- The paper introduces RLSR, a reinforcement learning-based approach that directly optimizes translation quality improvements via reward-driven source rewriting.
- It employs on-policy RL with DAPO to overcome non-differentiable reward signals, yielding significant gains over prompt-based rewriting in compact models.
- Empirical results show that RLSR generalizes across multiple MT systems and achieves competitive performance with larger, more resource-intensive models.
Reinforcement Learning for Source Rewriting in Machine Translation
The paper "Rewrite to Translate, Translate to Reward: Reinforcement Learning for Source Rewriting in Machine Translation" (2606.08011) addresses the problem of source-side rewriting—modifying the input to a fixed machine translation (MT) system in order to improve translation quality, particularly in scenarios where MT models are black-box and their internals inaccessible. Prior approaches in source rewriting leveraged LLMs with prompt-based instructions (e.g., for simplification or paraphrasing). However, empirical results reveal that prompt-based rewriting with smaller LLMs (e.g., 4B parameters) can degrade translation quality, with the lack of direct reward-driven optimization yielding unreliable and often counterproductive source modifications.
To overcome this, the authors propose RLSR: Reinforcement Learning for Source Rewriting. RLSR explicitly optimizes the rewriting model to maximize translation quality improvements, measured by automatic evaluation metrics applied to downstream translations produced from rewritten source inputs.
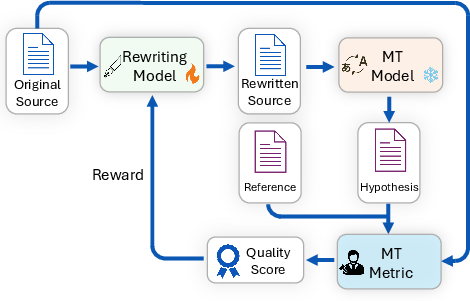
Figure 1: Overview of RLSR. The rewriting model generates a rewritten source from the original source. A fixed downstream MT model translates the rewritten source, and an MT metric evaluates the translation. The improvement over translating the original source is used as the reward for optimizing the rewriting model.
Methodology
RL Objective and Reward Definition
The core of RLSR is the reward structure: for a given source sentence s and reference translation r, the rewriting model Rθ produces a rewritten source s~=Rθ(s). The downstream MT model M outputs translations for both s and s~, evaluated via an automatic metric Q. The reward for each rewrite is defined as
R(s,s~,r)=Q(s,M(s~),r)−Q(s,M(s),r)
thus quantifying the marginal translation quality improvement attributable to rewriting.
Training with DAPO
The reward is non-differentiable due to the discrete generation and metric evaluation, prohibiting direct gradient-based optimization. The authors employ on-policy RL, specifically Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO), to train the rewriting model. To regularize the policy and prevent reward hacking, a KL penalty anchors the policy to a reference (pretrained) LLM using the prompt:
Rtotal(s,s~,r)=R(s,s~,r)−βlogRref(s~∣s)Rθ(s~∣s)
with r0 controlling penalty strength. The objective is to maximize the expected adjusted reward.
Empirical Analysis
Baselines and Setup
Evaluation spans six MT systems and 16 language pairs corresponding to the WMT2025 General MT Shared Task, using Qwen3 4B as the rewriting model. Baselines include no-rewriting, prompt-based rewriting (simplification, paraphrase, "easy translate" prompts), and larger LLM variants (up to Qwen3 235B). Metrics are xCOMET, MetricX, and GEMBA-MQM—the first being a learned metric explicitly optimized in RLSR and the latter providing an independent LLM-based evaluation.
Numerical Results and Claims
The main results highlight several bold findings:
- Prompt-based rewriting with 4B LLMs consistently degrades translation quality across all MT models, confirming that indirect instruction-following is unreliable for compact models.
- RLSR-trained Qwen3 4B models significantly outperform both prompt-based baselines and the no-rewriting baseline at the same model scale, with improvements robust and statistically significant across metrics and MT models.
- RLSR-trained 4B models are competitive with prompt-based approaches using 235B LLMs, demonstrating strong parameter efficiency.
- Evaluation by GEMBA (reference-free) confirms that RLSR improves actual translation quality and does not merely overfit the reward metric.
Comparison to Supervised Fine-Tuning and DPO
Direct supervised fine-tuning (SFT) using best-rewarded rewrites in an offline dataset yields degenerate models predominantly copying the source, failing to produce meaningful rewrites that improve translation quality. Filtering unchanged sources worsens performance due to token-level NLL's failure to isolate crucial edit operations. Direct Preference Optimization (DPO) improves over SFT but is less stable and consistently inferior to RL, failing to match RLSR's on-policy exploration and adaptation.
Cross-MT Model Generalization
The paper demonstrates that an RLSR-trained rewriting model for a particular MT system generalizes extremely well when applied to other MT architectures, requiring only minor or no retraining. Jointly training a rewriting model to optimize a collective reward across multiple MT models yields nearly identical performance to individually optimized models, suggesting that RLSR learns general strategies targeting intrinsic translation obstacles rather than idiosyncratic system preferences.
Behavioral Analysis and Edit Locality
Detailed analysis shows RLSR performs highly-localized edits focused on disfluencies, ambiguities, and non-literal expressions, preserving length and structural fidelity. By contrast, prompt-based baselines enforce wholesale rephrasing, often flattening style or hallucinating content, indicating their lack of precision. Case studies confirm that RLSR intervenes selectively only where translation quality is impeded, otherwise leaving fluent inputs nearly untouched.
Practical and Theoretical Implications
Practically, RLSR offers a scalable method to enhance translation quality via black-box MT systems while avoiding heavy reliance on extremely large LLMs. The framework allows for efficient deployment, needing only a single pass through rewriting and translation models at inference time. Theoretically, this work substantiates RL's superiority for discrete text-editing tasks where reward signals are sparse and impact is highly localized, and it motivates further investigation of reward-driven sampling, credit assignment, and optimization objectives in text generation.
Future Directions
Open questions remain regarding training cost (RLSR is expensive relative to SFT), automated identification of crucial edit tokens for cost-effective supervised objectives, scaling joint optimization to many MT models, and evaluation robustness via human assessment. Research into advanced supervised objectives (e.g., span-weighted token loss) and broader cross-domain adaptation could further strengthen the application of RL for source rewriting in MT.
Conclusion
By directly optimizing for translation quality improvements via reward-driven reinforcement learning, RLSR advances the state of source rewriting, reliably outperforms prompt-based baselines at the same parameter scale, and approaches performance of much larger models. The method demonstrates precise and effective editing policies, robust MT-system generalization, and strong empirical evidence for RL's fitness in text pre-editing tasks. The findings have important implications for the practical enhancement of both commercial and research MT systems, and suggest promising future directions in reward-driven text generation and editing.