Modality Forcing for Scalable Spatial Generation
Abstract: Text-to-image (T2I) models contain rich spatial priors. Synthesizing photorealistic, cluttered scenes requires an understanding of geometry, including perspective and relative scale. Prior works adapt T2I models to leverage this prior for depth prediction, but they require dense depth data and involve complex recipes. We propose Modality Forcing, a simple, scalable post-training recipe for joint image-depth generation using a single DiT trained on sparse depth data. Modality Forcing enables conditional and joint generation of image and depth in any permutation by assigning separate noise levels per modality. Per-modality decoders let us train on sparse, real-world depth and achieve strong, generalizable depth prediction. We further show that Modality Forcing inherits the scalability of T2I pre-training: by training a set of T2I models from scratch (370M to 3.3B parameters), we find that larger models trained on more image data produce more accurate depth. Our strongest model is competitive with state-of-the-art monocular depth estimators and reduces AbsRel by 57% relative to existing joint image-depth generative models. These results provide strong evidence that image generation is a scalable pre-training objective for spatial perception. https://modality-forcing.github.io/






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-understand summary of “Modality Forcing for Scalable Spatial Generation”
What is this paper about?
This paper introduces a simple way to teach powerful text-to-image models (the kind that make pictures from text) to also understand and produce 3D information, specifically “depth.” The method, called Modality Forcing, lets one model do three things with the same set of weights:
- Make an image and its matching depth map from a text prompt
- Predict a depth map from a single image (image-to-depth)
- Create an image that matches a given depth map (depth-to-image)
In short, it turns image generators into 3D-aware generators without needing huge, perfect 3D datasets.
What questions does the paper ask?
In simple terms, the paper tries to find out:
- Do today’s top image generators already “know” a lot about 3D (like perspective and shape), and can we reuse that knowledge for depth?
- Can we train a single model to flexibly switch between making images, making depth, or making both together?
- If we start with bigger and better image generators, do we get better depth results too?
How does it work? (With simple analogies)
To explain the approach, here are the key ideas in everyday language:
- What is a depth map? Think of a depth map as a picture where each pixel tells you how far away something is. It’s like a grayscale map of distance—bright might mean “close” and dark “far” (or vice versa).
- What is a text-to-image model? It’s a model that turns a sentence like “a cat on a skateboard at sunset” into a picture. Modern ones, like diffusion transformers (DiT), create images by starting from noise (random static) and gradually “un-blurring” it into a final image.
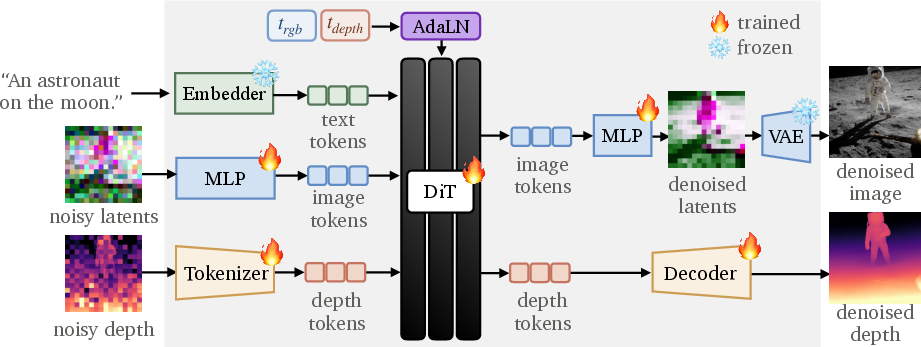
- Modality Forcing: Two dials, one for image and one for depth
- Clear image + noisy depth → it learns to predict depth from the image (image-to-depth).
- Clear depth + noisy image → it generates an image that matches the depth (depth-to-image).
- Both noisy → it creates both image and depth from a text prompt (joint generation).
- This “two-knob” trick is the core of Modality Forcing.
