- The paper demonstrates that feedback alignment suffers from rank collapse, restricting gradient updates to low-dimensional subspaces and impairing learning.
- It introduces the Muon optimizer and batch normalization to orthogonalize updates and maintain high-dimensional gradient geometry in deep architectures.
- Empirical results reveal that these interventions substantially boost test accuracy in deep CNNs, improving FA's scalability and convergence.
Overcoming Rank Collapse in Feedback Alignment: An Expert Analysis
Motivation and Context
Backpropagation (BP) continues to underpin modern deep learning, but its reliance on symmetric weight transport is widely regarded as neurobiologically implausible. Feedback Alignment (FA) replaces this requirement by propagating errors through fixed random feedback matrices, thereby circumventing the weight transport problem. While FA can attain satisfactory performance in shallow multilayer perceptrons (MLPs) and small convolutional networks, its efficacy severely degrades as network depth increases, particularly in convolutional neural networks (CNNs) applied to challenging benchmarks. This persistent limitation has cast doubt on the suitability of FA as a scalable alternative to BP, both for artificial and potentially neurobiological systems.
The paper "Overcoming Rank Collapse in Feedback Alignment" (2606.11123) identifies and systematically addresses the geometric causes of FA's poor scalability. Through a comprehensive suite of experimental analyses, the authors attribute the failure of deep FA to a form of "rank collapse": the gradients propagated by FA quickly become low-dimensional, confining parameter updates to restricted subspaces. This, in turn, impedes alignment and limits the diversity of learnable representations. The study proposes and empirically validates several interventions—namely, orthogonalised update rules (Muon) and batch normalization (BN)—to prevent rank collapse, substantially ameliorating FA performance in deep networks.
Diagnosis of Rank Collapse in Feedback Alignment
The authors first provide a rigorous quantitative comparison of the geometric properties of BP and FA in convolutional networks of varying depth trained on CIFAR-10. The key finding is that, while BP gradients maintain high effective rank (measured via the exponentiated entropy of the normalised singular values), FA gradients rapidly collapse onto a low-rank subspace, with effective ranks declining precipitously as layers are added.
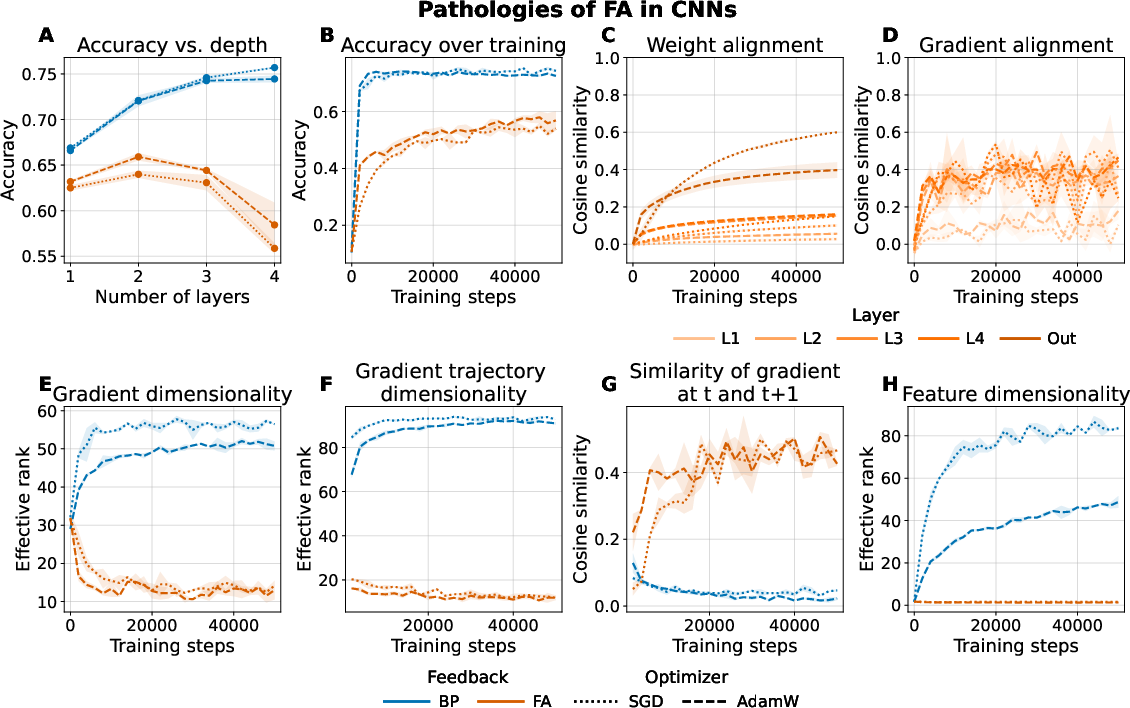
Figure 1: FA suffers from low dimensional gradients; gradient and feature rank shrink as depth increases, inhibiting effective exploration and alignment.
