LoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
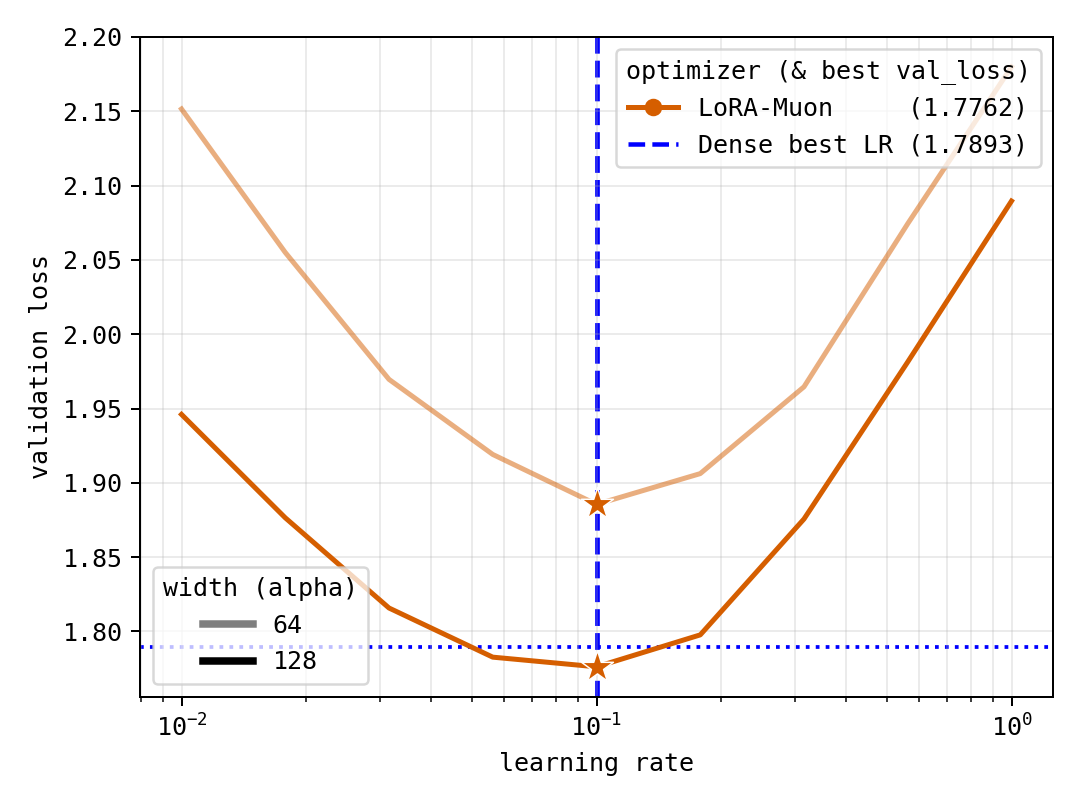
Abstract: Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models but is often harder to tune than dense training: when using factor-wise optimizers such as AdamW, it is sensitive to initialization choices, its optimal learning rates transfer poorly across ranks, and it often fails to beat dense baselines. We derive LoRA-Muon by applying the Muon optimizer's spectral steepest-descent rule to the low-rank setting. Along with our split weight-decay rule, our main claim is that LoRA-Muon is a good low-rank proxy for full-rank Muon and Shampoo-family optimizers. Its optimal learning rates transfer across rank, width, depth, and factor-rescaling. In our compute-matched TinyShakespeare study, a rank-$2$ proxy recovers the dense best tested learning rate, and a rank-$32$ LoRA-Muon run attains lower mean validation loss than the dense baseline in the seed-averaged sweep. We further show that the Spectron optimizer depends on arbitrary factor scaling, so it would likely be a poor fit when finetuning starts from badly imbalanced factors, and that LoRA-RITE's simplified QR-coordinate core implements the same spectral update. LoRA-Muon computes that update without QR-decomposition and avoids storing second moments, making it more accelerator-friendly and memory-efficient.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to fine-tune big AI models using much less memory and compute. It focuses on a popular trick called LoRA (Low-Rank Adaptation), which adds small “adapter” pieces to a model instead of changing all its billions of numbers. The authors create a new optimizer for LoRA called LoRA-Muon that makes training more stable and easier to tune, especially the learning rate.
What questions are the researchers asking?
In simple terms, they ask:
- Can we make LoRA training as easy to tune as normal (full) training?
- Can one good learning rate work well even when we change the LoRA “rank” (how big the adapter is), or the model’s width or depth?
- Can we design the optimizer so it doesn’t care about arbitrary choices in how we split the adapter into two parts (A and B), as long as their product is the same?
- Can we do all this efficiently, without extra heavy math steps or extra memory?
How do they approach the problem?
Imagine training as walking downhill to reach the lowest point in a landscape (the “loss”). A good optimizer chooses which direction to step each time:
- “Steepest descent” means always stepping in the direction where the ground falls the fastest.
- The “spectral norm” is a way to measure the strongest, most effective direction to change a matrix (think “the single direction that makes the biggest difference”).
Here’s the key idea:
- In LoRA, instead of changing a big matrix W directly, you write it as a product of two smaller matrices: W = A × Bᵀ. That saves memory and compute, but it also makes tuning tricky: you can scale A up and scale B down (or vice versa) and still get the same W. An optimizer that depends on A and B separately can get confused by this.