- Learning from incomplete depth (“sparse” depth) Real-world videos often have depth for only some pixels (not all). Instead of giving up, the model fills missing depth pixels with random noise to mark them as “unknown.” This lets it learn from imperfect data, which is common and much easier to collect.
- Keeping the image skills while adding depth (self-distillation) When teaching the model new tricks (depth), we don’t want it to forget its old skills (great image quality). So during training, the new model gently compares itself to its original self on the image part—like a student checking with last year’s notes—so it doesn’t forget how to make good pictures.
- One backbone, small extras The model shares most of its “brain” for both image and depth, but adds small parts for handling depth-specific details. This keeps it simple and efficient.
What did they find, and why does it matter?
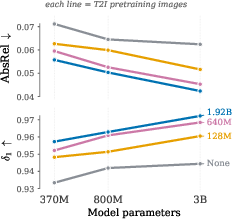
The authors ran a careful “scaling study”: they trained several base text-to-image models of different sizes (from 370 million to 3.3 billion parameters) and with different amounts of image data (up to 1.92 billion images). Then they applied the same Modality Forcing recipe to each and checked depth accuracy.
Key results:
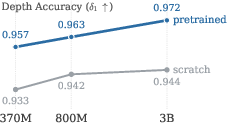
- Bigger and better-trained image generators produced better depth. This shows that image generators really do learn strong 3D knowledge as they scale.
- Their best model’s depth predictions are competitive with the top specialized depth systems, even though those systems are dedicated to depth. Against other models that generate both image and depth together, Modality Forcing reduced a common depth error (AbsRel) by about 57%, a large improvement.
- The same model works in all directions: text-to-image+depth, image-to-depth, depth-to-image. No separate models needed.
Why this matters:
- It proves a simple idea: if you pretrain on huge amounts of images, you can unlock 3D understanding without needing massive, perfect 3D datasets.
- It makes 3D-aware generation more practical for creative tools, robotics, AR/VR, and game design, all from a single unified model.
What could this be used for?
Here are a few examples of how this helps:
- Artists and designers: Generate scenes from text that also come with matching 3D depth, making it easier to relight, edit, or convert into 3D point clouds or meshes.
- Robotics and autonomous systems: Predict scene depth from a single camera image to understand where things are.
- AR/VR and games: Build consistent worlds where the look (image) and structure (depth) match, enabling better effects and interactions.
- Film and architecture: Create consistent layouts with different styles by swapping appearance while keeping the same depth structure.
Bottom line and future directions
- Bottom line: Modality Forcing is a simple, scalable way to turn powerful image generators into flexible image+depth generators. The bigger and better the original image model, the better the depth results. This is strong evidence that image generation is a great “pretraining step” for 3D understanding.
- Limitations and what’s next:
- The largest tested model is 3.3B parameters; going bigger could unlock more gains.
- The depth training data, while large for 3D, is still tiny compared to image-only data; more and better depth data could help.
- Depth-to-image can sometimes follow depth less strictly than some baselines; improving control could make it even stronger.
- Future work might also aim for exact real-world distances (metric depth), not just relative depth.
Overall, this paper shows a neat, practical trick: give each modality (image and depth) its own “noise knob” and train them together. That simple idea unlocks a powerful, all-in-one model for creating and understanding 3D content at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scope beyond depth: The method is only validated on RGB–depth; it does not test extension to other spatial modalities (e.g., surface normals, semantics, optical flow, point clouds, meshes) despite claiming a general recipe. Evaluate whether pixel-space tokenization and per-modality timesteps scale to these modalities.
- Metric depth and camera geometry: All reported depth evaluations are affine-invariant; the method does not output metric depth, camera intrinsics, or scale-consistent predictions. Investigate adding metric supervision and camera-aware conditioning to recover absolute scale and intrinsics.
- Joint consistency metrics: Joint RGB–depth generation is only shown qualitatively; there is no quantitative assessment of geometric consistency between generated RGB and depth (e.g., 3D reconstruction quality, multi-view reprojection error, planarity/edge consistency).
