Beyond LoRA: Is Sparsity-Induced Adaptation Better?
Published 11 Jun 2026 in cs.LG, cs.AI, and cs.IT | (2606.13767v1)
Abstract: Low-rank adaptation (LoRA) and its variants provide a memory- and compute-efficient alternative to full fine-tuning of pre-trained models. However, questions remain about the comparative generalizability of these approaches and how the structural restrictions on low-rank updates preserve effective adaptation performance. We present a historical framing, covering the past (full fine-tuning and original LoRA), the present (different variants of LoRA), and propose simpler, cheaper, parameter-efficient extensions by inducing sparsity within existing LoRA variants: Cheap LoRA (cLA), training a single low-rank factor with the other fixed (deterministically or, in its randomized variant, stochastically), and the chained circulant variant, ${c}3$LA. We frame cLA as a structured instance of asymmetric LoRA, serving as a controlled column-subspace restriction of full fine-tuning. We derive information-theoretic generalization error bounds for these variants, marking one of the first endeavors in this area. Empirically, we evaluate 11 fine-tuning methods across 10 pre-trained models and 14 datasets, analyzing the fine-tuned models' performance and generalization using tools such as loss landscapes and spectral analysis. Despite the sensitivity of fine-tuned models to the pre-trained model, datasets, and other factors, our study suggests that restricting LoRA-based PEFT methods' adaptation to a sparse, structured column space remains competitive across tasks with their parameter-matched baselines while reducing up to 10% training time and peak GPU memory up to 15%, even with a naïve, non-optimized, sparse implementation. Our theoretical and empirical generalization measures provide a more consistent and principled approach to their cost-effective adaptation than commonly used analytical tools. Overview and code are available at: https://elicaden.github.io/Beyond_LoRA/.
The paper introduces structured sparse variants of LoRA that reduce computational costs while maintaining adaptation performance across diverse tasks.
It derives tight information-theoretic generalization bounds linking adapter rank, chain length, and fine-tuning dataset size to model performance.
Empirical evaluations demonstrate that sparse LoRA variants closely match standard LoRA in accuracy while offering significant memory and speed improvements.
Sparsity-Induced Low-Rank Adaptation in Deep Models: Analysis and Empirical Evaluation
Introduction
The proliferation of large pre-trained models across domains has amplified the need for parameter-efficient fine-tuning (PEFT) strategies. Among the current PEFT approaches, Low-Rank Adaptation (LoRA) has emerged as a de facto standard, striking a balance between adaptation efficacy and resource efficiency. The paper "Beyond LoRA: Is Sparsity-Induced Adaptation Better?" (2606.13767) investigates the boundaries of PEFT by introducing and analyzing new variants that explicitly induce sparsity in the adaptation process. The study aims to determine whether such sparsification, in the context of LoRA and its derivatives, can yield competitive adaptation performance, improved generalizability, and reduced computational cost relative to established PEFT techniques and full fine-tuning (FFT).
Past (FFT, Classic LoRA): Standard full fine-tuning updates all weights, resulting in substantial computational and storage demands. LoRA reduces this overhead by representing update matrices as low-rank products, specifically ΔW=BA, which significantly reduces the number of trainable parameters.
Present (LoRA Variants): Numerous extensions aim to improve LoRA's flexibility or robustness, such as CoLA (chain of LoRA), Asymmetric LoRA (freezing one adapter factor), LoRA+, and RAC-LoRA (randomized asymmetric chain).
Future (Sparsity-Induced Adaptation): The core contribution lies here: the introduction and formalization of "sparse LoRA" variants, which further restrict the adaptation subspace within the layer weights:
Cheap LoRA (cLA): Only one of the low-rank factors (typically B) is trained, with A fixed as a structured matrix (block identity).
Random-cLA: Permutes columns of the fixed A.
Circulant Chain Cheap LoRA (c3LA): Systematically shifts the adaptive subspace to guarantee coverage of all columns over multiple "chains".
Random-c3LA: Randomizes the shifting, enabling stochastic coverage.
These variants are interpreted both as a special case of Asymmetric LoRA and as a link to the recently proposed Partial Connection Adaptation (PaCA), which applies explicit column-wise sparsification directly in the backbone without LoRA-style reparameterization. The paper provides explicit pseudocode and theoretical justification for these methods.
Theoretical Framework and Generalization Analysis
A key theoretical contribution is the derivation of information-theoretic generalization bounds for all evaluated PEFT methods. The authors extend the mutual information framework of [Xu & Raginsky, 2017] to the layerwise, structured adaptation setting, slicing the generalization error into two terms:
The generalization gap of the full fine-tuned model is upper-bounded by the better of: (i) a bound centered on the pre-trained model plus the cost of the update step, or (ii) a bound centered on the update itself plus a correction from the pre-trained weights.
These bounds reveal an explicit dependence on adapter rank, chain length, bitwidth, and the size of the fine-tuning dataset:
(W0+ΔW)≤Φ+O(∣N∣rkσ2log(model size))
where r is rank, k is chain length, and ∣N∣ is the fine-tuning sample size.