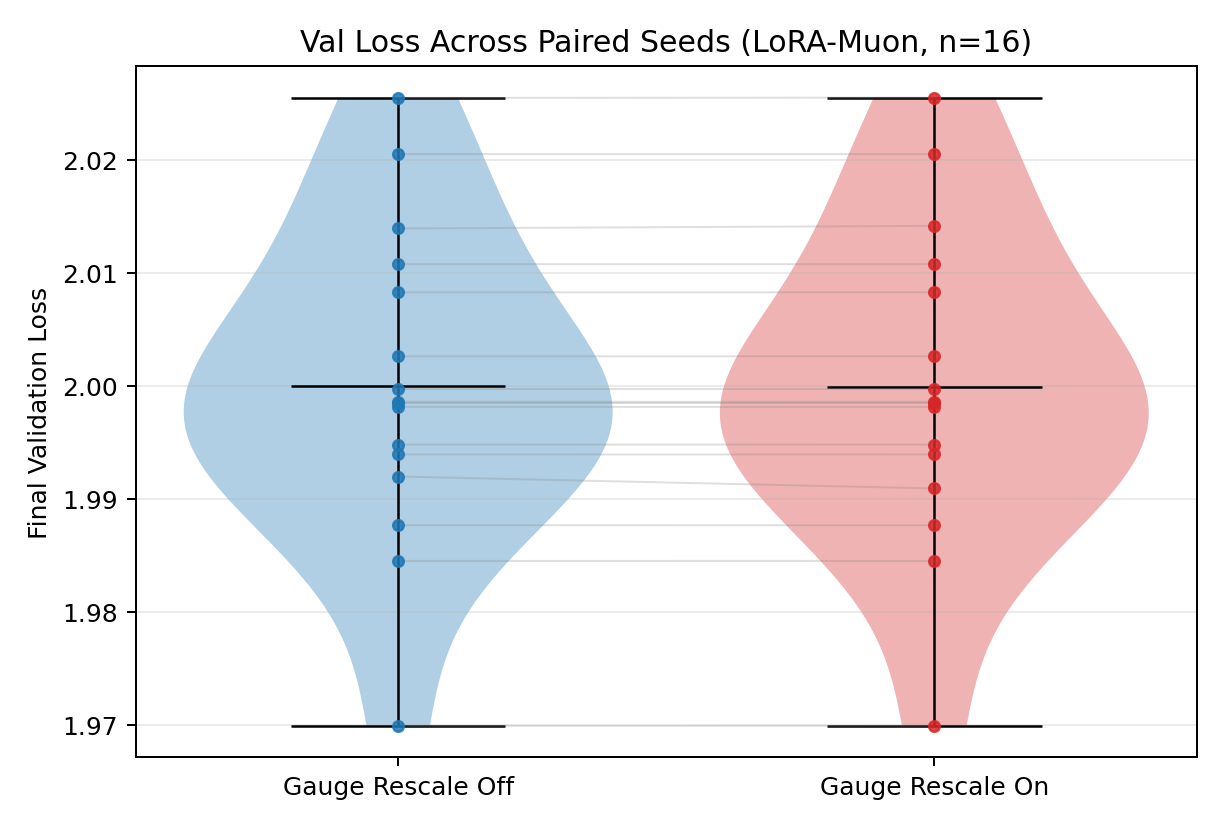
- LoRA-Muon doesn’t look at A and B separately. It figures out the best “steepest descent” step for the product W while staying in the low-rank world LoRA lives in. In other words, it chooses steps that depend on the result (W), not on how you split it (A and B). This property is called gauge invariance.
They add two practical pieces:
- Split weight decay: Weight decay is a tiny “brake” that slows training to prevent overfitting. In LoRA, if you naively apply this brake to A and B, the product W might not slow down correctly. The authors propose a split rule that makes the braking effect on W match what you’d expect from full (dense) training.
- Efficient computation: LoRA-Muon avoids expensive steps like QR decompositions and doesn’t store second moments (big extra statistics). It only needs small r×r matrices built from AᵀA and BᵀB (these are tiny when rank r is small). That makes it memory-friendly and faster on accelerators like GPUs.
Analogy:
- Think of the model as a huge machine with thousands of knobs. LoRA says, “Don’t touch all the knobs—only adjust a few special sliders (A and B) whose combination controls the machine.” LoRA-Muon says, “When you adjust those sliders, push in the single most effective direction for the combined effect, not for each slider separately.” And it makes sure the “brake” slows the combined effect properly too.
What did they find, and why does it matter?
Main findings:
- Learning rate transfer: A learning rate that works for the full model also works for LoRA-Muon across many changes—rank (how big the adapter is), model width, model depth, and even when you rescale A and B in opposite ways. That means you can use a tiny, cheap LoRA run to find a good learning rate, and then reuse it in larger or different settings.