Layerwise cosine alignment metrics reveal that only the uppermost layers in FA achieve notable weight and gradient alignment, while lower layers stagnate. The restricted dimensionality of the propagated error results in highly redundant features and slow convergence. Intriguingly, the trajectory of FA gradients throughout training also becomes degenerate, as indicated by the low effective rank of their Gram matrices—an effect exacerbated by increasing depth.
Increasing Gradient Dimensionality: Muon Optimizer and Batch Normalization
Given this geometric diagnosis, the study seeks practical mechanisms to maintain or restore gradient and representation dimensionality in FA. Two distinct interventions are evaluated:
1. Orthogonalised Update Rules via Muon Optimizer:
The Muon optimizer applies a singular value decomposition (SVD)-based orthogonalisation to the momentum update, thereby ensuring that the update explores all non-zero singular directions uniformly. This directly counteracts the low-rank bias of standard update rules and amplifies effective rank.
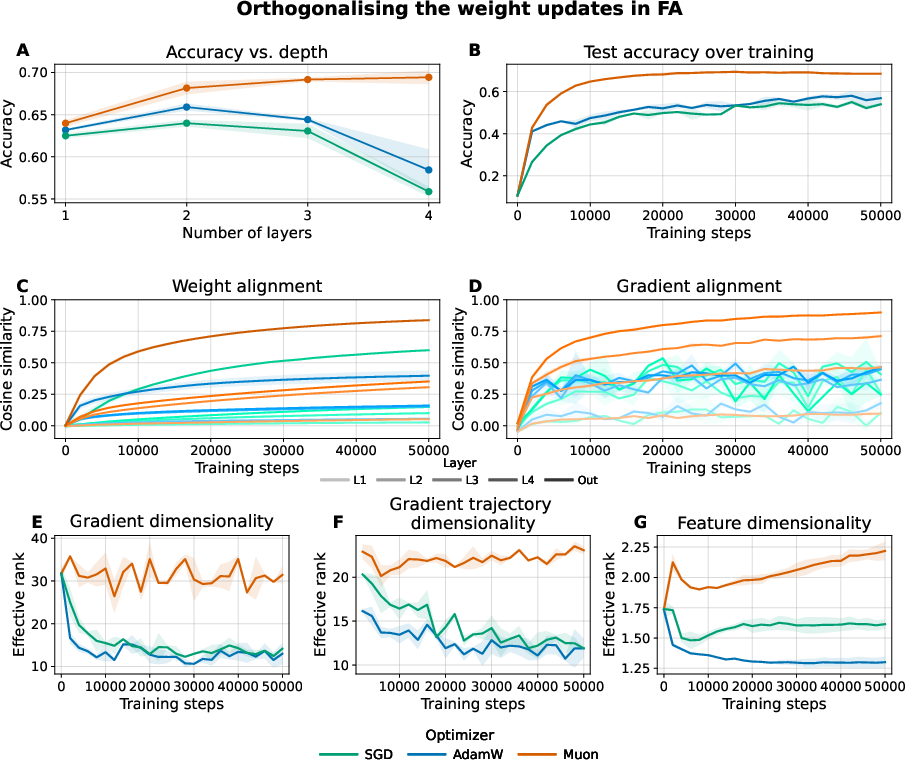
Figure 2: Orthogonalising updates with Muon reverses the accuracy decline of FA with increasing network depth, improves gradient/weight alignment, and preserves high-dimensional update geometry.