The paper provides, for the first time, tight information-theoretic generalization error bounds for sparsity-induced LoRA and PaCA, and systematically relates the bounds among the family of PEFT variants.
Notably, the bounds for the sparse LoRA variants (e.g., cLA, B0LA) are shown to be essentially equivalent to their non-sparse counterparts with the same degrees of freedom, rationalizing their empirical competitiveness.
Experimental Evaluation
A multi-task benchmark spans 11 fine-tuning strategies, 10 different large foundation models (covering LLMs, vision transformers, and code generators), and 14 datasets from NLP (e.g., GLUE, PAWS), vision (CIFAR-10, OfficeHome), code generation (DJANGO), and logic reasoning.
Key empirical dimensions include:
Test accuracy and task-specific metrics: Across almost all tasks/datasets, the sparse LoRA variants closely track the performance of standard LoRA and chain-based derivatives, with accuracy drops usually B1 at typical adapter ranks (see Table~\ref{tab:full-accuracy-table}). Occasional larger drops are observed at very low ranks or for highly resource-constrained setups, but these are mitigated by increasing B2.
Generalization error (B3): Empirical estimates (test loss minus train loss) echo theoretical trends: sparsity-induced LoRA methods produce generalization gaps that are within the range of their parent LoRA methods and often comparable to or better than full fine-tuning for the same adaptation budget (see Table~\ref{tab:gen-error-mini}).
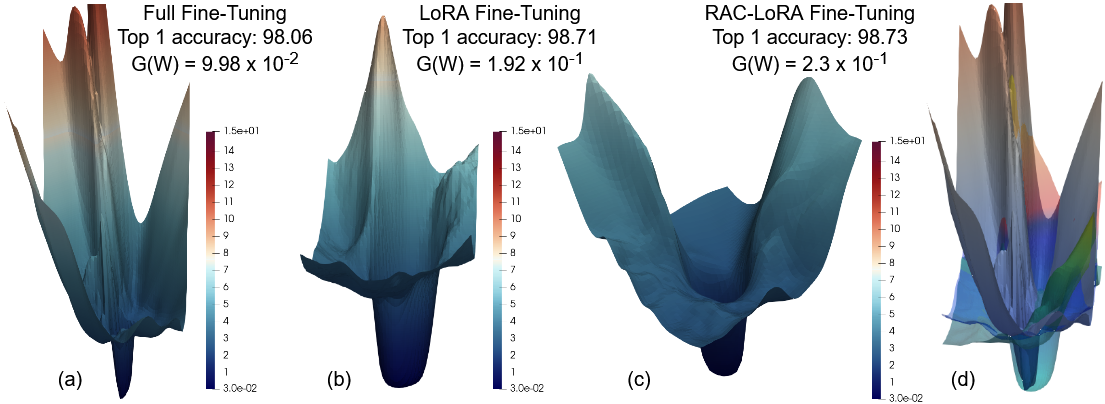
Loss landscape and spectral analysis: Visualization of loss surfaces (cf. Figure 1 below) and intruder dimension analysis illustrate that the proposed methods tend to produce similarly flat minima and spectral properties as standard LoRA. A negative result is identified: contrary to previous lore, sharper minima do not always correlate with worse generalization in the fine-tuning setting (FFT may have sharper minima but can generalize as well or better than LoRA variants—a direct refutation of certain classical heuristics).
Figure 1: 3D loss landscapes of ViT-Base fine-tuned on CIFAR-10 via FFT and various LoRA-based PEFT methods, including cLA. FFT has the spikiest minima, sparse LoRA variants are flatter; generalization error does not correlate simply with sharpness.
Resource efficiency: Sparse LoRA variants, even with naïve implementations, reduce peak GPU memory usage by up to 15% and shorten training time by 5–10% compared to standard LoRA at fixed rank, attributable to their column-sparse structure.