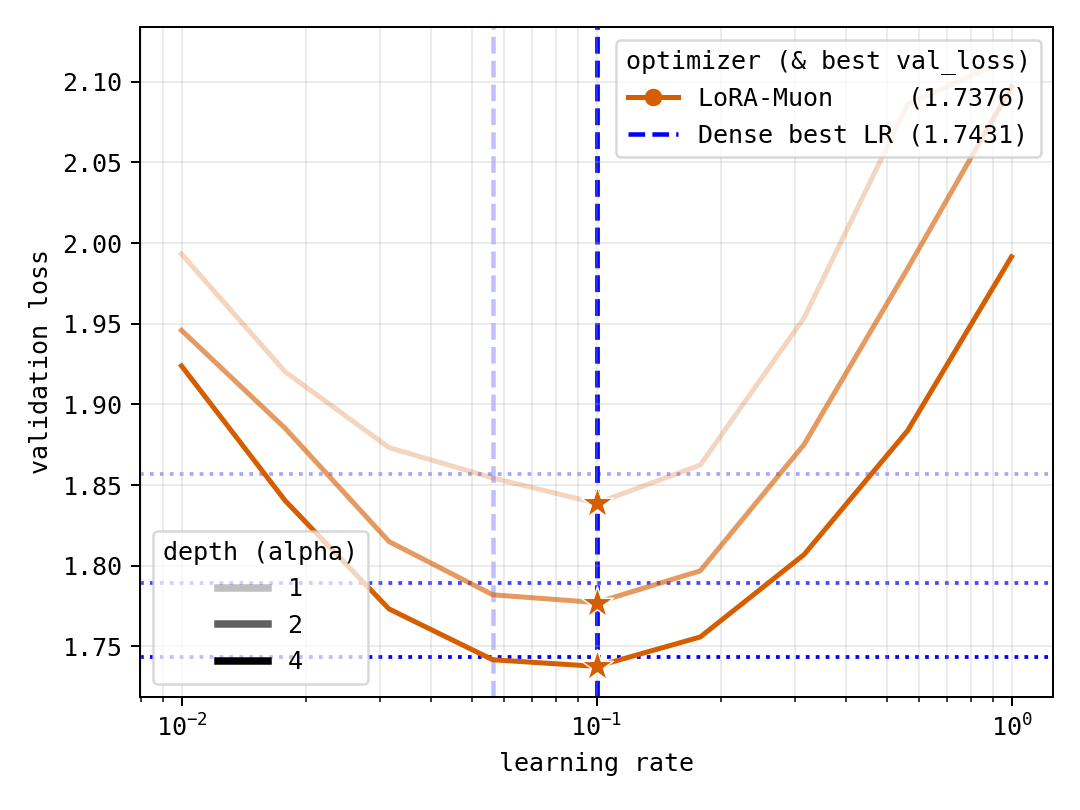
- Performance: On a small but standard test (character-level TinyShakespeare), LoRA-Muon with rank 2 (very small adapter) already points to the same best learning rate as full training. With rank 32, LoRA-Muon even achieves a lower average validation loss than the dense baseline in the tested setup.
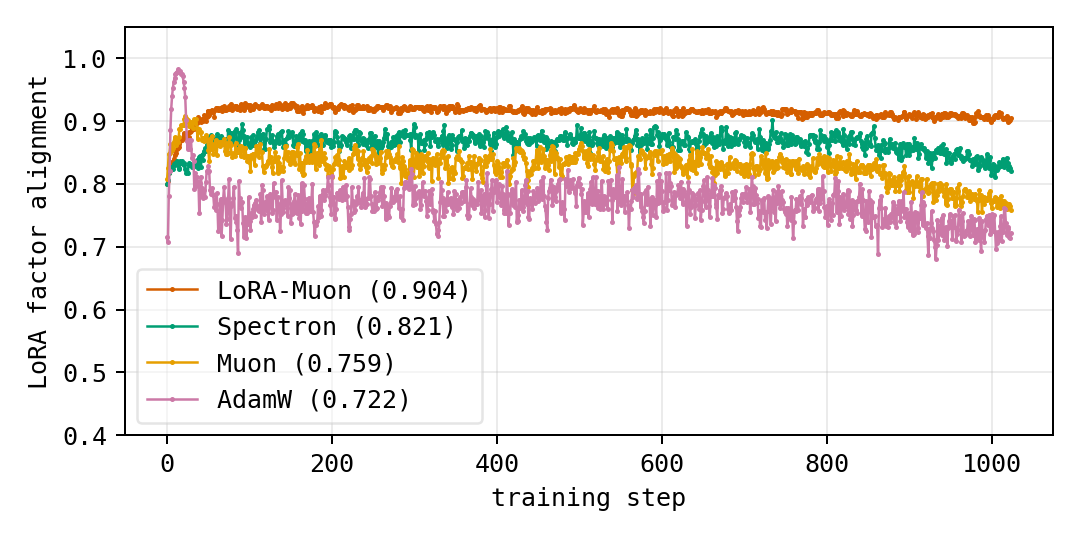
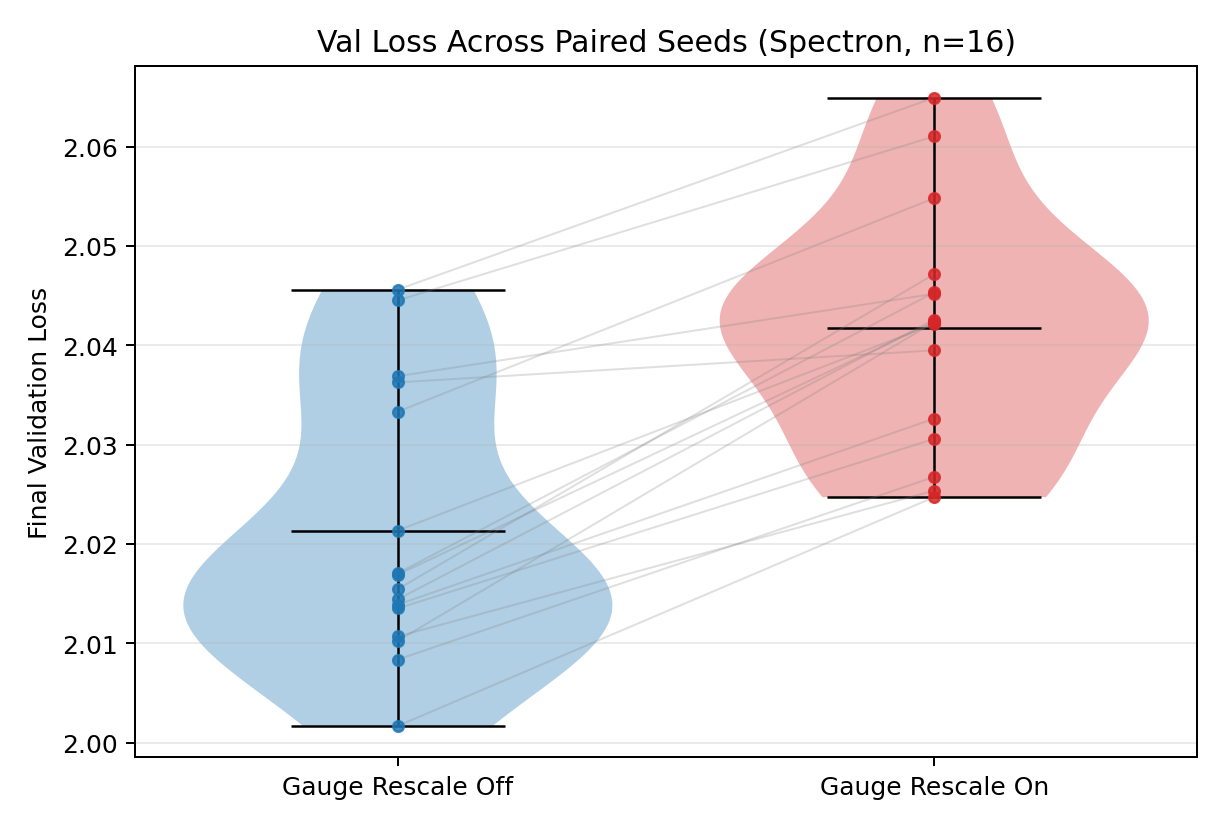
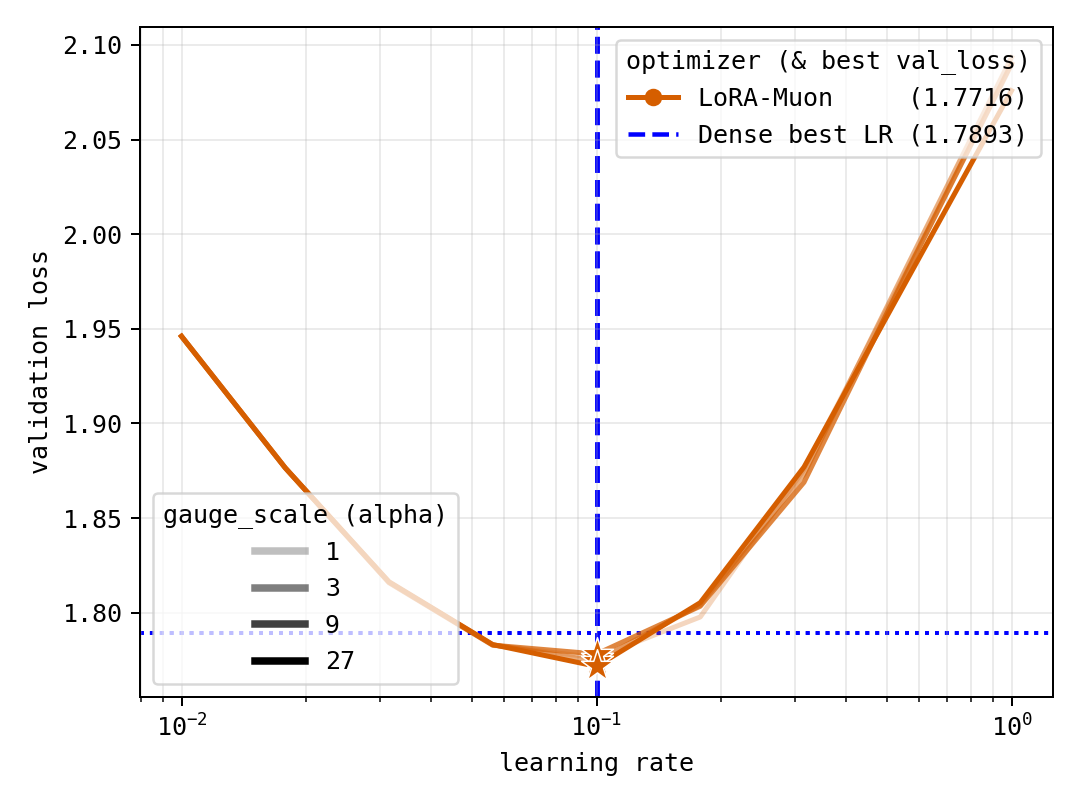
- Stability to rescaling (gauge invariance): LoRA-Muon’s updates depend only on the product W = A × Bᵀ, not on how you split it into A and B. So if you multiply A by c and divide B by c, the optimizer still behaves the same. By contrast, another method called Spectron changes its behavior under such rescaling, which can make tuning harder.
- Connection to other methods: The core mathematical update inside LoRA-RITE (another optimizer) turns out to be the same as LoRA-Muon’s core “spectral” update, just written with different math tools. But LoRA-Muon avoids QR steps and extra memory, making it more hardware-friendly.
Why it matters:
- Cheaper tuning: Finding the right learning rate is often the most important part of training. If you can find it using a tiny, low-rank setup and reuse it elsewhere, you save time, compute, and money.
- More reliable LoRA: Because LoRA-Muon is insensitive to arbitrary factor scaling and has a smart weight-decay rule, it’s easier to use and compare across setups.
- Practical efficiency: It fits real-world constraints—fewer states to store, simpler math steps, and good performance.
What’s the potential impact?
- Faster iteration: Teams can do quick, low-cost LoRA runs to pick a learning rate and then scale up with confidence.
- Less fragile fine-tuning: Stable behavior under rescaling and consistent learning-rate choices mean fewer failed runs and less guesswork.