Empirically, Muon dramatically improves FA's test accuracy on deep four-layer CNNs (e.g., from 59.5% with AdamW to 69.5%), accelerates training, and yields smoother and more robust alignment dynamics. Notably, the performance of FA no longer deteriorates with increasing depth, a stark departure from baseline optimizers.
2. Activity Normalization via Batch Normalization (BN):
Batch normalization is incorporated to directly prevent representational collapse by promoting orthogonality in hidden activities, which, by extension, increases gradient dimensionality.
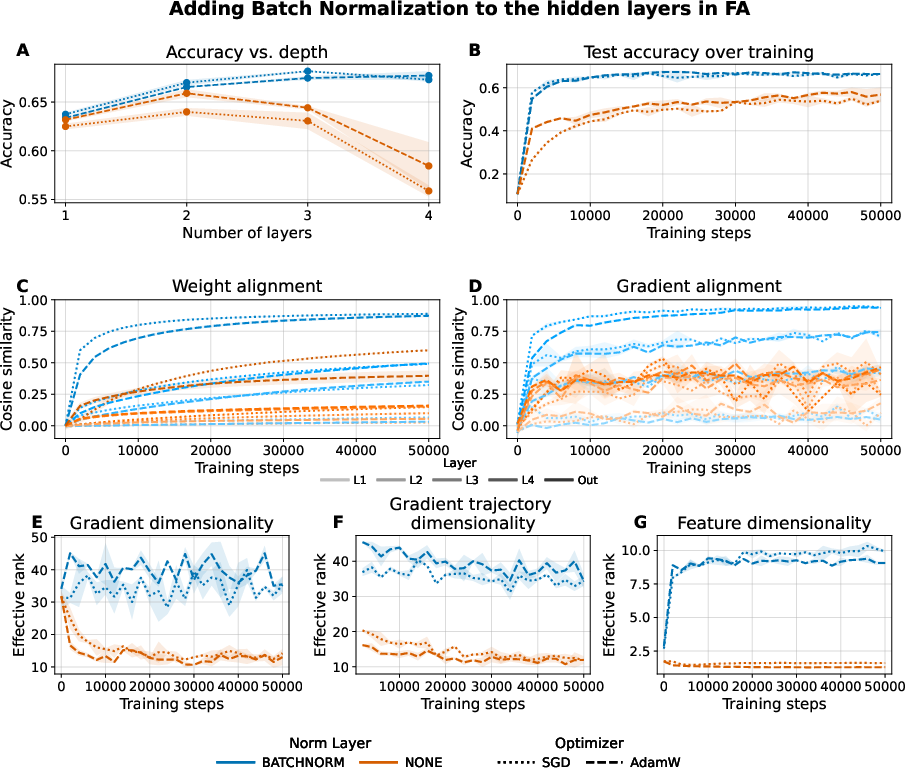
Figure 3: Adding batch normalization yields higher feature and gradient ranks, accelerates FA convergence, and ensures more stable alignment across layers.
BN proves similarly effective as Muon: it mitigates the decline in FA performance with depth, enhances gradient and feature dimensionality, and stabilizes both training and alignment processes.
Alternative Dimensionality-Enhancing Interventions
The study further evaluates local decorrelation losses to decorrelate hidden activations, which, by increasing representational diversity, synthetically boosts gradient rank.
