Foundations: Distributed Inference in Layered Architectures
The paper presents a formal model of deep transformer architectures as mean-field interacting systems that support distributed inference under constraints of communication bandwidth, locality, and depth. The model is motivated by empirical observations that transformers can adapt to a novel context sequence in a single forward pass—a phenomenon termed in-context learning. In this paradigm, internal state representations termed "function vectors" (or task vectors) are constructed across layers to infer latent contextual variables at increasingly fine granularity.
Central to the theoretical framework is the concept of adaptive distributed inference. Given a collection of N coupled random variables (tokens) governed by a latent context variable, the multi-layer transformer is cast as a sequential experimental design strategy. Each layer computes a pooled function vector statistic, incrementally accumulating relevant information about the latent context. Formally, the communication scheme involves layer-wise embedding functions and pooling, and the inference at each layer updates a state variable that integrates all previous layer statistics. The optimal layerwise embedding is derived through dynamic programming, reflecting adaptive measurement selection analogous to Bayesian optimal experiment design.
Mapping this theory to transformer components, attention blocks pool information globally, while MLP blocks serve the dual function of encoding routed statistics and decoding final predictions. Residual streams separate token information from statistics, enforcing a communication bottleneck on the latent space and distinguishing between original token representation and accumulated function vectors.
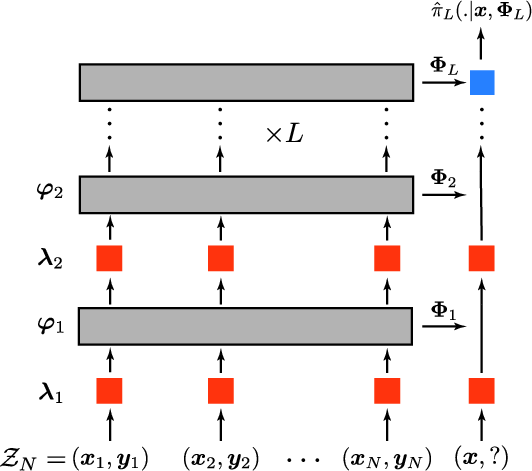
Figure 1: Model schematic depicting information compression into function vectors across transformer layers, with local nonlinear embedding and global pooling.
Empirical Analysis: Hierarchical Contexts and Architectural Depth
The theory is applied to a synthetic in-context regression task where contextual tokens are generated under both Gaussian and hierarchical "tree" structured priors. Numerical experiments utilize constrained linear attention transformers—architectures where communication channels per layer are tightly controlled and MLP blocks modulate layerwise routing.
For the Gaussian prior, the model demonstrates that depth and MLP-induced nonlinearities confer no advantage: both adaptive, multi-layer strategies and non-adaptive, single-layer strategies yield equivalent minimum mean squared error (MMSE) loss. This aligns with the prediction that the Gaussian structure is fully captured by selecting top principal components from the covariance, irrespective of adaptivity or layerwise routing.
In contrast, for the tree prior—a hierarchical context where regression vectors are structured according to paths on a balanced binary tree—the adaptive multi-layer strategy outperforms non-adaptive measurement. Here, depth enables the transformer to sequentially resolve sub-coordinates along the tree path, exponentially improving MMSE loss up to a cutoff determined by noise and the communication budget. Model A (deep transformer, channel dimension 1 per layer, with MLP embedding and decoding) achieves significantly lower MMSE loss than Model B (single-layer, channel dimension M), demonstrating the emergence of adaptive inference based on function vector routing.
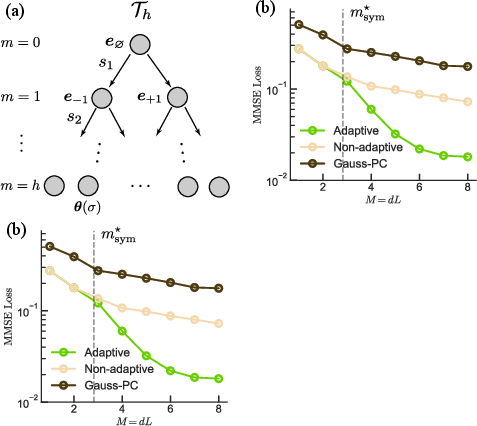
Figure 2: MMSE loss comparison for adaptive and non-adaptive strategies under tree-structured prior, showing depth-based advantage.
