- The paper demonstrates that temporal alignment between proprioceptive states and visual inputs allows robots to robustly distinguish self from others, achieving over 99.5% accuracy.
- The method leverages a joint encoder with contrastive InfoNCE loss to fuse sensory data, eliminating the need for pre-engineered identity labels, kinematic priors, or geometric models.
- The self-modeling component uses a pose-conditioned implicit neural field to support contact-rich planning and motion transfer, validated through target reaching, collision avoidance, and motion retargeting experiments.
Proprioceptive-Visual Correspondence for Self-Other Distinction and Self-Modeling in Humanoid Robots
Introduction
This work presents a framework enabling robots to autonomously distinguish themselves from others in multi-agent settings and build a 3D geometric self-model directly from coupled proprioceptive and visual inputs. Unlike prior approaches that require identity labels, kinematic priors, or geometric body models, this method leverages temporal and spatial correspondences between proprioceptive states and scene observations—an approach motivated by developmental findings in humans where bodily self-awareness precedes explicit body modeling.
The central claims are: (1) that proprioceptive-visual alignment is sufficient to achieve robust self-other distinction in complex, cluttered scenes without engineered supervision; (2) that this distinction supports learning a high-fidelity, kinematics-free 3D self-model; and (3) that the resulting models provide actionable gradients for contact-rich, physically constrained planning and transfer tasks without manual specification of robot structure.
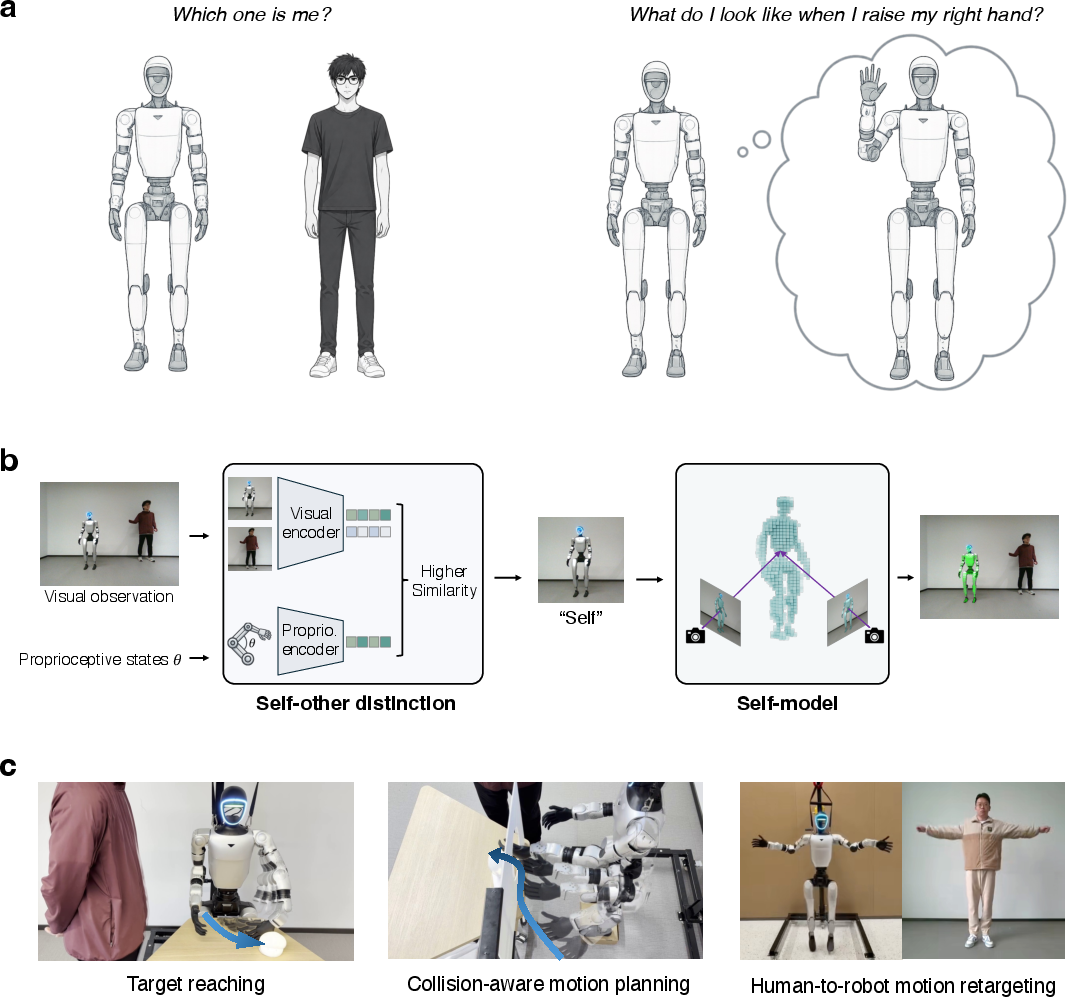
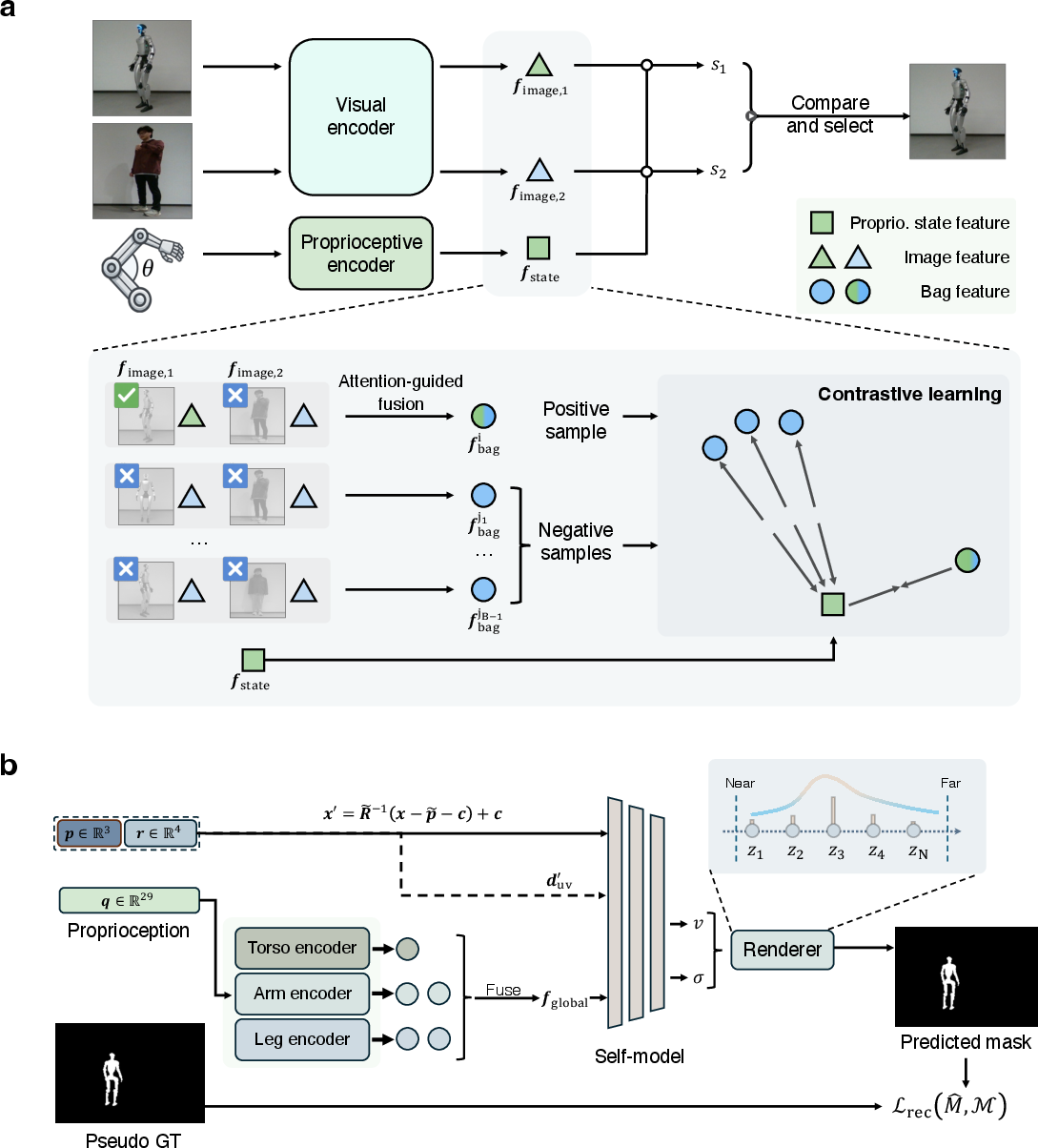
Figure 1: Framework overview illustrating coupled tasks of self-identification and 3D self-model learning, both emergent from proprioceptive-visual correspondence.