- Depth-to-image adherence: In D2I, the model achieves best FID but weaker depth-following than JointDiT. Systematically quantify and improve the trade-off between image quality and faithfulness to depth constraints (e.g., via controllable guidance, trajectory schedules, or loss terms).
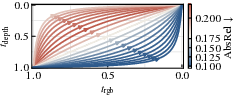
- Inference trajectory control: Partial conditioning via denoising trajectories is demonstrated qualitatively and with a limited analysis; no comprehensive, quantitative study relates trajectory parameter α to adherence/quality across datasets and tasks, nor best-practice defaults.
- Self-distillation design: The RGB-only self-distillation loss is not ablated (e.g., λ_hi/λ_lo sensitivity, alternative schedules, applying distillation to depth, or different teachers). Assess how distillation impacts depth quality, T2I quality retention, and over-regularization.
- Cross-stream mixing ablation: The role and capacity of the cross-stream timestep mixing modules (and their initialization) are not evaluated. Measure their contribution and identify minimal necessary coupling.
- Depth tokenizer/decoder capacity: The number of depth-specific attention layers, depth pathway initialization strategy, and detokenizer architecture are not ablated. Determine how much specialized capacity is needed and where to place it.
- Sparse supervision assumptions: Missing depth is filled with isotropic Gaussian noise; the impact of MVS-specific structured missingness (e.g., reflective/textureless regions) on learning is not studied. Compare alternative missing-data encodings and robustness to varying sparsity patterns.
- Data composition effects: The 17M-frame training mix spans diverse datasets, but there is no ablation of per-dataset contributions or domain biases. Quantify sensitivity to indoor/outdoor balance, synthetic vs. real ratios, and per-dataset removal.
- Evaluation leakage/confounds: ScanNet appears in both training and evaluation; the paper notes a confound but does not quantify it. Re-evaluate on strictly held-out domains and report cross-dataset generalization.
- Resolution and scale limits: Scaling experiments are done at 256×256 (scaling study) and 512×variable AR (FLUX-based model). Effects of higher resolutions on depth detail, stability, and compute are not analyzed.
- Formal scaling laws: While results trend positively up to ~3.3B parameters and 1.92B images, no formal scaling law (with exponents, uncertainty) is derived. Extend model sizes/data further, and fit explicit scaling relationships.
- Role of T2I factors: The relative contributions of T2I architecture, dataset quality, data curation, and text conditioning to downstream depth quality remain unseparated. Conduct controlled factor ablations (same data, different trunk; same trunk, different data; with/without text).
- Text conditioning for depth: The influence of text prompts on I2D prediction and joint RGB–depth sampling is unclear. Study how prompt content affects depth priors and failure modes.
- Sampling and solver choices: The paper mixes x-pred/v-pred discussions but lacks ablations on prediction parameterization, ODE solvers, step counts, timestep distributions, and their effects on depth and RGB–depth coherence.
- Robustness and OOD generalization: No analysis of robustness to noise, motion blur, extreme perspectives, reflective/transparent objects, adverse weather, or domain shifts (e.g., medical, satellite). Evaluate OOD and robustness benchmarks.
- Uncertainty quantification: The method does not produce calibrated depth uncertainties or confidence maps; ensembling is mentioned in evaluation but not as a model feature. Add and validate uncertainty estimates for depth and joint outputs.
- Multi-view consistency: Despite 3D claims, the method is only single-view; it does not enforce or evaluate consistency across multiple synthesized views or camera trajectories. Explore multi-view conditioning/sampling and consistency metrics.
- Computational efficiency: Training/inference time, memory footprint, and scalability costs are not reported. Provide throughput metrics and analyze trade-offs from added depth pathway and per-modality noise conditioning.
- Ethical/data transparency: The paper does not detail web data sources, licensing, or filtering, nor analyze inherited biases and their impact on depth predictions across demographics/scenes. Add dataset documentation and bias evaluations.
