- The paper implements convolutional sparse coding by extending the LCA to the convolutional domain on Loihi 2, demonstrating competitive performance in energy efficiency and reconstruction quality.
- It rigorously benchmarks Loihi 2 against a GPU baseline, showing that increases in the sparsity parameter lead to marked energy savings and latency reductions despite slight quality compromises.
- The study offers practical insights into optimizing convolutional parameters and network regimes for neuromorphic hardware, emphasizing energy-dominated workloads over latency-critical ones.
Convolutional Sparse Coding via Locally Competitive Algorithm on Loihi 2: A Technical Analysis
Overview
This work systematically implements and benchmarks convolutional sparse coding with the Locally Competitive Algorithm (LCA) on Intel's Loihi 2 neuromorphic processor, contrasting its performance against a conventional GPU implementation using rigorously matched experimental protocols. Spanning a diverse set of convolutional regimes (stride, filter size, output dimensionality), the study establishes a controlled environment for exploring trade-offs in reconstruction quality, latency, and energy efficiency intrinsic to neuromorphic hardware when executing structured, iterative sparse inference workloads.
Convolutional LCA: Algorithmic and Structural Specifics
The LCA is leveraged as a neural dynamical system whose attractor states yield locally sparse activations subject to reconstruction and sparsity penalties. Extending LCA to the convolutional domain introduces spatial structure, weight sharing, and overlapping receptive fields—challenging both algorithmic realization and hardware mapping. In this setup, the input signal x is represented via convolutional dictionaries Φ and spatially extended coefficient maps a, and the sparse inference energy is
E(x,Φ,a)=∥x−Φ∗Ta∥22+λ∥a∥1,
where λ modulates the activity threshold, thus controlling the sparsity-accuracy trade-off.
The convolutional LCA deployed on Loihi 2 uses a one-layer recurrent architecture. Each neuron holds a fixed-point membrane potential updated via feedforward projection (precomputed convolution with Φ) and localized lateral inhibition, the latter derived via pairwise spatial filter correlations (excluding autocoupling, to ensure self-exclusion in inhibitory interactions). This neuromorphic realization is particularly aligned with the asynchronous, event-driven, and locally connected computational principles foundational to Loihi 2’s design.

Figure 1: Example learned convolutional dictionary trained offline on Set12, utilized as a fixed basis during hardware inference benchmarking.
Experimental Design and Hardware-Specific Mapping
A rigorous protocol is adopted: dictionaries (3×3 and 5×5) are trained offline via alternating optimization on the Set12 image set and then deployed statically during inference. Loihi 2 is evaluated across a spectrum of convolutional strides (s=1,2), image sizes (50×50 to Φ0), and sparsity parameters (Φ1 sweep), with all configurations averaged across five random seeds for statistical robustness.
On Loihi 2, the recurrent LCA network is mapped onto a single chip, with network states quantized and neuron dynamics precisely programmed via microcode. Dynamic power and energy measurements are acquired by subtracting idle baselines, isolating the inference cost attributable to the sparse iterative dynamics.
A GPU baseline is meticulously aligned: identical images, dictionaries, LCA iterations, and seeds are employed. Timing and power are measured synchronously, with warm-up and explicit CUDA synchronization to eliminate measurement artifacts.
Results: Inference Quality-Latency-Energy Trade-offs
Loihi 2 Parameter Sweep: Sparsity Control and Hardware Scaling
Loihi-only results reveal that Φ2 serves as a highly effective control knob: as Φ3 increases, reconstruction quality (e.g., PSNR) decreases gently, while latency and energy consumption decline sharply. These trends are exacerbated in certain stride and filter-size regimes, underlining that hardware efficiency gains are not uniformly tied to code sparsity but are regime-dependent.
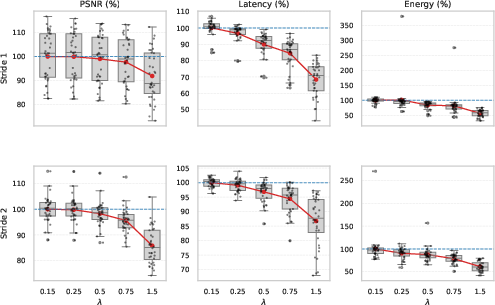
Figure 2: Normalized Loihi-only trends as Φ4 increases for selected stride and filter regimes; latency and energy consistently decrease more than reconstruction quality degrades.