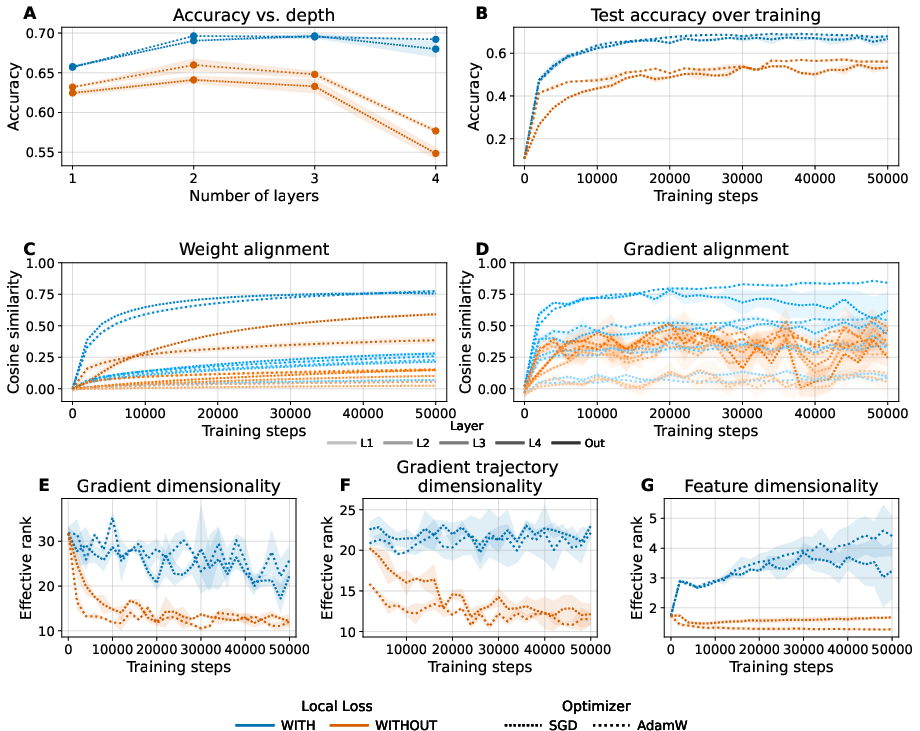
Figure 4: Adding a local loss to enforce activity decorrelation further increases the dimensionality of both gradients and features, improving accuracy and alignment stability.
While effective in small models, such methods require careful tuning for scalability to larger architectures.
Scaling Experiments: Generalization to Deep Architectures and Difficult Tasks
To test the generality of the interventions, the authors conduct scaling experiments on AlexNet and ResNet-18 trained on STL-10, CIFAR-100, and Tiny Imagenet. Baseline FA performance is near-chance in deep settings, e.g., <2% accuracy for ResNet-18 in CIFAR-100 and Tiny Imagenet. Both Muon and BN individually provide marked gains, but their combination is synergistic, e.g., pushing ResNet-18/FA accuracy on CIFAR-100 to 46.1%.
These improvements, while still not fully closing the gap to BP, establish that geometric failures—specifically, the collapse of gradient and representation rank—are principal obstacles to scaling FA. Interventions that systematically enforce high-dimensional update geometry restore substantial alignment and learning ability, even in deep convolutional architectures.
Mechanistic Dissection: Update Geometry and Its Limits
The study differentiates mechanisms that generically increase update dimensionality:
Moreover, interpolation experiments with the Freon optimizer demonstrate that performance improves monotonically as the singular value spectrum is flattened to be more uniform, peaking when all meaningful singular directions are equally weighted.
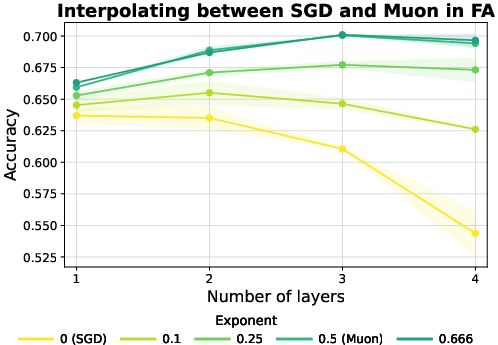
Figure 6: A more balanced singular value spectrum, as controlled by Freon, maximizes FA performance, further implicating rank preservation as key.