- Depth evaluation breadth: Metrics focus on AbsRel and δ1; edge fidelity, boundary sharpness, planarity, and structural metrics (e.g., EPE, SILog, plane/line errors) are not reported. Broaden metrics for a more complete assessment.
- Ground-truth proxies in D2I: D2I depth adherence is measured via Depth Anything V2 on generated and ground-truth images, which is a proxy. Validate against actual ground-truth depths or controlled synthetic scenes to avoid teacher-induced bias.
- Camera modeling assumptions: Unprojection for visualization assumes a pinhole model without predicted intrinsics; geometric validity under unknown camera parameters is not addressed. Incorporate or infer intrinsics/extrinsics where needed.
- Generalization to larger T2I backbones: The approach is not tested on >3.3B parameter T2I models or newer architectures; it’s unclear whether gains continue or saturate. Extend experiments to larger/open recent checkpoints.
- Modality interference/forgetting: Although self-distillation is used, a rigorous analysis of catastrophic forgetting (image quality, text fidelity) and modality interference (depth harming T2I) is missing. Quantify T2I metrics pre/post training and test mitigation strategies.
- Downstream utility: Claims about benefits for embodied agents/architects are not validated in downstream tasks (e.g., navigation, grasping, 3D reconstruction). Conduct task-level evaluations using generated RGB–depth.
- Safety in controllable generation: Partial conditioning enables strong control, but there is no discussion of failure cases or safeguards (e.g., depth misguidance producing unsafe geometry for robotics). Define safe operating regions and detectors for inconsistent outputs.
Practical Applications
Overview
This paper introduces “Modality Forcing” (#1), a simple post‑training recipe that turns a text‑to‑image (T2I) diffusion transformer into a unified image–depth generator. A single DiT is trained with per‑modality noise schedules and a pixel‑space depth tokenizer so it can (1) estimate depth from an image (I2D), (2) generate images that follow a given depth map (D2I), and (3) jointly sample image and depth from text. The method learns from sparse real‑world depth, preserves the pretrained T2I prior via self‑distillation, and scales: larger/better T2I backbones yield better depth. Results are competitive with top monocular depth estimators and surpass prior joint RGB‑D generators.
Below are practical applications derived from the paper’s findings, methods, and innovations.
Immediate Applications
These are deployable now using the released code/demo or straightforward integrations with current T2I backbones and depth datasets.
- Industry (Media/Creative Tech): Text-to-RGBD asset generation
- What: Generate images and aligned depth from prompts for 2.5D effects, relighting, depth-of-field, parallax video, and compositing.
- Tools/workflows: Plugins for Adobe After Effects/Photoshop, Blender, Nuke; a “Text → RGB+Depth” panel that exports depth maps and point clouds; Hugging Face demo or API endpoint wrapping #1.
- Assumptions/dependencies: Requires a capable T2I backbone (e.g., FLUX-like); quality improves with model/data scale; depth is affine-invariant (non-metric) unless post-aligned.
- Industry (Gaming/AR/VR): Rapid 3D scene prototyping from text
- What: Use joint RGB‑D to bootstrap proxy geometry (point clouds/height maps) for level blocking, occlusion, and physics approximation.
- Tools/workflows: Unity/Unreal importer converting generated depth to meshes; material variants via D2I.
- Assumptions/dependencies: Geometry is approximate; scale may be non-metric; additional meshing and cleanup needed for production.
- Industry (Product/E-commerce): Depth-conditioned appearance variants
- What: Keep a product’s geometry fixed (depth) and synthesize different textures, materials, or styles with text guidance.
- Tools/workflows: D2I batch generation; A/B pipelines to create catalog variants; UI sliders for conditioning strength using partial-depth denoising trajectories.
- Assumptions/dependencies: D2I depth-following can be loose in some scenes; tune denoising trajectory to strengthen adherence.
- Robotics (Perception): Monocular depth estimation as a drop-in module
- What: Use I2D for scene depth in navigation, manipulation, or obstacle detection when stereo/LiDAR is unavailable.
