- The paper introduces a unified video try-on framework that transfers any wearable object in a single inference pass.
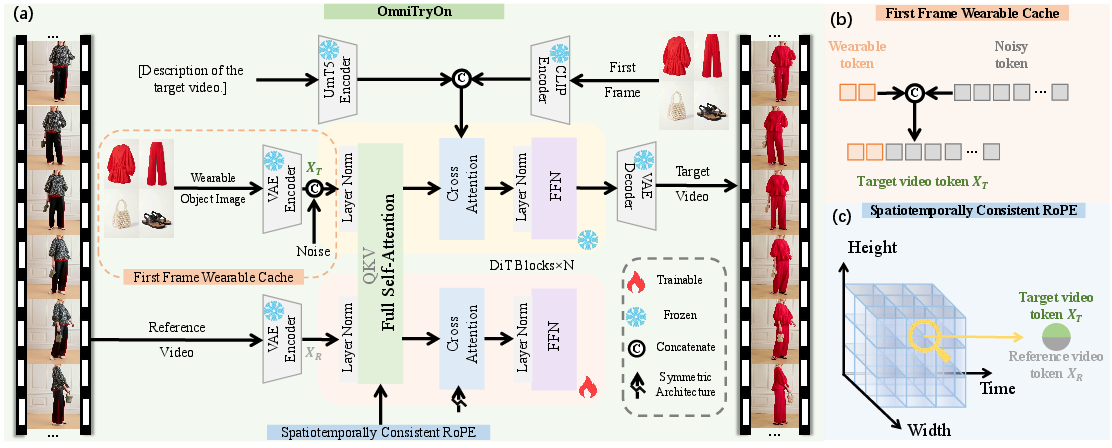
- It employs a Diffusion Transformer backbone with innovations like the First Frame Wearable Cache and STC-RoPE to ensure high temporal consistency.
- The TryAny-Bench benchmark and Gradual Try-On strategy validate state-of-the-art performance in achieving realistic multi-object transfer.
OmniTryOn: A Unified Framework for Video Try-On Anything
OmniTryOn proposes a new direction in video virtual try-on (VVT), advancing beyond prior work by explicitly tackling the simultaneous transfer of arbitrary wearable objects—including garments, handbags, shoes, and facial identities—onto individuals in video sequences, all within a single inference pass. Existing VVT systems are limited in scope: they focus on single-garment transfer and are critically dependent on garment- or body-part-specific priors such as masks or pose estimations, which introduce spatiotemporal artifacts and hinder the transfer of more complex or pluralistic wearables. OmniTryOn redefines the problem as the Try-On Anything task, aiming for scalable, high-fidelity video synthesis across diverse customization targets, prior-free.
TryAny-Bench Benchmark: Dataset and Protocol Innovations
To enable research in this paradigm, TryAny-Bench is introduced as a comprehensive dataset and evaluation suite, specifically designed for the multi-object video try-on challenge. The construction pipeline (Figure 1) leverages over 1,500 e-commerce videos to generate paired reference/target sequences, systematically replacing and perturbing a variety of wearable objects using sequential application of state-of-the-art VVT and editing models. A unique advantage of TryAny-Bench is the elimination of destructive mask-based training pairs, instead providing direct paired samples across a heterogeneous set of wearables.
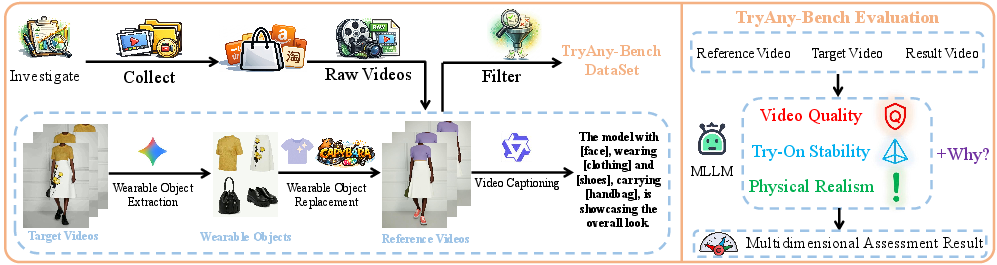
Figure 1: TryAny-Bench data construction automates the extraction and augmentation of diverse wearables, yielding physics-preserving paired videos; the evaluation protocol addresses fine-grained dimensions of video realism and object integrity.
Further, TryAny-Bench establishes a tailored multidimensional evaluation protocol based on specialized Video Question Answering (VQA) for rigorous, aspect-specific quality measurement. This protocol covers Video Quality (visual fidelity, action, background consistency), Try-On Stability (object integrity, material fidelity, scale), and Physical Realism (temporal coherence, anatomical correctness, dynamic plausibility). Such a VQA-driven metric suite exposes model performance beyond superficial similarity metrics, enabling precise diagnosis of artifacts and failures.