Self-Other Distinction From Proprioceptive-Visual Alignment
The self-other distinction problem is formulated as a self-supervised instance discrimination task using only paired proprioceptive states and visual observations. Training avoids identity labels and kinematic models, relying on the asymmetry that the robot's current proprioceptive state temporally coincides with the visual mask for "itself" in each frame, but not with any other mask in temporally negative frames. The approach employs a joint encoder architecture for candidate body masks (from single-frame segmentation) and proprioceptive vectors, projecting both into a shared embedding space. Attention weights select the instance whose visual shape is most compatible with the observed state, enforced via contrastive InfoNCE loss over a batch-wise set of positives and negatives.
Empirical results show,
- Accuracy >99.5% on both real human-robot and simulated robot-robot scenes, where in the latter, all visual and morphological cues are strictly matched, eliminating identity priors.
- Zero-shot vision-LLMs (LLaVA, InstructBLIP, GPT-5.5, Gemini 3.1), even with access to language, failed to perform above chance, confirming that semantic knowledge is insufficient for this task.
Qualitative visualization and t-SNE projections further demonstrate that post-training, synchronous proprioceptive-visual pairs cluster tightly, while asynchrony and distractors are effectively separated.
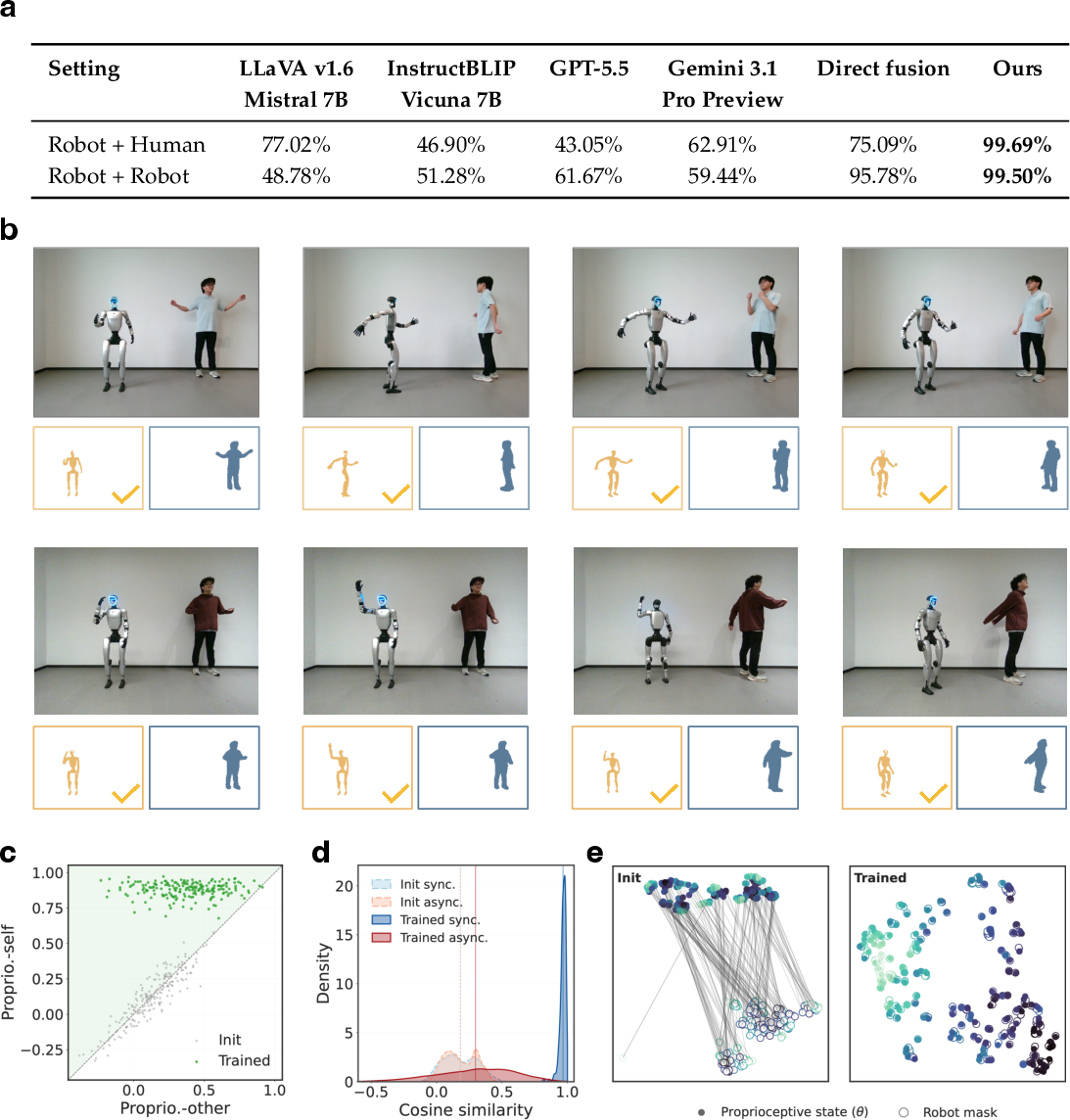
Figure 2: Contrastive self-other discrimination: performance with different baselines, per-frame similarity dynamics, and embedding visualizations.