- Tools/workflows: ROS node for image-to-depth; fusion with SLAM/VIO to resolve scale; online affine-to-metric alignment.
- Assumptions/dependencies: Affine-invariant predictions require scale recovery; inference cost of a DiT may require smaller checkpoints or distillation.
- Robotics/Autonomy (Data Generation): Text-conditioned RGB‑D synthesis for training
- What: Generate diverse RGB‑D samples to augment perception datasets and cover rare corner cases.
- Tools/workflows: Dataset factory that outputs prompts, images, depth, and 3D point clouds; domain randomization via text prompts.
- Assumptions/dependencies: Synthetic-to-real gap persists; ensure prompts reflect target domain; legal/ethical use of T2I pretraining data.
- Academia (Vision Research): Probing spatial priors in T2I at scale
- What: Use #1 as a controlled testbed to study how T2I scaling affects spatial reasoning and geometry.
- Tools/workflows: Reproduce scaling experiments (370M–3.3B params); ablation of per-modality timesteps; evaluate on NYUv2, DIODE, ETH3D, ScanNet.
- Assumptions/dependencies: Access to compute for pretraining/post-training; consistent evaluation protocols.
- Academia/Industry (Pipeline Simplification): Unified model for I2D, D2I, joint RGB‑D
- What: Replace multiple task-specific models with a single checkpoint that toggles tasks via noise schedules.
- Tools/workflows: Inference wrapper exposing three modes; scheduling presets for stricter D2I conditioning or higher image fidelity.
- Assumptions/dependencies: Performance parity with specialists varies by task; trajectory selection matters.
- Photography/Smartphones (Daily Life): Better depth maps for portrait and AR effects
- What: Improve bokeh, relighting, and AR occlusion from single images.
- Tools/workflows: On-device/cloud processing using I2D; enhanced “3D photo” generators for social media.
- Assumptions/dependencies: Mobile deployment may need pruning/quantization or server-side inference; domain adaptation for phone cameras.
- Architecture/Design (AEC): Fast concept studies with consistent geometry
- What: Prompt rough scenes and export depth/point clouds for early layout visualization and lighting studies.
- Tools/workflows: CAD/BIM add-ons importing depth as height fields; D2I to explore material palettes on fixed geometry.
- Assumptions/dependencies: Non-metric scale; not a substitute for detailed CAD; suitable for ideation.
- Education (STEM/Art): Teaching perspective and 3D geometry
- What: Generate scenes and depth to demonstrate perspective, vanishing points, and 3D reconstruction.
- Tools/workflows: Classroom apps with “show depth” overlays; interactive sliders for partial depth conditioning to observe geometry–appearance coupling.
- Assumptions/dependencies: Internet/computing access; curated prompts for age-appropriate content.
- QA/Compliance (Media Integrity): 3D consistency checks for generated images
- What: Use I2D to verify geometric plausibility (e.g., straight lines, planar surfaces) in T2I outputs.
- Tools/workflows: Post-generation audit that flags geometric artifacts by comparing predicted depth to structural priors.
- Assumptions/dependencies: False positives/negatives on stylized imagery; thresholds require tuning per use case.
- Developer Tools (APIs): Unified RGB‑D generation services
- What: Offer endpoints for Text→RGBD, Image→Depth, and Depth→Image with trajectory controls.
- Tools/workflows: SaaS APIs with rate limiting and safety filters; SDKs for Python/JS.
- Assumptions/dependencies: Compute costs; content moderation policies for T2I prompts.
Long-Term Applications
These require further research, scaling, or domain adaptation beyond the paper’s current scope.
- General 3D Generators (Software/Robotics/Gaming): Beyond depth to normals/point clouds/meshes
- What: Extend per-modality noise schedules to cover richer 3D modalities for a general-purpose spatial generator.
- Tools/workflows: Multi-head decoders for normals/point maps/meshes; export to USD/GLTF.
