- The paper introduces a novel adapter module that integrates Mamba state-space models with bottleneck projections for parameter-efficient transfer learning in speech and audio.
- It demonstrates superior classification and ASR performance, achieving up to 89.85% accuracy and improved WER with less than 20% of baseline parameters.
- Ablation studies confirm the critical role of the Mamba block and shared projections, highlighting the efficiency gains in low-resource settings and temporal modeling.
MambAdapter: Efficient Mamba-Based Adapters for Transfer Learning in Speech and Audio
Architectural Design and Methodology
MambAdapter introduces a novel adapter module for parameter-efficient transfer learning (PETL) in the context of speech and audio processing. The architecture augments standard low-rank bottleneck adapters with Mamba blocks—a selective state-space model (SSM) offering linear-time sequence modeling. The adapter construction leverages shared linear projection matrices across all transformer layers and injects lightweight Mamba blocks within the bottleneck, enabling efficient modeling of temporal dependencies in audio data. The architectural integration allows Mamba's recurrence and structured convolution to operate within a low-dimensional subspace, capturing long-range temporal context without significant parameter overhead.
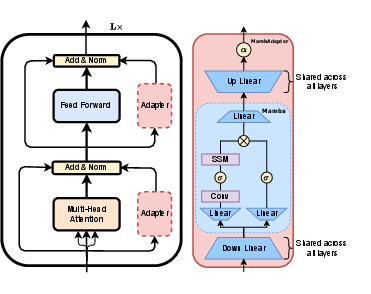
Figure 1: A Transformer block with inserted adapter modules (dashed boxes) and the internal structure of MambAdapter, featuring bottleneck projections and a Mamba block.
The use of a learnable scaling factor (α) per layer provides fine-grained control over the adapter’s contribution, while parameter sharing regularizes the adaptation process and significantly reduces trainable parameters. The theoretical motivation follows from the compressibility of SSMs, which concentrate temporal information into compact state vectors and are robust to dimensionality reduction—a property well aligned with low-rank adapter settings.
Experimental Results and Comparative Analysis
The evaluation spans two domains: audio/speech classification and automatic speech recognition (ASR), involving tasks on benchmark datasets (ESC-50, UrbanSound8K, GSC, FSC) and multilingual ASR scenarios using Whisper on low- and medium-resource languages. For parameter parity, adapter ranks are matched to baseline methods.
Classification Performance: Under the Houlsby adapter configuration, MambAdapter yields an average accuracy of 89.85%, outperforming baseline Conformer and Bottleneck adapters, as well as LoRA, while using less than 20% of Conformer’s parameters. Notably, MambAdapter achieves the highest accuracy on ESC (87.55%)—even exceeding full fine-tuning.
ASR Performance: MambAdapter achieves a mean word error rate (WER) of 49.9% across five languages, compared to Bottleneck (50.7%), Conformer (55.7%), and LoRA (57.3%). Full fine-tuning retains lower WER (45.18%), but adapters bridge this gap while utilizing just 0.45% of Whisper’s parameters, substantiating the efficacy of PETL in resource-constrained scenarios.
Scaling and Ablation Studies
The paper analyses the relationship between performance and parameter budget by varying adapter ranks on the GSC dataset. MambAdapter outperforms all baselines below 500k trainable parameters, with accuracy gains of 0.5-4% in low-resource settings. Conformer overtakes beyond this threshold, but with diminishing returns.
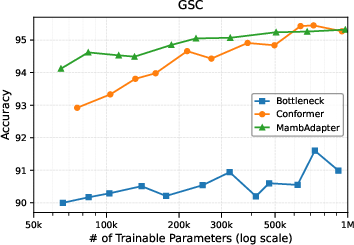
Figure 2: Scaling trend for adapter PETL methods on GSC, demonstrating superior accuracy for MambAdapter in the low-parameter regime.
Ablation studies highlight that the removal of the Mamba block precipitates a substantial accuracy drop (up to 30% on FSC), confirming its critical role for complex temporal tasks. The per-layer scaling factor (α) provides consistent but modest gains. Disabling projection sharing results in marginal performance increases at a fourfold parameter cost, indicating regularization benefits of shared projections.
Mamba Hyperparameter and Efficiency Analysis
The effect of Mamba hyperparameters is evaluated for ASR. Increasing kernel size increases WER, suggesting that excessive local context modeling is detrimental in this regime. State dimension (dstate) does not monotonically enhance performance, with an optimal interval (20–40) for memory capacity. The expansion factor (expand) consistently improves WER by ~1% per step.
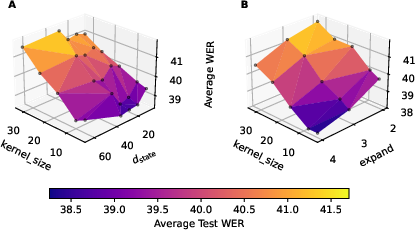
Figure 3: WER ↓ averaged across expand (left) and dstate (right), revealing optimal hyperparameter regions for Mamba adaptation.
Latency and memory profiling shows that MambAdapter incurs a marginal increase in inference time and GPU usage, especially for streaming workloads. However, the overhead is amortized in batch and offline scenarios, making it more suitable for non-streaming applications.
Implications and Future Directions
MambAdapter demonstrates that integrating Mamba blocks within low-rank adapters substantially advances the efficiency-performance trade-off for transfer learning in speech and audio foundation models. The approach achieves competitive results with significantly reduced parameter budgets, offering practical benefits for on-device and low-resource adaptation. On the theoretical front, this work validates the compressibility and scalability of SSMs within bottleneck regularization frameworks, providing empirical grounding for future hybrid architectural explorations.
Potential directions include leveraging MambAdapter in larger-scale multilingual and multi-task settings, exploring adaptive insertion strategies, and integrating more advanced hyperparameter search or compression modules. Continued investigation into the interplay between state-space models and transformer-based adaptation techniques may yield further improvements in efficiency and generalization for long-context sequence modeling tasks in speech and audio.
Conclusion
MambAdapter provides a lightweight, parameter-efficient PETL mechanism that combines Mamba state-space modeling with shared projection bottlenecks for effective adaptation of speech and audio foundation models. The achieved performance, especially under stringent parameter constraints, marks a decisive step in optimizing transfer learning efficiency and substantiates the synergy between SSMs and adapter-based techniques in sequential signal domains.