Layerwise and Depth-Dependent Analyses
Extensive appendices show that these dimensionality trends hold across all convolutional layers and as depth increases:
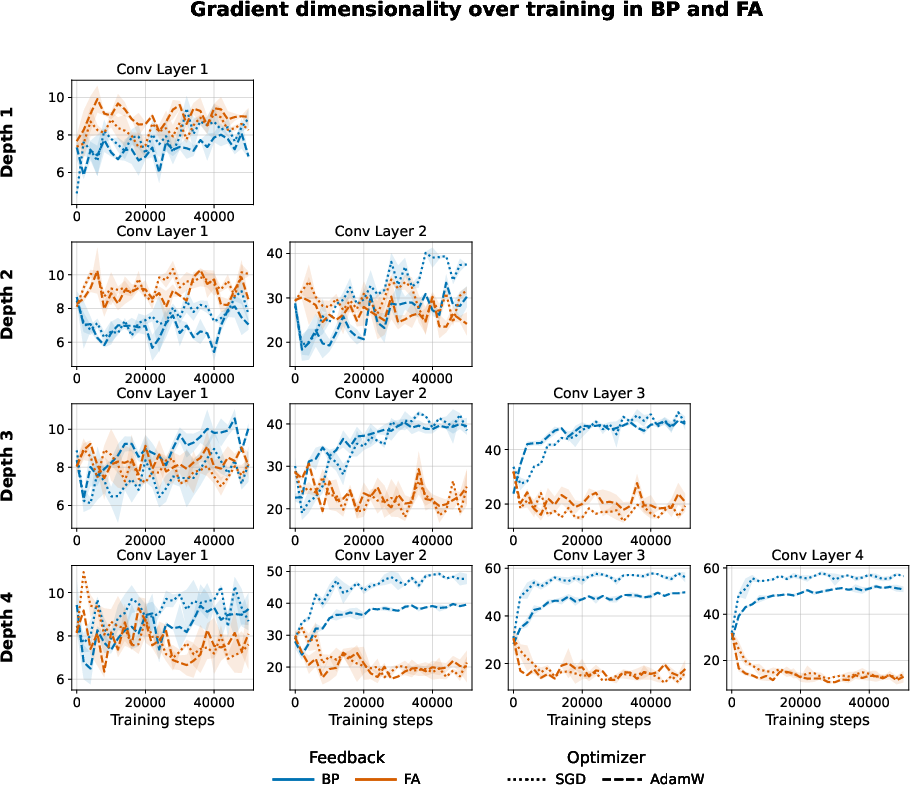
Figure 7: FA has lower gradient dimensionality across layers and depths.
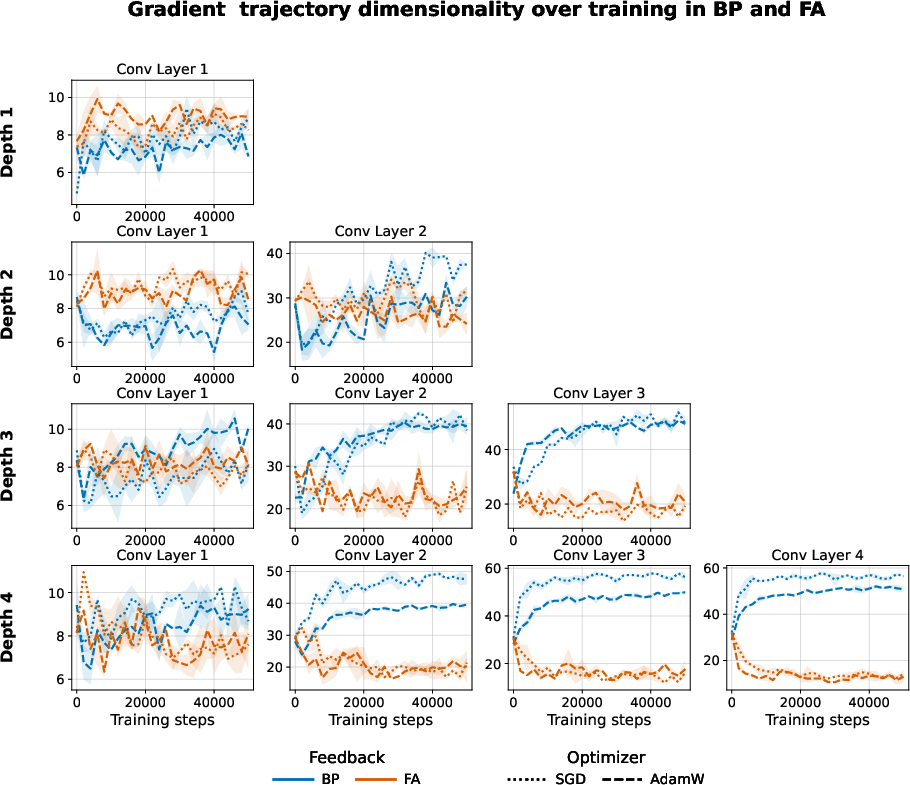
Figure 8: FA exhibits lower-dimensional gradient trajectories across both layers and depths.