Kinematics-Free Self-Modeling From Self-Supervised Signals
Conditioned on having accurate self-masks from the previous stage, the framework fits a pose-conditioned volumetric occupancy field—mapping joint configurations and root pose to 3D body geometry—in the style of implicit neural field models (NeRF). Neither URDF nor CAD models are used; only the inferred self-mask per frame supervises the representation. A part-aware proprioceptive encoder disentangles branching topologies (torso, arms, legs), while bounded volumetric rendering with visibility-aware compositing adapts the NeRF framework to binary occupancy rather than RGB.
Key findings:
Generalization to Physical Interaction and Motion Transfer
The differentiable self-model exposes 3D body occupancy as a function of joint configuration, supporting gradient-based downstream reasoning. Three tasks are operationalized:
- Target Reaching: Optimizing hand pose to approach a spatial target achieves an 88% physical success rate (mean distance 51.3 mm; threshold 100 mm) across 50 trials, using only the self-model's hand occupancy centroid for inverse kinematics.
- Collision-Aware Motion Planning: Planning left-arm trajectories through a board aperture using a learned joint-space RRT with dense collision checks on the occupancy field. Success rate reaches 71.4% (10/14 constrained settings), with robust avoidance of environmental obstacles.
- Human-to-Robot Motion Retargeting: A monocular video is processed into human 3D keypoints, mapped by segment direction and rescaled to robot morphology. Optimization through the self-model's differentiable forward kinematics yields full-body retargeting with a mean per-keypoint error of 36.1 mm (2.7% of robot body height) over 50 keyframes—obtained without paired demonstration or hand-designed joint correspondences.

Figure 4: (a) Real robot target reaching and (b) collision-aware planning through aperture obstacles.

Figure 5: Qualitative whole-body retargeting: motion demonstration (human) mapped via self-model optimization to humanoid robot.
Algorithmic and Architectural Summary
A two-stage approach is realized:
Comparative Analysis and Ablations
- Ablations confirm that representation dimension, scale normalization, and attention sharpness critically impact discrimination accuracy.
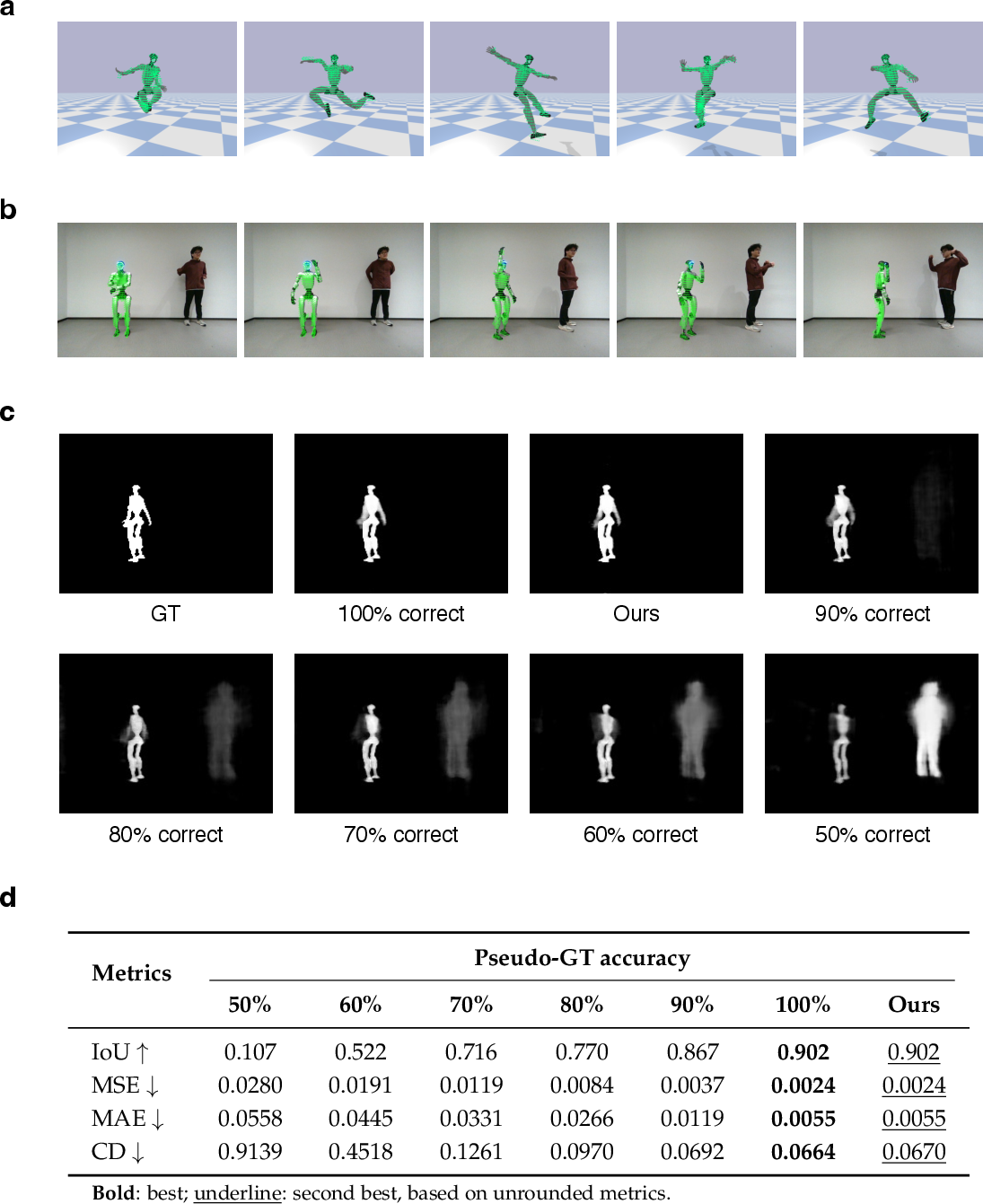
- Comparative baselines (FFKSM architecture vs. proposed part-aware/visibility-aware renderer) consistently underperform the full architecture in both qualitative and quantitative mask reconstruction.

Figure 7: Comparative 2D reconstruction showcasing benefits of the full model architecture and rendering pipeline.
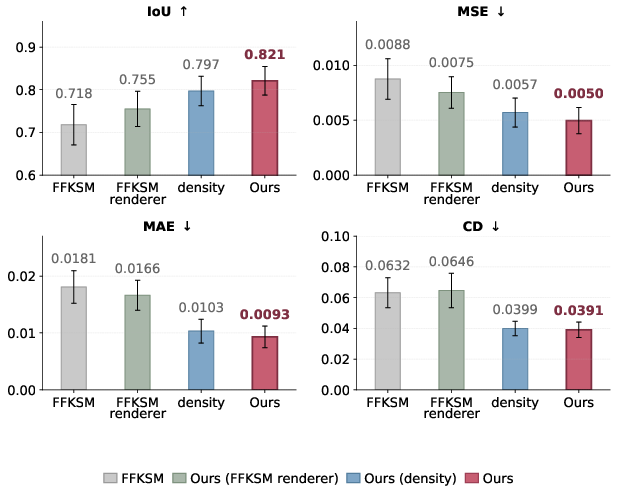
Figure 8: Quantitative evaluation of 2D reconstruction models: full model achieves highest IoU, lowest error.
Theoretical and Practical Implications
This research demonstrates that the mutually dependent problems of self-other discrimination and self-modeling can be unified and bootstrapped via inter-modality correspondence, without recourse to engineered identity, physics, or kinematics. The approach mimics the sensorimotor bootstrapping mechanism observed in humans and underpins foundational prerequisites for social interaction, imitation, and coordination in collaborative robotic settings.
Several future directions emerge:
- Scaling to denser scenes and multiple distractors.
- Integrating segmentation and tracking into an end-to-end pipeline to prevent front-end failure propagation.
- Extending the geometric self-model to encapsulate physics, enabling balance and contact-aware whole-body motion generation.
- Application to arbitrary articulated morphologies without modification to the part-aware encoding scheme.
Conclusion
The framework introduced in "Proprioceptive-visual correspondence enables self-other distinction in humanoid robots" (2606.13222) establishes that temporal congruence between proprioceptive and visual channels is a sufficient and generative principle for both identifying self in cluttered, multi-agent environments and for training actionable, differentiable geometric self-models from scratch. This work advances the operational self-representation capabilities of robots, bridging toward robust, scalable, and perceptually grounded social autonomy.