- The paper presents a neural, denoising-based method that reformulates local Riemannian metric estimation as a regression problem via the carré du champ operator.
- It demonstrates up to 400× faster inference and notable memory savings compared to traditional k-NN estimators on high-dimensional datasets.
- The method yields stable latent space geometry and smooth on-manifold interpolation, offering practical benefits for generative and representation learning.
Riemannian Metric Matching for Scalable Geometric Modeling of Distributions
Introduction and Motivation
The challenge of extracting intrinsic geometric information from high-dimensional data is central to modern representation learning, manifold learning, and generative modeling. This paper addresses the problem of scalable and accurate estimation of Riemannian geometry—specifically the local metric structure—directly from data, circumventing the computational and statistical limitations associated with traditional graph-based and kernel-based estimators. The core proposal is Riemannian metric matching, a neural, denoising-based approach that directly learns the carré du champ (CDC) operator, enabling access to the full toolkit of Riemannian geometry in a data-driven, scalable fashion.
Method: Conditional Metric Matching via Carré du Champ Learning
Traditional approaches to diffusion geometry and manifold analysis construct neighborhood graphs (e.g., k-NN), estimate pairwise distances, and compute kernel-weighted operators, but these scale poorly—and can become unreliable—in high dimensions. The method introduced formulates the estimation of the data’s local Riemannian metric as a regression problem: a neural network is trained to approximate the CDC operator as a conditional expectation under local perturbations, inspired by denoising objectives in diffusion models.
Given data point x, the carré du champ of the coordinate functions forms a local covariance structure encoding the ambient projection onto the manifold’s tangent space. The key insight is that the CDC operator can be efficiently estimated as a conditional moment under Gaussian noise, making the learning problem decomposable and highly parallelizable, and obviating the need for explicit pairwise or graph computations.
The loss function LcondCDC and its matrix-valued version for Riemannian metric matching are constructed to be unbiased surrogates for the classical CDC, with theoretical guarantees that, in the limit, recovery matches manifold geometry as the neighborhood scale shrinks.
Theoretical Guarantees and Parameterization
The authors prove that, under mild locality and smoothness conditions, the learned CDC via metric matching converges to the true Riemannian metric as the Gaussian perturbation bandwidth tends to zero, even when the intrinsic dimension varies or the data lacks a global manifold structure. Moreover, for computational efficiency and robustness, the CDC is parameterized via a low-rank factorization, with rank bounds informed by geometric topology (minimal r≥2d−1 for d-dimensional manifolds).
Empirical Results: Scalability, Accuracy, and Applications
Comparative experiments on synthetic high-dimensional spheres demonstrate the method’s scalability: the neural metric-matching surrogate achieves up to 400× faster inference than k-NN-based CDC estimators for large datasets, with significant memory savings. Additionally, the low-rank decomposition enables efficient eigendecomposition, critical for tangent space estimation.
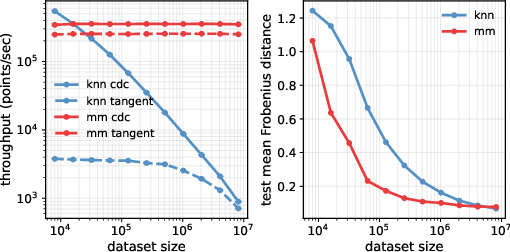
Figure 1: Comparison of throughput and accuracy between neural metric matching and k-NN CDC estimators on varying dataset sizes.
Eigenstructure Analysis
The metric-matching network accurately reconstructs the local geometry, as evidenced by eigenanalysis of the learned CDC matrices. On real datasets such as MNIST and FFHQ, the principal eigenvectors correspond to semantically meaningful directions—such as translations or deformations—aligning with the intrinsic data structure.

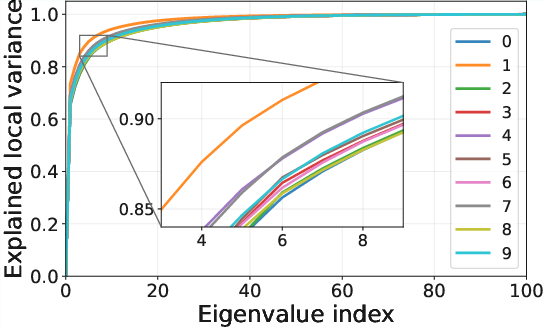
Figure 2: Visualization of the learned CDC eigenvectors at different positions, revealing interpretable tangent directions.