OmniTryOn Architecture
The proposed OmniTryOn framework is built upon the Diffusion Transformer (DiT) backbone, integrating several architectural innovations to address the task's demands (Figure 2):
Textual description encodings (via LLM-based captioning) and CLIP embeddings further guide semantics. The architecture thus achieves high-fidelity, consistent synthesis in a unified, prior-free fashion.
Training Regime: Gradual Try-On Strategy
To address the complexity of multi-object transfer (especially for objects with large and deformable spatial support, like garments), the Gradual Try-On (GTO) training strategy is adopted. Training proceeds in two distinct phases:
- Stage 1: Restricted to garment-only try-on, focusing model capacity on non-rigid transformations and detailed attribute transfer.
- Stage 2: Progressive expansion to all wearables (handbags, shoes, faces) for simultaneous multi-object transfer.
Model optimization uses a flow matching-based objective over latent space interpolations between Gaussian noise and the target sequence, conditioned on reference video and object semantics.
Experimental Results
Quantitative Evaluation
OmniTryOn is evaluated on TryAny-Bench against multiple state-of-the-art VVT baselines (MagicTryOn, CatV2TON, ViViD) and general video editing frameworks (VACE, Video-As-Prompt). Across all established metrics (SSIM, LPIPS, VFID-I, VFID-R), OmniTryOn outperforms baselines, notably achieving lower VFID and higher SSIM/LPIPS.
Ablation studies show the criticality of the STC-RoPE; biased variants induce disruptions in mutual perceptual anchoring, leading to degraded consistency and realism. The GTO training strategy further demonstrates superior optimization stability and final performance.
A VQA-based multidimensional radar analysis (Figure 3) confirms that OmniTryOn dominates baselines across all axes, with pronounced gains in object integrity and material fidelity—criteria where prior methods collapse due to either mask-based artifacts or error compounding in sequential inference for multi-garment synthesis.
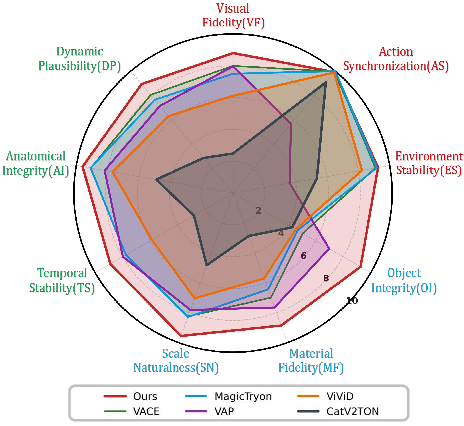
Figure 3: Radar plots of VQA-based evaluation indicate that OmniTryOn outperforms baselines in all pivotal dimensions of try-on synthesis quality.
Qualitative Analysis
OmniTryOn yields visually robust results (Figure 4), generating physically plausible, temporally stable video with multiple wearables. Competing VVT models fail to transfer anything beyond garments and struggle with coherence and color fidelity, often hallucinating undesirable artifacts (e.g., ghosting, unnatural textures, misplaced semantic elements). General video editing systems lack local alignment, with outputs suffering from implausible deformations and background drift.

Figure 4: OmniTryOn delivers higher realism and maintains spatiotemporal consistency compared to specialized VVT and general video baselines.
Theoretical and Practical Implications
OmniTryOn's architectural design demonstrates that joint in-context injection (via the First Frame Wearable Cache) coupled with strict spatiotemporal anchoring (STC-RoPE) is sufficient for multi-object try-on in videos, removing the reliance on brittle, error-prone external priors. This validates that recent advances in DiT-based video models, when properly conditioned, are capable of supporting realistic and controllable video customization tasks beyond the current VVT paradigm. The results suggest a generalizable path for prior-free, simultaneous multi-object control in generative video modeling.
Practically, this framework—together with the TryAny-Bench task standard—enables richer and more immersive video-driven applications, e.g., in e-commerce (allowing real-time, arbitrary visual customization), digital content creation, and mixed reality. Future extensions may focus on scaling object categories, supporting dynamic interactions, and further improving semantic controllability or editability via more expressive conditioning.
Conclusion
OmniTryOn establishes a new state-of-the-art for video try-on by introducing the Try-On Anything task, a robust benchmark, and a high-fidelity, prior-free generative approach. Its architectural innovations—the First Frame Wearable Cache and Spatiotemporally Consistent RoPE—address the intricate technical challenges of multi-object, consistent transfer. The strong empirical results on TryAny-Bench, supported by comprehensive ablations and qualitative evaluations, mark a significant advancement in controllable, scalable video synthesis. This framework will likely serve as a new cornerstone for subsequent research in unified video customization and multi-object editing (2606.08514).