- The paper presents a quantum-native framework that models return distributions as quantum states, bypassing classical sampling limitations.
- It introduces the QuAK algorithm, which efficiently computes statistical moments via quantum operations for improved action selection.
- Empirical results demonstrate up to 94% parameter reduction and higher evaluation rewards across benchmarks, highlighting enhanced adaptability.
Quantum-Native Reinforcement Learning: A Technical Analysis
Introduction and Motivation
Quantum reinforcement learning (QRL) seeks to exploit quantum mechanical advantages for agent-based decision making in stochastic environments. While numerous QRL approaches exist, the vast majority inherit the limitations of classical reinforcement learning (RL)—namely, reducing stochasticity to expectations and modeling random environment variables via function approximation. This neglects critical aspects of the underlying distributions, forfeiting rich information present in variance, higher moments, and quantum-specific correlations. The paper "QnRL: Quantum-Native Reinforcement Learning" (2606.08276) addresses these deficiencies by constructing a fundamentally quantum-native framework (QnRL) which models return distributions as quantum states, manipulates them entirely in Hilbert space, and selects actions based on quantum-derived statistics.
Classical distributional RL (DRL) methods, such as C51, learn conditional return distributions Z(x,a) for state-action pairs and optimize policy with respect to expectations—potentially losing higher-order information and incurring limitations from real-valued architectures. QnRL advances this paradigm by representing return distributions as quantum states, explicitly leveraging quantum superposition and entanglement for distribution preparation and policy construction.
In this approach, the return distribution for each action is encoded as a quantum state in Hilbert space, resulting in an exponentially more compact representation: for ∣Z∣ atoms, only ⌈log2∣Z∣⌉ qubits are needed. All return distributions are superposed in the quantum system (HA⊗HZ), where HA and HZ are action and return Hilbert spaces. This enables parallel manipulation and comparison of distributions using quantum operations inaccessible to purely classical systems.
The QuAK Algorithm for Quantum Amplitude Kickback
A key innovation is the Quantum Amplitude Kickback (QuAK) algorithm, which enables direct, fully quantum, computation and comparison of the nth power of the mth moment of superimposed return distributions without resorting to classical sampling.
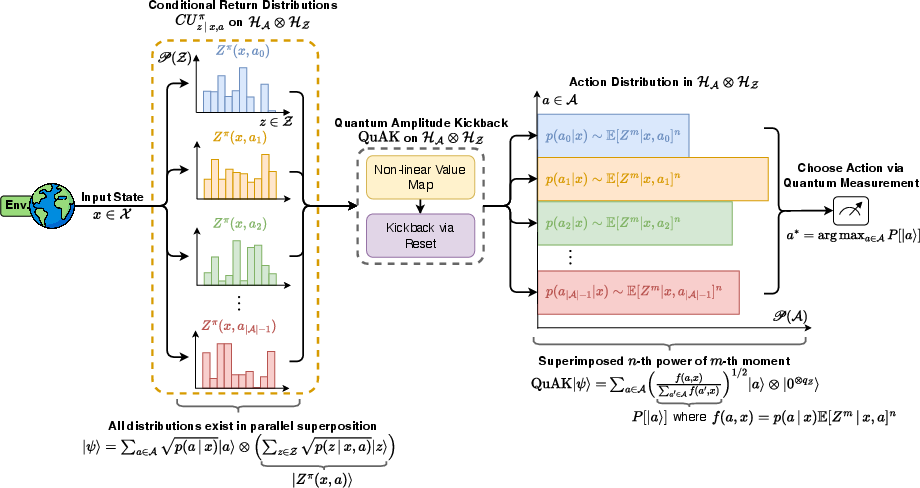
Figure 1: High-level action selection via the QuAK algorithm. Superposed conditional return distributions are mapped through a nonlinear moment map and reset, yielding an action distribution suitable for measurement-based action selection.
QuAK relies on trace non-increasing (Kraus) operators to compute moments, and a quantum reset operation enforces normalization and projection onto the action space. By iterating the moment–reset process, one obtains an action probability distribution proportional to the desired moment power of the return distributions, retaining all amplitude and phase features of the quantum system.