Qualitative assessment illustrates that both platforms reach visually similar reconstructions under many parameter settings, though subtle quality deficits surface in denser (low Φ5) regimes for Loihi 2.

Figure 3: Qualitative comparison between original input, Loihi 2 reconstruction, and GPU reconstruction for a matched configuration.
Quantitative parity plots confirm that Loihi 2’s reconstruction quality is regime-dependent and, in many cases, falls below that of the floating-point GPU baseline, with the separation minimized at higher Φ6. The most salient findings emerge in hardware cost metrics:
- In stride-1 configurations, GPU latency is lower by up to an order of magnitude.
- Loihi 2 delivers a substantial dynamic energy advantage in every matched regime, with per-inference energy costs often an order of magnitude less than those of the GPU.
- Stride-2 configurations reduce the latency advantage of the GPU and further highlight the energy efficiency of Loihi 2.
- The absolute-value analysis corroborates that these performance differences are not merely relative but reflect substantial savings or deficits in practical execution scenarios.
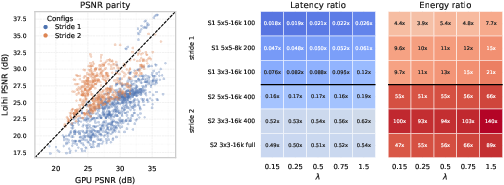
Figure 4: Left: PSNR parity plot, Middle: Wall-clock latency ratio (GPU/Loihi), Right: Dynamic energy ratio (GPU/Loihi) for representative configurations; values above one (for ratios) indicate Loihi 2 advantage.
Implications and Theoretical Context
This study clarifies that convolutional LCA on Loihi 2 is both feasible and performance-sensitive with respect to problem setup. Key implications include:
- Energy-dominated workloads: For applications prioritizing dynamic power minimization (e.g., edge sensing, always-on low-power modules), Loihi 2 is strongly preferable in the sparse-inference regime.
- Latency-dominated workloads: When maximal throughput is essential, conventional GPUs remain superior, especially for small-stride, high-density inference.
- Sparse regime robustness: The Loihi 2 implementation narrows its quality gap with floating-point GPUs as activation patterns become sparser; fixed-point quantization effects are most pronounced for dense, low-threshold codes.
- Experimental protocol generalizability: The rigorous cross-platform protocol provides a template for future benchmarking of neuromorphic systems on structured, iterative inference tasks beyond non-convolutional toy problems.
Theoretically, the work demonstrates that practical deployment of convolutional sparse coding on neuromorphic substrates necessitates careful matching of algorithmic and hardware constraints. The operating regime must be chosen judiciously to exploit the locality, event-driven execution, and architectural strengths of systems like Loihi 2.
Limitations and Future Directions
This study is circumscribed to one-layer recurrent convolutional LCA, with fixed dictionaries, small filter sizes, and offline training. The absence of on-chip learning, larger filters, and end-to-end pipelines renders the benchmark scenario narrow but well-controlled. Future research directions include:
- Extension to deeper or hierarchical sparse codes on neuromorphic hardware.
- Integration of on-chip, online dictionary adaptation methods.
- Joint optimization of latency, energy, and reconstruction via hardware-aware algorithm design.
- Evaluations in tasks where warm-starts or temporal continuity can further amortize inference costs.
- Comparative analysis with class-matched hardware (e.g., edge-grade accelerators) and finer quantization/precision architectures.
Conclusion
The implementation and benchmarking of convolutional LCA on Loihi 2 establish this structured inference task as both achievable and informative for neuromorphic-hardware assessment. While Loihi 2 offers decisive dynamic-energy benefits across all studied regimes, absolute latency and reconstruction quality remain regime- and architecture-dependent. The work positions convolutional sparse coding as a paradigm for structured benchmarking in neuromorphic engineering, providing an evaluation axis where algorithmic structure and hardware constraints can be systematically explored for application-appropriate inference solutions.