Interventions such as Muon and BN consistently raise effective rank throughout the entire network:
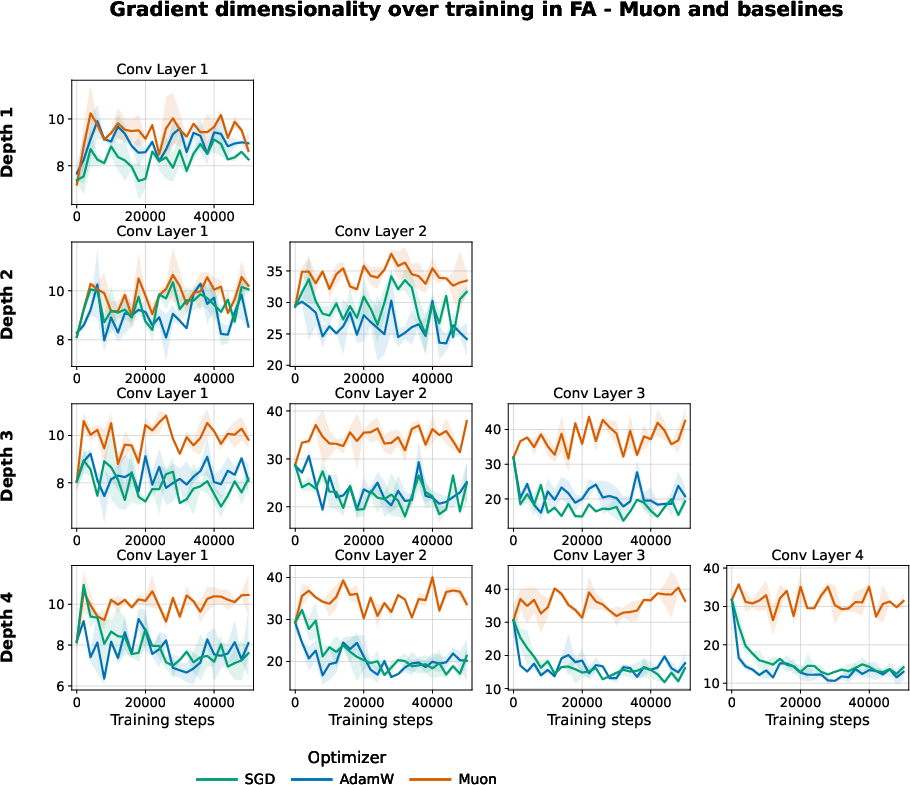
Figure 9: Muon elevates gradient dimensionality in FA networks across layers and depths.