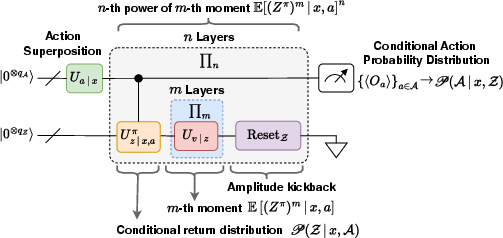
Figure 3: Circuit-level depiction of QuAK. An initial action distribution is seeded (green), conditional superposed return distributions are generated (orange), cascaded nonlinear moment maps via Kraus operators are applied (red), and a reset operation traces over returns, yielding a weighted action distribution.
The outcome is a policy defined in situ by quantum state measurement, where action probabilities are derived directly from quantum-encoded return statistics, requiring no intermediate classical representations.
Quantum Distributional Model Architecture
The QnRL distributional model is specified as a variational quantum circuit (VQC) consisting of classical-to-quantum encoding, entanglement layers, variational rotation layers, and a final quantum Fourier transform (QFT) for distribution shaping.
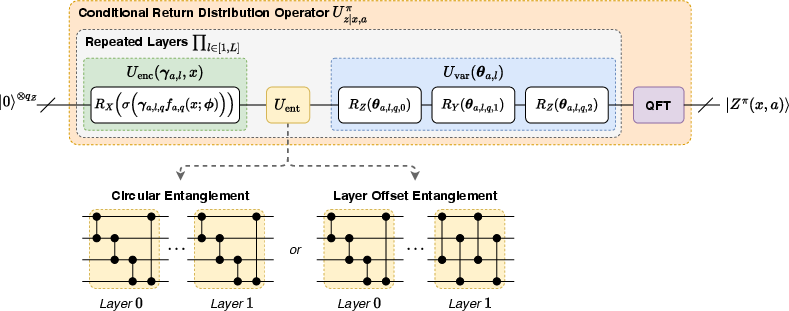
Figure 2: The QnRL VQC architecture. It employs classical feature encoding, entanglement (with both circular/offset variants), repeated variational layers, and a terminal QFT, supporting flexible quantum distribution preparation.
This flexible design supports arbitrary return distributions, is agnostic to prior knowledge of distributional shape, and generalizes across environments (continuous, discrete, and image-based). The QFT module is essential for mapping frequency-domain quantum features back into physically relevant time-domain distributions.
Empirical Results Across RL Benchmarks
Comprehensive empirical studies on classical control (CartPole, Acrobot), grid-world (CliffWalking, FrozenLake), and Atari (Breakout, SpaceInvaders) benchmarks demonstrate QnRL’s performance characteristics.
QnRL consistently achieves parameter efficiency: up to 94.3% fewer parameters than C51, while maintaining or surpassing evaluation performance in most settings.
- CartPole: QnRL attains a 16.8% higher evaluation reward with 94.1% fewer parameters than C51.
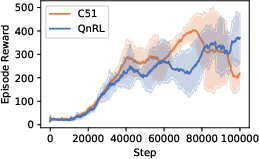
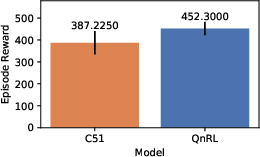
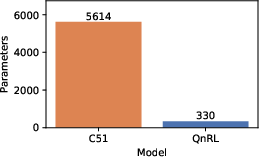
Figure 4: Training and evaluation rewards for CartPole. QnRL achieves higher final evaluation rewards with drastically reduced parameter counts compared to C51.
- FrozenLake: QnRL outperforms C51 by 82.9% higher evaluation scores while being ∣Z∣0 more parameter efficient.
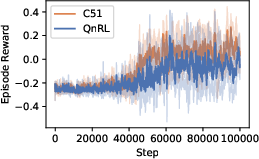
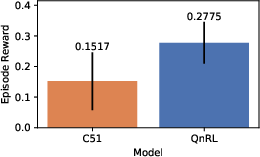
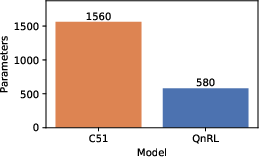
Figure 6: FrozenLake results—QnRL attains superior average and more stable evaluation scores despite a smaller model size.