- Broader applicability: Since the learning rate transfers across rank, width, and depth, this approach could make training and fine-tuning across different model sizes smoother.
- Industry value: LoRA is widely used in production to save memory and compute. LoRA-Muon makes LoRA easier to tune and potentially more accurate for the same budget.
In short, LoRA-Muon upgrades LoRA training so it’s simpler to tune, stable under common quirks, and efficient on modern hardware—helping people fine-tune big models with less hassle and cost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces LoRA-Muon and provides a geometric derivation plus small-scale experiments. The following specific gaps and open questions remain for future work to address:
- Scale and task generality: Validate on larger-scale LLM finetuning and pretraining (e.g., instruction tuning, multilingual MT, GLUE/SuperGLUE, vision tasks) to test whether learning-rate transfer and gauge-invariance benefits hold beyond TinyShakespeare character-level models.
- Decoupled trust-region approximation: Provide theory and experiments quantifying the gap between the true constrained low-rank steepest-descent subproblem and the paper’s decoupled “-split” approximation; derive conditions guaranteeing small approximation error and study failure modes (e.g., when tangent components are misaligned).
- Rank-1 failure analysis: Explain theoretically and empirically why fails to match dense learning-rate optima and identify thresholds (on , data, architecture) under which the method reliably succeeds.
- Adaptive budget splitting: Investigate adaptive trust-region allocation between the and components (e.g., via measured spectral alignment per step) instead of a fixed $1/2$–$1/2$ split; evaluate whether adaptive splitting improves stability or speed.
- Convergence guarantees: Establish (non)convex convergence properties of the proposed spectral steepest-descent on under momentum and split weight decay; characterize stationary points and descent guarantees.
- Stability under ill-conditioning: Analyze and mitigate cases where or becomes ill-conditioned or singular (e.g., early training or zero-initialized factors); specify regularization of (e.g., ), its impact on gauge invariance, and robustness.
- Efficient and stable computation of : Provide implementation strategies, complexity, and numerical stability for computing the matrix sign for tall/rectangular matrices at scale (e.g., Krylov/iterative sign methods, randomized SVD, Polar-iteration variants) and evaluate GPU/TPU performance and mixed-precision behavior.
- Momentum and second moments: Assess whether adding second-moment statistics (e.g., Adam-like or Shampoo-like preconditioning in factor space) improves stability or speed without breaking the spectral steepest-descent interpretation; test the extent to which learning-rate transfer persists across momentum schedules.
- Split weight decay residual: Quantify the magnitude and training impact of the residual cross-term in , especially early in training or at larger ; compare against alternative product-regularization schemes and schedules for .
- Full gauge tests: Empirically test invariance beyond scalar rescaling (i.e., general transforms) and study the practical interaction between gauge rebalancing frequency, transported optimizer state, and numerical precision.
- Initialization dependencies: Evaluate performance under common LoRA initializations (e.g., zero-initialized with scaled ), especially when is initially singular; propose safe bootstrapping strategies and their effect on early training dynamics.
- Beyond spectral norm: Explore empirical performance for other unitarily invariant norms (e.g., Frobenius, Schatten-) using the derived LMO framework; determine if certain norms yield better generalization or stability for specific architectures or tasks.
- Layer-wise scaling: Test whether a single global learning rate truly transfers across layers of different widths/depths in larger models; compare to per-layer scaling rules and examine interactions with residual-scaling and normalization.
- Interactions with training tricks: Study the interplay with gradient clipping, mixed-precision, RMSNorm/LayerNorm, dropout, residual scaling, and scheduling (warmup/cosine); specify recommended practices for stable large-scale training.
- Comparison breadth and fairness: Extend empirical comparisons with Spectron and LoRA-RITE to diverse tasks and scales under matched compute and strict ablation controls (including QR-cost vs benefit, second-moment states, and escaped-mass mechanisms).
- Generalization to other modules: Evaluate applicability and gains when applied to embeddings, convolutional layers, and cross-attention blocks; determine where spectral-steepest updates are most beneficial.
- Pretraining vs finetuning regimes: Separate analyses for native low-rank pretraining and parameter-efficient finetuning; measure downstream robustness (e.g., catastrophic forgetting, out-of-distribution generalization).
- Hyperparameter scaling laws: Empirically validate the claimed coupling between optimal learning rate and weight decay/batch size/training horizon in the LoRA-Muon setting as width/depth/data scale, rather than relying only on cited theory.
- Long-horizon and batch-size robustness: Test stability and performance under larger batch sizes and longer training horizons; characterize gradient-noise sensitivity and potential need for noise-aware adjustments.
- Quantization and low-precision adapters: Examine compatibility with 8-bit/4-bit adapter quantization and low-precision matrix-root/sign computations; quantify accuracy–throughput trade-offs and mitigation strategies.
- Dynamic rank adaptation: Develop and test procedures for changing rank during training (growth/pruning) while preserving gauge invariance and momentum state consistency.
- Formal link to Shampoo-family updates: Provide rigorous conditions (or counterexamples) under which LoRA-Muon is a “good proxy” for Muon/Shampoo in terms of update geometry and training outcomes; quantify approximation error of spectral norms and their practical impact.
- Handling degeneracies in : Analyze cases with repeated singular values or sign ambiguity in ; propose deterministic tie-breaking to ensure update continuity and reproducibility.
- Systems-level performance: Report wall-clock, memory bandwidth, and kernel-level profiling on GPUs/TPUs for LoRA-Muon vs AdamW-LoRA, Spectron, and LoRA-RITE; identify bottlenecks and opportunities for fusion/parallelization.