The paper constructs and details three model configurations for empirical evaluation: (A) multi-layer deep transformer with MLP blocks and channel dimension d=1 per layer; (B) one-layer transformer with channel dimension M and identical MLPs; (C) one-layer linear attention transformer with channel dimension M and no feedforward blocks.
Model C is shown to intrinsically implement projection onto top eigenspace of the prior covariance, matching theoretical optimality in the Gaussian case. However, in hierarchical contexts, Model A's depth and layerwise adaptivity notably surpass Model B/C, suggesting that depth and nonlinear routing are necessary to implement more general adaptive inference strategies in hierarchically structured latent spaces.
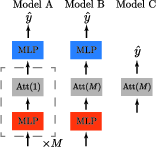
Figure 3: Schematic of three model configurations tested—multi-layer with MLPs, one-layer with MLPs, and one-layer without MLPs.
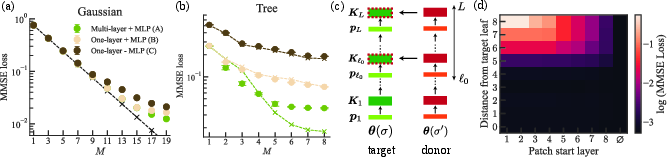
Figure 4: Empirical MMSE loss of model configurations on Gaussian and tree priors, with causal key-patching experiment validating function vector adaptation.
Mechanistic Validation: Function Vector Causality in Contextual Adaptation
A crucial mechanistic experiment involves key-patching: replacing the dynamic key matrices of a trained model in a given context with those from another context (donor leaf) at varying layers, and measuring MMSE impact. The results show strong dependence of prediction loss on tree distance and intervention layer depth, substantiating that function vectors encode compressed representations of the context and that adaptive inference is mediated by layerwise routing of statistics.
This causal experiment aligns with empirical findings in LLMs, where function vectors or task vectors robustly encode contextual information and can be patched or manipulated to modulate downstream predictions [todd_function_2023] [hendel_context_2023] [gibson_distinct_2026].
Broader Implications and Future Directions
The work situates its framework within ongoing efforts to mechanistically understand in-context learning as implicit Bayesian inference [xie_explanation_2022] [muller2021transformers]. It reconciles algorithmic circuit studies—where simple attention-based mechanisms suffice for some classes of function—with middle-layer function vector representations found empirically across large models. The explicit role of MLP blocks is clarified: not merely nonlinear feature projection, but nonlinear routing in a sequential adaptive procedure.
The theory excludes softmax attention, focusing on linear pooling under permutation invariance. While softmax attention is crucial in associative memory retrieval and context-sensitive denoising, the pooling-based operation proposed here suffices for exchangeable scenarios. The synthesis of circuit-level, probabilistic, and mean-field perspectives offers a foundational bridge, with potential for future integration with associative memory models, modular circuit analyses, and the study of task vector emergence and manipulation [dong_understanding_2025] [yin2025attention] [han2024emergence].
Practically, the findings motivate architectural design strategies for transformers in domains where hierarchical or non-Gaussian latent structure is critical, such as materials discovery, protein modeling, and complex signal inference—where depth and MLP routing can be exploited for adaptive in-context inference.
Conclusion
This paper provides a rigorous theoretical and empirical framework for understanding the operation of function vectors and adaptive inference in deep transformers. The results establish that architectural depth and feedforward nonlinearity enable transformers to implement distributed, sequential adaptive inference, especially in the presence of hierarchical latent context structure. Numerical experiments and causal interventions validate theoretical predictions, clarifying the mechanisms by which transformers compress and route contextual information across layers. Future research will extend these principles to richer latent structures and integrate permutation-invariant pooling with memory-based attention mechanisms, advancing both the theory and practical design of transformer-based systems.