- Acrobot, SpaceInvaders, Breakout: QnRL yields similar or superior evaluation policy robustness, particularly in adaptation to unseen state distributions and stochastically varying environments, despite a smaller model footprint.
Quantum Policy Adaptivity and Generalization
Notably, QnRL demonstrates enhanced adaptation to changing environment stochasticity, outperforming classical baselines when evaluation conditions deviate from training randomness profiles. This is attributed to the additional expressive capacity of quantum Hilbert space, allowing the quantum policy to encode richer structure beyond mean-return expectations.
Analysis of Learned Quantum Distributions
Direct examination of quantum state density matrices reveals that QnRL models maintain nontrivial phase components—exhibiting complex-valued correlations and entanglement structure that are inaccessible in purely classical or quantum-classical hybrid DRL. This enriches the agent’s capacity to represent and exploit environment correlations, especially in settings where meaningful relationships cannot be captured by real-numbered architectures.
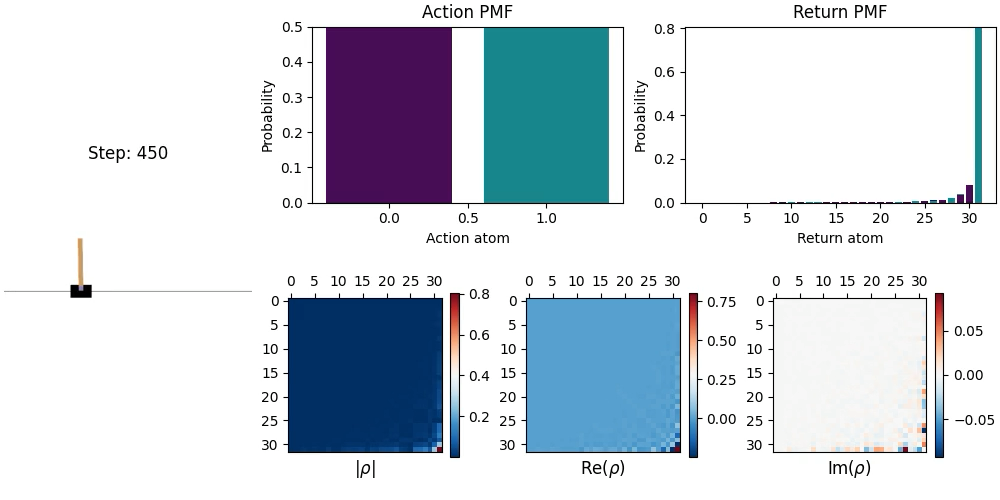
Figure 5: Example learned distributions for CartPole (Left: C51, Right: QnRL). QnRL density matrices display both real and imaginary components, manifesting extra degrees of correlation not available to classical baselines.
Ablation Studies
Comprehensive ablation studies across hyperparameters (circuit depth, moment order ∣Z∣1, power ∣Z∣2, entanglement type) confirm that QnRL’s performance scalability is not solely driven by model size, but by quantum circuit configuration and the ability to tailor statistical comparisons to environment-specific needs (e.g., focusing on variance for environments where spread matters).