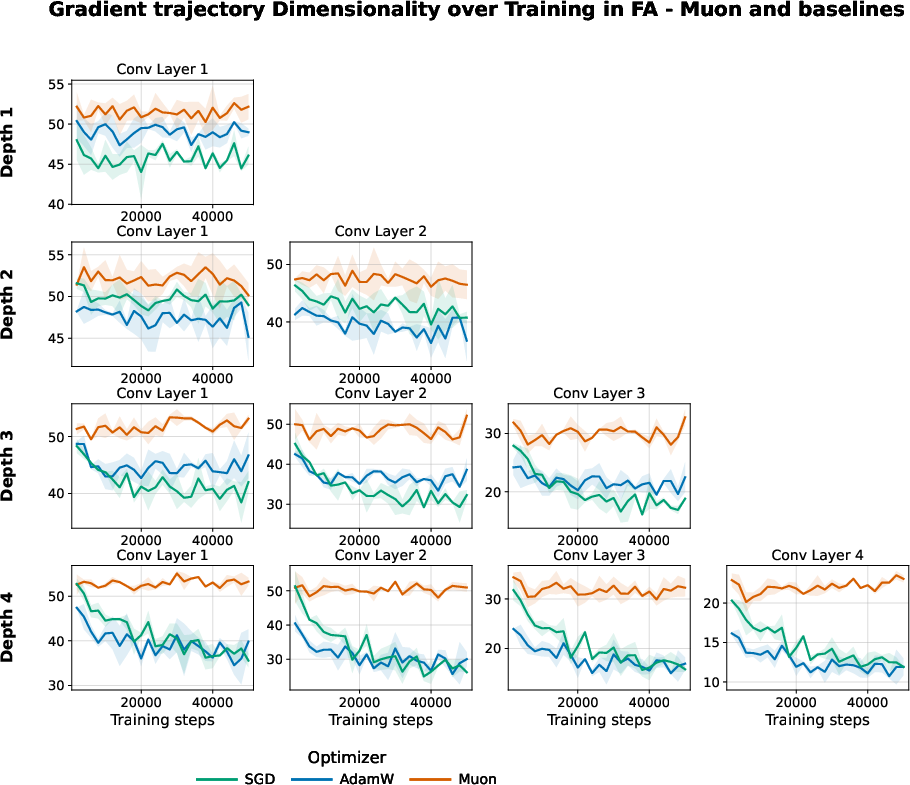
Figure 10: Muon maintains high gradient-trajectory dimensionality through training and depth.
BN has similar effects on both the per-step and trajectory ranks:
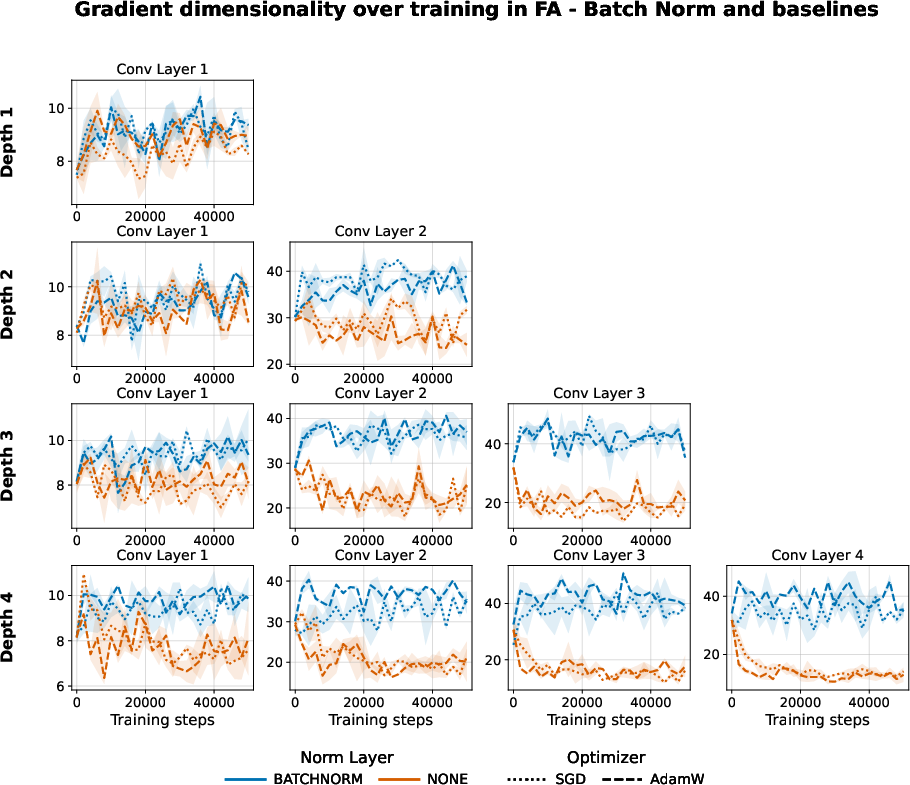
Figure 11: BN increases the effective gradient dimensionality in FA across layers and depths.