- Assumptions/dependencies: Sparse supervision for additional modalities; new tokenizers/detokenizers; more compute and data.
- Full Text-to-3D Pipelines (Media/Gaming/AR/VR): From prompts to watertight assets
- What: Use joint RGB‑D as initialization for NeRF/SDF/TSDF recon to produce meshes suitable for production.
- Tools/workflows: Automated pipeline: Text → RGB‑D → multi-view expansion → reconstruction → retopo/UVs → material assignment.
- Assumptions/dependencies: Multi-view consistency and scale remain challenges; quality hinges on T2I coherence.
- Metric Depth and Camera Intrinsics (Robotics/Autonomy/Mapping)
- What: Achieve metric scale and recover intrinsics/extrinsics to support mapping and navigation.
- Tools/workflows: Integrate MoGe‑style supervision, self-calibration, or fusion with IMU/GNSS; train with metric datasets.
- Assumptions/dependencies: Access to calibrated data; careful loss design; safety certification for deployment.
- Photogrammetry Acceleration (AEC/Cultural Heritage): Fewer views, faster capture
- What: Combine sparse MVS with #1 I2D to densify depth, reducing required viewpoints for reconstructions.
- Tools/workflows: Hybrid capture apps that guide users; reconstruction backends that fuse predicted and MVS depth.
- Assumptions/dependencies: Robustness to textureless/reflective surfaces; uncertainty modeling for fusion.
- Real-time Edge Deployment (Robotics/Mobile/XR)
- What: Distill or quantize the joint model to run on embedded/AR devices for on-device depth and RGB‑D generation.
- Tools/workflows: Model compression (LoRA, low‑rank adapters, token pruning), specialized schedulers, on-device ODE solvers.
- Assumptions/dependencies: Tight latency/energy budgets; potential accuracy loss; vendor-specific toolchains.
- Safety-Critical Use (Automotive/Defense/Healthcare)
- What: Use depth prediction for ADAS perception or surgical scene understanding with stringent reliability.
- Tools/workflows: Extensive domain-specific fine-tuning, uncertainty quantification, redundancy (sensor fusion), formal verification.
- Assumptions/dependencies: Regulatory approval; rigorous validation; domain shifts (weather, body tissue) require specialized data.
- Remote Sensing/Geo (Energy/Policy/Environment): Monocular terrain estimation
- What: Infer DEM-like depth from satellite/aerial imagery to aid planning and disaster response.
- Tools/workflows: Domain-adapted training on satellite datasets; fusion with stereo/altimetry for scale.
- Assumptions/dependencies: Spectral/angle domain gap vs. natural images; need for metric calibration.
- Interactive Creative Tools (Design/Art): Fine-grained geometry–appearance controls
- What: UIs where users sketch or supply partial depth, then steer adherence strength and style through trajectory control.
- Tools/workflows: Brush-based depth editors; “conditioning strength” sliders; live previews.
- Assumptions/dependencies: Robust partial conditioning across diverse scenes; responsive inference.
- Dataset Economies (Policy/Academia/Industry): Training with sparse supervision
- What: Broader participation in 3D model training by leveraging sparse real-world depth from consumer capture.
- Tools/workflows: Crowdsourcing platforms collecting sparse depth; standardized schemas for sparse RGB‑D.
- Assumptions/dependencies: Data quality/consent/licensing; bias mitigation; privacy policies.
- Standards and Evaluation (Policy/Standards Bodies): Spatial fidelity benchmarks for generative models
- What: Establish benchmarks and reporting standards for RGB‑D consistency, depth accuracy, and controllability.
- Tools/workflows: Public leaderboards; standardized trajectories (I2D/D2I/joint) and metrics (AbsRel, δ1, geometric constraints).
- Assumptions/dependencies: Community consensus; dataset curation; anti-gaming measures.
- Digital Twins (Industry/Manufacturing/Energy): Rapid asset ingestion and variation
- What: Generate geometry-consistent visual variants for simulated inspections, training, or scenario testing.