- Safety and robustness: Assess behavior under noisy/adversarial gradients, distribution shifts, and data sparsity; determine whether spectral steepest descent confers robustness advantages or vulnerabilities.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods and insights, given standard deep learning tooling (e.g., PyTorch/JAX/TensorFlow) and existing LoRA workflows.
- Low-cost hyperparameter search via low-rank proxies
- Sector: software/AI, MLOps, cloud computing
- Use case: Run rank-2–32 LoRA-Muon sweeps to select the learning rate (and then infer weight decay, batch size, momentum via scaling laws) for subsequent dense or high-rank training with Muon/Shampoo-family optimizers.
- Tools/workflows:
- Integrate LoRA-Muon as a drop-in optimizer in PEFT libraries (e.g., Hugging Face PEFT), with a “proxy LR search” pipeline stage.
- CI/MLOps: automatically run a small rank-2 sweep on new tasks/models to lock learning rate before full training.
- Assumptions/dependencies: LR transfer is demonstrated on TinyShakespeare-scale; empirical validation at larger scales recommended before relying exclusively on proxy-based LR selection.
- More stable, easier-to-tune LoRA finetuning
- Sector: software/AI; industry finetuning of LLMs and vision models
- Use case: Replace AdamW-on-factors or gauge-sensitive methods (e.g., Spectron) with LoRA-Muon to reduce sensitivity to LoRA rank, factor initialization, and imbalanced factor scales.
- Tools/workflows:
- Implement the LoRA-Muon step (msign-based spectral update with Gram whitening and split weight decay) in existing LoRA adapters.
- Provide a “gauge rebalancing” utility (optional) to condition factors without altering training dynamics.
- Assumptions/dependencies: Requires computing inverse square roots of small Gram matrices per layer (r×r), and a numerically robust matrix sign routine; both are feasible on modern accelerators.
- Memory- and compute-efficient finetuning on commodity hardware
- Sector: SMEs, startups, education, edge/cloud
- Use case: Finetune medium-scale language and vision models on consumer GPUs or limited cloud budgets by exploiting LoRA-Muon’s QR-free, first-moment-only, memory-efficient design.
- Tools/workflows:
- “Low-memory LoRA” profiles in training scripts that activate LoRA-Muon and split weight decay.
- Education/research labs can adopt LoRA-Muon to reduce costs for class projects and small-scale research.
- Assumptions/dependencies: Benefits are clearest when LoRA-targeted layers dominate training FLOPs/memory; model architectures that heavily use non-LoRA layers will see smaller savings.
- Standardized, rank-robust finetuning across product lines
- Sector: enterprise AI platforms, multi-tenant model hosting
- Use case: Set one “house” learning rate for families of adapters/models (varying in depth/width/rank) and expect similar performance profiles due to gauge-invariant spectral steepest descent on the low-rank manifold.
- Tools/workflows:
- Organization-wide hyperparameter catalog with a single LR baseline for LoRA-Muon across task variants.
- A/B testing frameworks that vary rank without retuning LR for each configuration.
- Assumptions/dependencies: Empirically validated for rank > 1; rank-1 adapters may require separate tuning.
- Domain-specific LLM adaptation with reduced operational risk
- Sector: healthcare, finance, legal, customer support, education
- Use case: Finetune domain LLMs (e.g., medical coding, compliance Q&A, tutoring assistants) with fewer training instabilities caused by factor scaling and optimizer mismatch.
- Tools/workflows:
- Add LoRA-Muon as an option in enterprise finetuning UIs (with guardrails using split weight decay).
- Faster iteration cycles for pilot deployments due to lower LR sensitivity and reduced compute.
- Assumptions/dependencies: Regulatory/compliance considerations are unchanged; the method reduces compute/cost risk but not data governance requirements.
- Greener AI by design through compute-efficient training
- Sector: sustainability/ESG in AI operations; cloud procurement
- Use case: Cut energy and carbon footprint for repeated finetunes by using LoRA-Muon as a stable, low-rank optimizer with proxy LR search prior to large runs.
- Tools/workflows:
- Include “low-rank proxy search” step in green-AI policies and model cards.
- Report estimated FLOP savings and emissions reductions with LoRA-Muon adoption.
- Assumptions/dependencies: Carbon savings depend on actual compute usage and data center energy mix; verification requires metering.
- Research and teaching: hands-on modules for non-Euclidean optimization
- Sector: academia
- Use case: Classroom labs and research prototypes illustrating steepest descent under spectral norms on low-rank manifolds, gauge invariance, and practical impacts on training stability.
- Tools/workflows:
- Provide reference implementations in PyTorch/JAX.
- Comparative labs vs. AdamW-on-factors, Spectron, and LoRA-RITE cores.
- Assumptions/dependencies: Students need basic linear algebra/SVD background; small datasets suffice.
Long-Term Applications
These opportunities likely require additional validation at scale, integration work, or broader ecosystem support.
- Default LoRA optimizer for large-scale pretraining and finetuning
- Sector: foundation models (LLMs, multimodal), cloud providers
- Use case: Replace existing LoRA optimizers in large pretraining runs to improve stability across depth/width/rank and simplify global hyperparameter management.
- Tools/products:
- Framework-level inclusion in PyTorch/TF/JAX as a built-in optimizer.
- Managed cloud training services offering “LoRA-Muon by default” profiles.
- Assumptions/dependencies: Needs empirical confirmation on very large datasets and models; kernel-level performance tuning for matrix sign and invroot may be required.
- Hardware–software co-design for spectral updates on accelerators
- Sector: semiconductor, systems engineering
- Use case: Provide fused kernels for Gram inverse square roots and msign to minimize overheads for many LoRA layers.