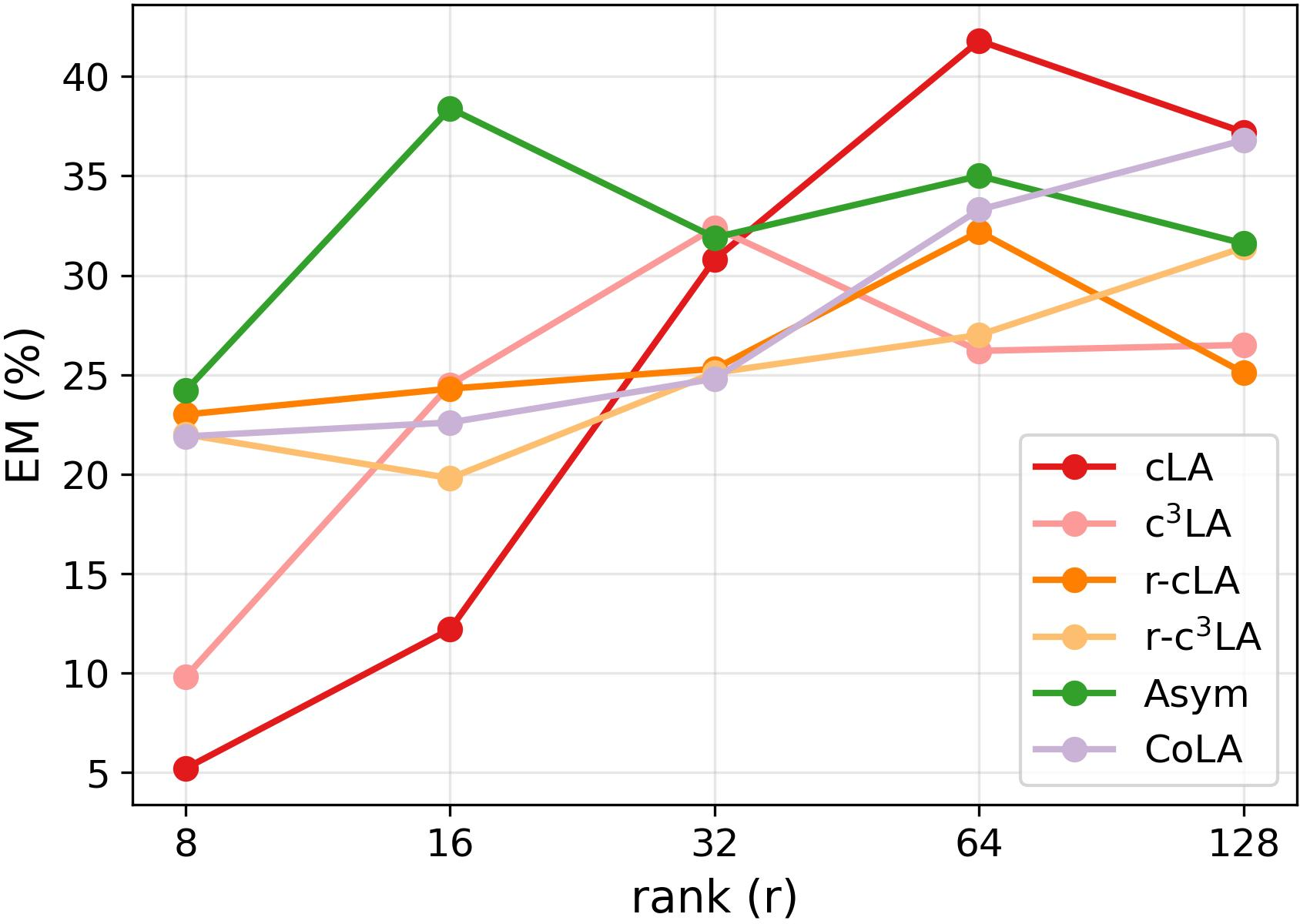
Ablation: Performance differences between sparse LoRA and classic LoRA/CoLA diminish as the rank increases. For code tasks, high sparsity may be more limiting at low rank, but parity is restored at moderate ranks (see Figure 2).
Figure 2: EM accuracy of DeepseekCoder fine-tuned with cLA, B4LA, CoLA, etc. on DJANGO, as a function of rank. The gap closes as B5 increases.
Comparisons to PaCA: Empirically, PaCA and cLA achieve nearly identical accuracy and resource consumption when matched for degrees of freedom. Theoretical results confirm both share their generalization bounds.
Efficiency implementation details: Further optimization (e.g., exploiting gather index operations, see Figure 3) can yield additional speedups and memory savings.
Figure 3: GEMM vs. gather operation for sparse low-rank forward passes in cLA/r-cLA.
Implications, Limitations, and Outlook
The findings deliver several practical and theoretical implications:
Explicit columnwise sparsity in adapter-based fine-tuning (cLA, B6LA) efficiently recovers the adaptation capacity of their denser parent LoRA methods in most settings, with minimal accuracy or generalization penalty.
Theoretical bounds justify that, as long as the same number of degrees of freedom are adapted (e.g., B7 entries), structured sparsity alone does not fundamentally limit information-theoretic generalization.
The connection and "bridging" of LoRA and PaCA reveals that ideas from one regime (e.g., chain construction, theoretical bounds) can transfer directly to the other.
Diagnostic tools such as loss surface visualization and intruder dimension counting are not reliable proxies for "true" generalization in the PEFT context; empirical test losses and the derived theoretical bounds align better with observed adaptation quality.
Limitations: In some regimes (e.g., extreme rank constraint, code generation), sparse variants can experience a sharp drop in performance unless the adaptation subspace is sufficiently broad; task/model interactions remain complex.
Outlook: The results suggest structured, sparsity-oriented PEFT is highly viable for deployment on resource-constrained hardware. Further improvement may come from developing hardware-aware sparse kernels, dynamic reallocation of updated columns/rows, and integration of rank/column-search meta-learning strategies. Given the rapidly growing size of foundation models and stagnating hardware resources, structured sparsity-induced adaptation is poised for widespread adoption.
Conclusion
The paper delivers a rigorous empirical and theoretical examination of sparsity-induced low-rank adaptation, establishing that highly structured, column-sparse variants of LoRA and related PEFT techniques perform on par with their less sparse counterparts. Their generalization error is competitive, and resource savings are tangible. The work rationalizes the use of such methods for practical deployment scenarios and motivates continued refinement of sparse and structured parameter-efficient adaptation in large-scale deep networks.