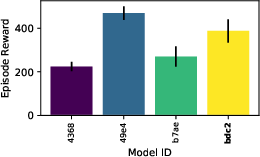
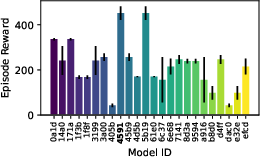
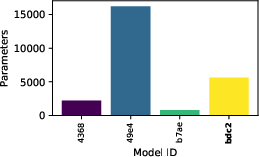
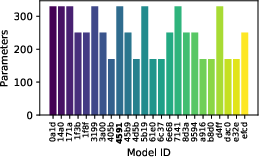
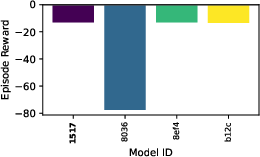
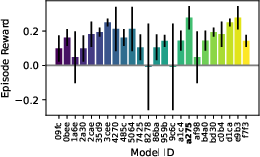
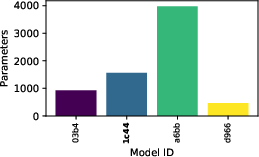
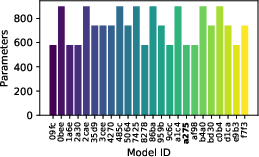
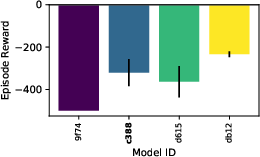
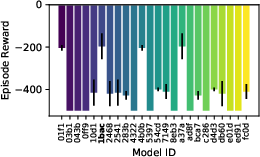
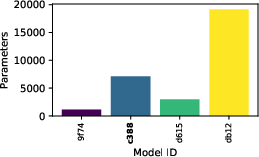
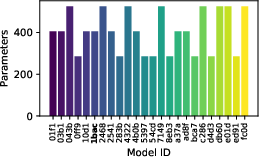
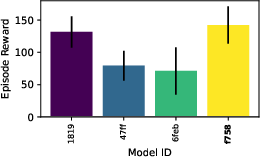
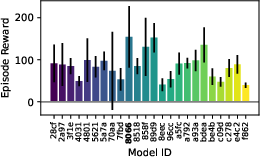
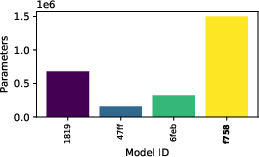
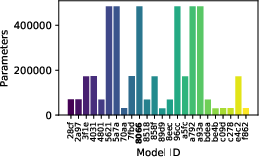
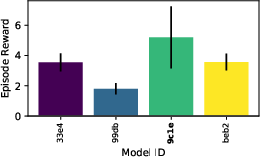
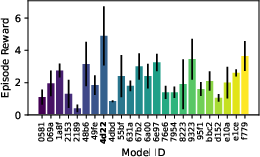
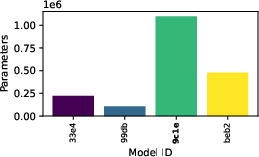
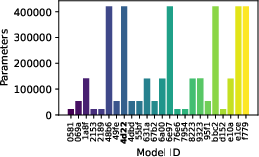
Figure 9: Evaluation rewards and model sizes across various QnRL/C51 configurations. QnRL achieves strong performance not by over-parameterization, but via quantum circuit structure.
Theoretical and Practical Implications
QnRL establishes that full quantum-native manipulation of environment return distributions yields significant representational and computational efficiencies. By directly modeling conditional distributions in quantum states and deriving policies through purely quantum moment computation and measurement, losses associated with classical sampling are eliminated, preserving quantum-specific correlations. Furthermore, QnRL generalizes readily to settings beyond RL wherever moment comparison of parallel distributions is required (e.g., quantum-native statistical tasks).
The practical implications for near-term quantum devices are considerable. QnRL's ∣Z∣3 resource scaling for distribution support, combined with the ability to use generic quantum circuit designs, points towards feasible implementation and scaling advantages as hardware matures. Theoretically, the explicit modeling of distributional Hilbert space correlations opens avenues for policy classes that cannot be represented or efficiently computed classically or classically-sampled-quantumly.
Conclusion
QnRL stands as the first QML framework to natively leverage quantum amplitude and phase for modeling, comparison, and selection of return distributions in RL, with empirical results establishing superiority in adaptation, parameter efficiency, and evaluation reward on a range of benchmarks. The paper's bold claims regarding full quantum-domain moment computation and policy extraction—entirely sidestepping classical sampling—are established both theoretically and empirically, laying groundwork for a new class of quantum-advantaged learning algorithms. Future work will likely focus on scalability, hardware implementation, and generalization to multi-agent, partial-observation, or hierarchical RL settings.