Figure 3: CDC eigenvectors learned on FFHQ showing the multi-scale, interpretable tangent structure in high-dimensional data.
Stability of Features under Tangent Perturbations
Quality of the learned Riemannian metric is quantified by measuring feature stability under CDC-induced random perturbations in inception space. Metric matching yields significantly lower variation compared to isotropic (Euclidean) or rank-1 (Stein) metrics, especially in high dimensions, matching or outperforming the Jacobian-based (“score”) metrics but with vastly reduced computational cost.
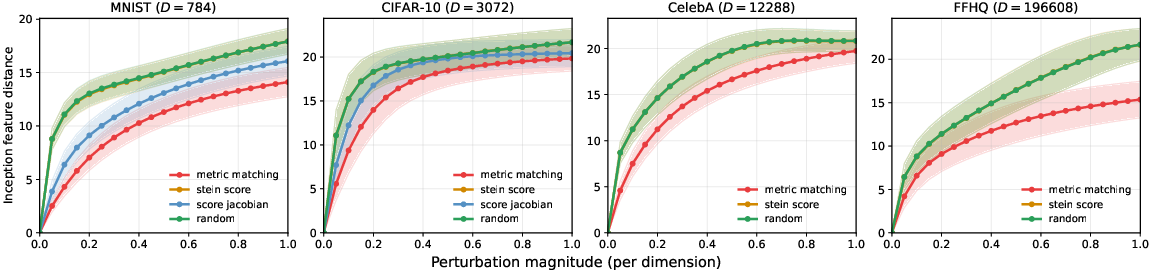
Figure 4: Inception feature stability under tangent perturbations—lower is better, showing metric matching’s advantage across datasets.
Interpolation and Manifold Optimization
The learned CDC enables construction of interpolating paths constrained to the data manifold via Riemannian gradient flows. Compared to linear interpolants, paths generated using metric matching smoothly traverse the high-density regions of the data distribution, remaining perceptually valid and within-class.


Figure 5: Visual comparison of on-manifold interpolation (metric matching) versus linear interpolation in the MNIST dataset.
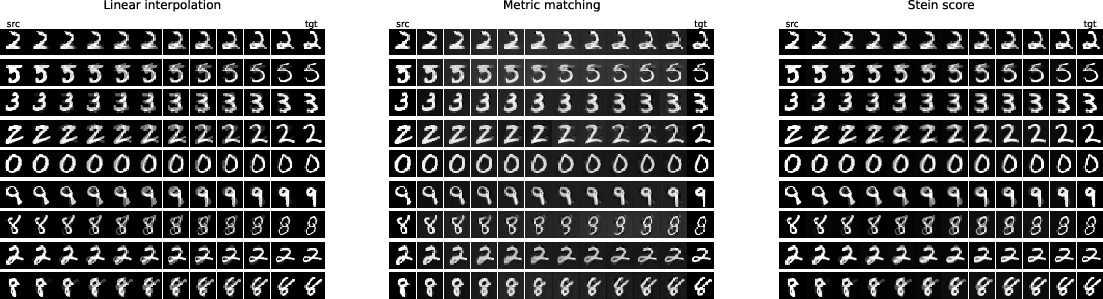
Figure 6: MNIST interpolation paths under different metrics; metric matching yields natural morphing within the data class, contrasting with ghosting artifacts in LERP.
Latent Space Geometry
When applied in the latent space of generative models (e.g., VAEs), metric matching constructs a Riemannian structure that reveals curvature and nonlinearity missed by naive Euclidean geometry. Comparison with pullback metrics further corroborates the interpretability and flexibility of the approach.






Figure 7: Visualization of metric matching versus linear and pullback metrics in VAE latent spaces, illustrating improved path regularity.
Implications and Future Directions
Practically, the method extends the reach of manifold and diffusion geometry tools to massive, high-dimensional datasets—such as natural image collections—where graph-based approaches are infeasible. Theoretical implications include enabling geometric learning and optimization (e.g., geodesics, intrinsic gradients) directly from data, advancing data-driven Riemannian statistics.
The decoupling from pairwise computations opens avenues for integrating metric learning seamlessly into deep learning pipelines, both for analysis (dimension estimation, tangent recovery) and synthesis (diffusion/generative models). Future work will likely explore generalization phenomena of neural CDC surrogates, synergy with geometric structure in architectures, and the extension to distributions lacking manifold structure.
Conclusion
Riemannian metric matching provides a scalable, theoretically-grounded framework for geometric modeling of high-dimensional distributions using neural networks. It surpasses existing graph-based and Jacobian-based approaches in computational efficiency, matches or improves geometric fidelity, and situates Riemannian geometry as a tractable, expressive tool for large-scale machine learning, with broad implications for representation learning, generative modeling, and geometric data analysis.