- Tools/products:
- CUDA/ROCm/TPU primitives for batched small-matrix invroot and msign.
- Compiler passes that detect LoRA-Muon patterns and fuse operations.
- Assumptions/dependencies: Vendor support; numerical stability strategies for near-singular Gram matrices.
- Adaptive rank selection and scheduling
- Sector: AutoML, MLOps
- Use case: Dynamically adjust LoRA rank during training (e.g., start at rank-2 for LR search, ramp to higher ranks where needed) while keeping LR stable via LoRA-Muon’s transfer properties.
- Tools/products:
- Auto-tuners that couple rank schedules with LR fixed by proxy runs.
- Dashboards that visualize spectral alignment and suggest rank changes.
- Assumptions/dependencies: Requires criteria for when to increase rank; impacts on convergence and downstream metrics need study.
- Extensions to other low-rank/tensor decompositions
- Sector: vision, speech, recommender systems, scientific ML
- Use case: Apply the same manifold-steepest-descent design to CP/Tucker/TT decompositions and low-rank convolutional kernels to stabilize parameter-efficient training beyond LoRA.
- Tools/products:
- Generalized manifold optimizers with plug-in norms and decompositions.
- Libraries that unify LoRA, low-rank convs, and tensorized layers under one API.
- Assumptions/dependencies: Geometry and gauge properties differ for other decompositions; additional theory and engineering needed.
- Automated hyperparameter scaling suites
- Sector: enterprise AI, MLOps
- Use case: Use LoRA-Muon’s stable LR as the anchor for automatic recommendation of weight decay, batch size, training horizon, and momentum per scaling laws.
- Tools/products:
- “One-click” hyperparameter planners using LR from a short proxy sweep.
- Policy engines that enforce consistent hyperparameters across model families.
- Assumptions/dependencies: Scaling-law generality varies by domain and architecture; monitoring and guardrails recommended.
- Personalized and on-device continual adaptation
- Sector: mobile/edge AI, privacy-preserving personalization
- Use case: Stable, compute-lean on-device finetuning of assistant models (e.g., keyboard prediction, accessibility tools) where memory and energy are constrained.
- Tools/products:
- Mobile runtimes with LoRA-Muon kernels and small-batch optimizers.
- Privacy-first apps that update local adapters without cloud retraining.
- Assumptions/dependencies: Efficient on-device linear algebra and SVD approximations; battery and thermal limits.
- Safety-critical model adaptation with reduced optimizer-induced variance
- Sector: healthcare diagnostics, finance risk models, autonomous systems
- Use case: Reduce optimizer-induced instability during adapter training by using gauge-invariant updates; facilitate reproducibility and auditability.
- Tools/products:
- Validation suites that compare model behavior under gauge rebalancing to detect optimizer sensitivity.
- Governance checklists that prefer gauge-invariant training in regulated settings.
- Assumptions/dependencies: Domain-specific validation still required; LoRA-Muon manages optimization stability but not data or model bias.
- Sustainability and procurement standards
- Sector: policy, ESG
- Use case: Encourage “low-rank proxy LR search” and parameter-efficient optimizers (like LoRA-Muon) in RFPs and organizational AI standards to reduce training emissions.
- Tools/products:
- Reporting templates that quantify FLOP/energy savings from LoRA-Muon.
- Procurement criteria that reward compute-efficient, gauge-invariant methods.
- Assumptions/dependencies: Broad consensus on measurement and verification; alignment with organizational incentives.
- Cross-modal and multi-task adapters with unified hyperparameters
- Sector: multimodal AI (vision-language, speech-language)
- Use case: Maintain a common LR for adapters across modalities and tasks, simplifying platform-wide deployment and reducing tuning overhead.
- Tools/products:
- Adapter hubs that host many tasks/modalities with standardized optimizer settings.
- Assumptions/dependencies: Empirical LR transfer must be verified across modalities; interaction with modality-specific normalizations may matter.
Notes on feasibility across all applications:
- The paper’s strongest empirical evidence is on TinyShakespeare-scale models; larger-scale benchmarks are a key dependency for broad adoption.
- Implementation requires stable numerical routines for msign and r×r Gram inverse square roots; these are tractable but should be tested per hardware stack.
- LoRA-Muon addresses optimization geometry and stability; it does not mitigate data quality, privacy, or fairness risks, which must be handled separately.
Glossary
- Ambient gradient: The gradient of the loss with respect to the composed weight matrix rather than factor parameters. "the ambient gradient $G_t = \nabla_W f(W_{\mathrm{pre} + W)$"
- Compute-matched: Experimental setup where training steps or tokens are adjusted so different methods use equal computational budget. "In our compute-matched TinyShakespeare experiments, a rank-$2$ LoRA-Muon proxy already recovers the best tested learning rate for dense Muon."
- Differential manifold: A smooth geometric space locally resembling Euclidean space, here the set of fixed-rank matrices. "This is a differential manifold of matrices"
- Factor-wise optimizers: Optimizers that treat each factor in a matrix factorization as an independent parameter block. "when using factor-wise optimizers such as AdamW, it is sensitive to initialization choices"
- FlexAttention: A programming model/system for efficient fused attention variants. "and FlexAttention \cite{dong2024flexattention};"
- FLOPs: Floating-point operations, a measure of computational cost. "it cuts both training FLOPs and accelerator memory requirements"
- Gauge invariance: Property that updates depend only on the product , not on the particular factorization, and remain unchanged under gauge transformations. "our update is invariant under gauge transformations of the LoRA factors."
- Gauge rebalancing: Rescaling factors by inverse scalars to improve conditioning without changing the induced update on . "The same symmetry also justifies scalar gauge rebalancing as a numerical conditioning tool."