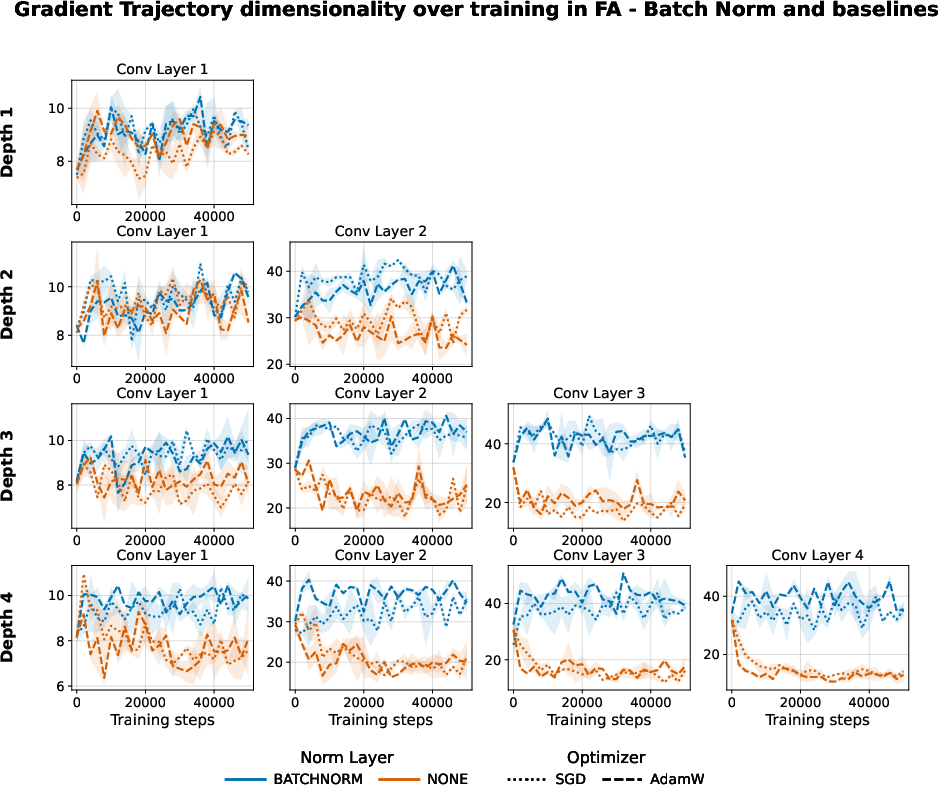
Figure 12: BN elevates the dimensionality of the FA gradient trajectories across layers and depths.
Theoretical and Practical Implications
This work decisively shifts the discourse on FA failure from lack of alignment per se to the geometric constraint imposed by low-rank gradient propagation. The findings have several important implications:
- Optimization theory: Rank collapse of gradients represents a geometrical bottleneck distinct from gradient magnitude or noisy signal, and interventions must preserve alignment with the supervised signal while increasing subspace dimensionality.
- Algorithmic design: Orthogonalisation-based optimizers and representation normalization should be central to future biologically-inspired optimization research. However, the current forms (e.g., SVD-based Muon, global BN) are not directly biologically plausible, motivating development of local, scalable approximations.
- Neuroscience relevance: While the plausibility of exact SVD or global normalization is debated, mechanisms such as divisive normalization and population-based decorrelation are prevalent in cortical circuits and may instantiate similar computational benefits.
Future Directions
Key avenues for future work include:
- Formulating local, neurobiologically-plausible approximations to orthogonalisation and normalization that retain rank-preserving properties.
- Deeper analysis of the interplay between network architecture (e.g., weight sharing, depth, width) and gradient/representation rank in various alignment-based approaches.
- Investigation of structured feedback matrices and their interaction with update geometry in continual, transfer, and curriculum learning.
Conclusion
"Overcoming Rank Collapse in Feedback Alignment" demonstrates that the principal barrier to scaling FA in deep architectures is the collapse of the gradient's effective rank, which constrains the optimization trajectory and hinders effective alignment. Orthogonalization-based optimizers and activity normalization effectively restore high-dimensional updates, substantially improving FA's performance and scalability. These findings reframe the limitations of biologically inspired alternatives to BP and provide a concrete foundation for future advances in both artificial and biological credit assignment paradigms.