- Tools/workflows: Pipeline connecting #1 to digital twin platforms (e.g., Omniverse) with depth-to-mesh conversion.
- Assumptions/dependencies: Need for metric consistency and topology quality; governance around synthetic data.
- Domain-specific Healthcare (Endoscopy/Dermoscopy): Affine-invariant depth priors for 3D understanding
- What: Use I2D to aid 3D perception in monocular medical videos where geometry aids navigation and documentation.
- Tools/workflows: Fine-tuning on labeled medical datasets; integration with SLAM for metric scale.
- Assumptions/dependencies: Strict regulatory oversight; domain shift vs. natural images; privacy and annotation costs.
Cross-cutting assumptions and dependencies
- Scaling dependency: Depth quality improves with T2I capacity and training data; small/backbone-poor models will underperform.
- Metric vs. affine depth: Out-of-the-box depth is affine-invariant; many applications need metric scale (requires alignment or fusion).
- Compute and latency: DiT-based inference is heavier than lightweight discriminative models; distillation/compression may be necessary for edge.
- Data licensing and ethics: Pretraining data provenance and content moderation policies apply to T2I use; ensure compliance.
- Domain adaptation: For specialized domains (medical, satellite, automotive), retraining or fine-tuning is required.
- Resolution and artifacts: Current results emphasize 256–512 px; high-res and strict geometry may need multi-view or reconstruction post-processing.
- Control fidelity: D2I adherence varies; inference-time trajectory tuning (e.g., denoise depth earlier) can strengthen conditioning but may trade off appearance diversity.
Glossary
- AbsRel: An absolute relative error metric commonly used to evaluate depth prediction accuracy; lower is better. "reduces AbsRel by 57\% relative to existing joint image-depth generative models."
- Affine-invariant alignment: An evaluation alignment that removes global scale and shift differences before comparing depth maps. "We use the robust affine-invariant alignment introduced in MoGe-2~\cite{wang2025moge2}."
- Affine-invariant depth estimation: Assessing depth predictions up to an unknown affine transformation (scale and shift). "Affine-invariant depth estimation."
- channel-wise inpainting: A technique that fills in missing or target channels (e.g., depth) conditioned on others (e.g., RGB) within a joint model. "supporting bidirectional prediction via channel-wise inpainting."
- D2I (Depth-to-Image): Generating an image conditioned on a depth map (and optionally text). "depth-to-image (D2I)"
- Denoising trajectory: The path of noise levels over time (or steps) during sampling, possibly different per modality. "Encoding per-modality timesteps independently allows for arbitrary denoising trajectories."
- Depth detokenizer: A module that maps learned depth tokens back to a pixel-space depth image. "The DiT blocks are followed by a depth detokenizer with layers of self-attention"
- Depth tokenizer: A module that converts pixel-space depth values into tokens suitable for a transformer or diffusion backbone. "Depth tokenizer."
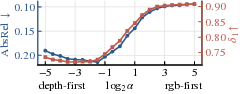
- Delta-1 (δ1): A depth accuracy metric measuring the fraction of pixels within a specified relative threshold. "Depth accuracy (, , bottom) and AbsRel (, top) by T2I model size."
- DiT (Diffusion Transformer): A transformer-based architecture for diffusion or flow-matching generative models. "replaced the U-Net with a Diffusion Transformer (DiT)"
- DINO: A self-supervised vision transformer representation whose latents can be used as an alternative modality or conditioning signal. "Latent Forcing denoises DINO~\cite{oquab2023dinov2} latents ahead of raw pixels."