- Gauge transformation: Change of LoRA factors that leaves the product matrix unchanged, typically . "our update is invariant under gauge transformations of the LoRA factors."
- General linear group (GL(r)): The group of invertible matrices. "."
- GELU: Gaussian Error Linear Unit, an activation function used in neural networks. "GELU MLPs \cite{hendrycks2016gelu} with hidden-width expansion;"
- Gram geometry: Geometry induced by the Gram matrices and , used to whiten factor gradients. "we whiten the factor gradients by the current Gram geometry"
- Linear Minimization Oracle (LMO): Subroutine that returns the descent direction solving a linearized optimization over a norm ball. "We derive a family of Linear Minimization Oracles (LMOs) for steepest descent in the low-rank manifold under unitary-invariant norms."
- Linearized subproblem: The constrained optimization of a first-order Taylor approximation within a trust region. "then yields the constrained linearized subproblem"
- LoRA (Low-Rank Adaptation): Technique that fine-tunes models by learning low-rank updates to weight matrices. "Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models"
- LoRA-Muon: The proposed optimizer applying Muon’s spectral steepest descent on the low-rank manifold with gauge-invariant updates. "LoRA-Muon is the spectral specialization of \eqref{eq:projector-lmo}."
- LoRA-RITE: A LoRA optimizer whose simplified QR-coordinate core matches LoRA-Muon’s spectral update. "The simplified QR-coordinate core of LoRA-RITE realizes the same spectral steepest-descent update as LoRA-Muon"
- Low-rank manifold: The set of matrices with fixed rank , treated as a smooth manifold for optimization. "directly solving the steepest descent problem in the low-rank manifold, , instead."
- Matrix inverse square root: The matrix satisfying , used here to whiten Gram matrices. ""
- Matrix sign function (msign): The function returning for SVD , giving spectral-norm steepest-descent directions. "the linear minimization oracle over the spectral norm ball is the matrix sign function,"
- Muon optimizer: An optimizer that performs steepest descent under the spectral norm in full matrix space. "the Muon optimizer performs steepest descent under the spectral norm in "
- Projector (column projector): Orthogonal projector onto a factor’s column space, e.g., . "the -side objective depends only on the column projector "
- Projector-form update: Expression of the update using projectors onto factor subspaces, clarifying gauge invariance. "This viewpoint gives a simple projector-form update"
- QR coordinates: Parameterization using QR factorizations to express factors with orthonormal columns. "simplified QR-coordinate core"
- QR decomposition: Factorization of a matrix into an orthonormal factor and an upper-triangular factor; avoided in LoRA-Muon for efficiency. "without QR-decomposition and avoids storing second moments"
- Residual scaling: Scaling of residual connections by a factor depending on depth to stabilize training. "residual scaling following the modular-norm-style parametrization of \cite{large2024modular}."
- RMS normalization: Root Mean Square layer normalization variant that normalizes activations by their RMS. "RMS normalization without affine parameters"
- RoPE (Rotary Position Embedding): Positional encoding method that applies rotations to queries and keys in attention. "RoPE \cite{su2021roformer}"
- Seed-averaged sweep: Hyperparameter sweep where results are averaged over multiple random seeds. "attains lower mean validation loss than the dense baseline in the seed-averaged sweep."
- Shampoo-family optimizers: Preconditioned second-order optimizers that, like Muon, produce updates with matched spectral norms. "the Shampoo-family of optimizers"
- Singular Value Decomposition (SVD): Factorization expressing a matrix via singular values and orthonormal vectors. "For a rectangular SVD , we use the standard convention ."
- Spectral norm: The largest singular value of a matrix; the norm defining Muon’s steepest-descent geometry. "performs steepest descent under the spectral norm"
- Spectral renormalization: Heuristic that rescales factors or gradients based on spectral properties rather than invariant geometry. "We therefore view Spectron as a spectral, factor-coordinate renormalization heuristic"
- Spectral specialization: Choosing the spectral norm within a general family of unitary-invariant norms to define the update. "LoRA-Muon is the spectral specialization of \eqref{eq:projector-lmo}."
- Split weight decay: A rule distributing weight decay across factors so the induced decay on matches the dense case. "We derive a split weight-decay rule that ensures weight norms and step sizes in the full-rank and low-rank settings match."
- Steepest descent: Optimization step that moves in the direction minimizing the linearized objective under a chosen norm. "solve the steepest descent problem there, rather than first optimizing and as if they were independent coordinates."
- Tangent space: The linear space of allowable instantaneous directions at a point on a manifold; here, rank-preserving directions. "projects it onto the tangent space of the low rank manifold."
- Triangle inequality relaxation: Using the triangle inequality to bound and decouple constraints, e.g., splitting a trust region between two terms. "By the triangle inequality, any pair of feasible solutions to \eqref{eq:lora-decoupled-a}--\eqref{eq:lora-decoupled-b} satisfies,"
- Trust region: A constraint limiting step size to remain within a region where linearization is accurate. "a hard trust-region constraint"
- Unitarily invariant norm: Matrix norm unchanged by left/right multiplication by orthogonal/unitary matrices (e.g., spectral, Frobenius). "for any unitarily invariant norm:"
- Unitary invariance: Property that a quantity (e.g., norm) does not change under orthogonal/unitary transformations. "Unitary invariance lets the two decoupled constraints in \eqref{eq:lora-decoupled-a}--\eqref{eq:lora-decoupled-b} collapse onto the projector terms."
- Whitening: Preconditioning gradients by (inverse) square roots of Gram matrices to normalize scales. "we whiten the factor gradients by the current Gram geometry"
Collections
Sign up for free to add this paper to one or more collections.