- FID (Fréchet Inception Distance): A distributional image quality metric comparing generated and real images via Inception features; lower is better. "compute the FID vs GT images"
- Flow matching: A training objective that learns a continuous vector field (velocity) to transport noise to data for generative modeling. "We discuss flow-matching with -prediction and -prediction"
- Flow transformer: A transformer model trained with flow-based objectives (e.g., rectified flow) for image generation. "both flow transformers operating in the latent space of an image VAE"
- grouped-query attention: An attention variant that partitions queries into groups to improve efficiency or performance. "grouped-query attention, and RoPE positional encoding"
- I2D (Image-to-Depth): Predicting a depth map from an input image (and optionally text). "Image-to-depth (I2D)"
- Latent diffusion models: Diffusion models that operate in the latent space of a pretrained autoencoder rather than directly in pixel space. "latent diffusion models"
- Latent Forcing: A strategy that orders denoising across latent types to control generation, e.g., denoising feature latents before pixels. "Latent Forcing denoises DINO latents ahead of raw pixels."
- Learning without Forgetting: A continual learning technique that preserves prior knowledge via a distillation-like loss when learning new tasks. "similar in spirit to `Learning without Forgetting'"
- logit-normal sampling: A timestep/noise sampling schedule where timesteps are drawn from a logit-normal distribution. "We use logit-normal sampling for RGB"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into pretrained weights. "generalizes this with LoRA"
- Modality Forcing: The paper’s post-training recipe that assigns separate noise schedules per modality to enable joint and conditional generation. "Modality Forcing post-trains a pretrained text-to-image DiT to model the joint distribution over RGB and depth."
- multi-view stereo (MVS): A technique that infers depth by triangulating across multiple images with varying viewpoints. "using multi-view stereo (MVS) pipelines."
- ODE solver: A numerical integrator used to follow the learned continuous-time vector field from noise to data during sampling. "Both methods sample the learned vector field from to with an ODE solver."
- per-modality noise levels: Using separate noise schedules for each modality (e.g., RGB and depth) during diffusion/flow training and sampling. "a diffusion algorithm with per-modality noise levels."
- Per-modality timestep conditioning: Conditioning each modality’s tokens with its own timestep embedding to support asymmetric noise levels. "Per-modality timestep conditioning."
- plateau logit-normal sampling: A modified logit-normal timestep schedule with a plateau shape to emphasize certain noise ranges. "and plateau logit-normal sampling for depth"
- rectified-flow objective: A flow-based training objective that stabilizes learning by rectifying the transport field between noise and data. "trained under a rectified-flow objective."
- ROE (robust and optimal alignment solver): An alignment solver used to compare predicted and reference depth under robust affine-invariant criteria. "We use the robust and optimal alignment solver (ROE)"
- RoPE positional encoding: Rotary positional embeddings that encode relative positions via complex rotations in attention. "RoPE positional encoding"
- RMSNorm: Root Mean Square Layer Normalization, a normalization variant used before and after transformer blocks. "pre- and post-RMSNorm"
- self-distillation: A training regularizer where a student model is penalized for deviating from a frozen teacher (often the original model). "we introduce a self-distillation loss"
- spatial contraction: A mapping that contracts unbounded distances into a bounded range to stabilize learning and representation. "followed by spatial contraction~\cite{barron2022mipnerf360} to ensure ."
- Teacher Forcing: A training technique that feeds ground-truth tokens for prior positions or modalities to guide generation. "Teacher Forcing~\cite{6795228} runs along sequence position"
- timestep embedder: A module that converts the scalar diffusion/flow timestep into a vector embedding for conditioning the network. "We give RGB and depth separate timestep embedders"
- timestep shift: A shift applied to the timestep distribution used during sampling to bias denoising behavior. "with a timestep shift of ."
- U-Net: A convolutional encoder-decoder architecture with skip connections widely used in diffusion models. "replaced the U-Net with a Diffusion Transformer (DiT)"
- VAE (Variational Autoencoder): A generative autoencoder that provides a compressed latent space for images. "latent space of a pretrained VAE"
- v-prediction: Parameterization of the model to predict the velocity (transport vector) along the noise-to-data path. "We discuss flow-matching with -prediction and -prediction"
- x-prediction: Parameterization of the model to predict the clean sample, from which velocity is derived. "We discuss flow-matching with -prediction and -prediction"
Collections
Sign up for free to add this paper to one or more collections.