Instrumented data for causal scientific machine learning
Abstract: Scientific machine learning is limited less by model size than by the data it is trained on. Observational data records what happened but not why; template synthetic data has a known generating process but only for the simulator's template, not the case a user faces. We argue a third option is now operationally feasible: instrumented data, in which every datum carries the mechanistic model that produced it, an explicit uncertainty over that model, and an executable family of counterfactuals. Verification-and-validation (V&V) instrumented image-to-simulation pipelines are one realisation: a sensor observation becomes a fully specified, solver-backed simulation with explicit, editable parameters and a propagated aleatoric/epistemic uncertainty. The substrate is case-specific, mechanistically supervised, and supports causal interventions through Pearl's do-operator. Near-term consequences for validation, auditing, and surrogate training span computational biology, climate, materials, fluid mechanics, and medical imaging; a longer-term, falsifiable implication concerns foundation models for scientific reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper suggests a new kind of data for scientific machine learning called instrumented data. Instead of just having a picture or a number with a label (like “this is a cat” or “the pressure is 30”), each data point also includes the actual science model that produced that label, the uncertainty around that model, and a way to ask “what if we changed this?” and then rerun the model to see what happens. The goal is to help AI learn not just correlations (“things that happen together”) but causes (“what makes what happen”) in real-world science problems.
The key questions the paper asks
- How can we give machine learning data that explains why something happened, not just what happened?
- Can each real-world case (like a photo of an object, a medical scan, or a satellite picture) be turned into a runnable scientific simulation with clear, editable settings?
- How do we record trust and quality checks so others can verify and validate the result?
- Can this make AI systems better at answering “what if” questions (counterfactuals) in fields like biology, climate, materials, fluids, and medicine?
- What are the risks, limits, and best ways to use this kind of data?
How they approached the problem (in simple terms)
Think of three kinds of data:
- Observational: like taking a photo of a cake—you see the cake, but not the recipe.
- Synthetic: like baking many cakes using one fixed recipe and changing just a few ingredients—you know the recipe, but it’s not the exact cake someone else has at home.
- Instrumented (the paper’s proposal): you take a real cake photo and, using tools, reconstruct a best-guess recipe for that exact cake, including notes on what you’re unsure about. You can then tweak the ingredients (e.g., more sugar, different oven temperature) and re-bake it in a simulator to see what would happen.
In science terms:
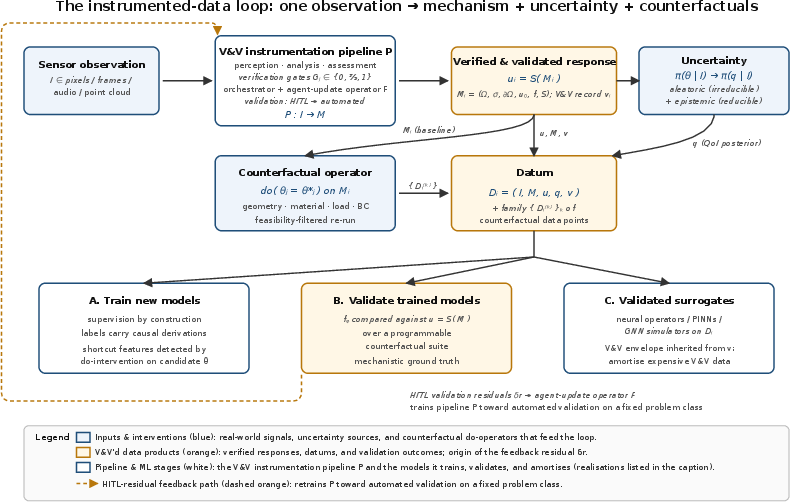
- Start with a real measurement (an image, a scan, a sensor reading).
- Use an “instrumentation pipeline” to extract a case-specific model: geometry (shape), physics laws, starting/boundary conditions, and a solver (the computer program that applies the physics).
- Record uncertainties in two buckets:
- Aleatoric (random noise you can’t remove, like camera noise or natural variability).
- Epistemic (lack of knowledge you could reduce with more information, like uncertain material type or camera angle).
- Keep a verification-and-validation record (V&V):
- Verification: Did we solve the equations correctly?
- Validation: Are these the right equations for this real case?
- Make counterfactuals by changing a parameter (like material, load, temperature, or lighting) and rerunning the solver. This is like turning a knob and seeing the result—often described as using Pearl’s do-operator.
- Include confounders (outside factors like lighting or sensor calibration) explicitly, so they don’t get mistaken for real physical effects.
- For now, a human expert checks results (human-in-the-loop). Over time, the system could learn from these checks to automate parts of validation within a known problem class.
What counts as an “instrumented” data point?
Each datum includes:
- The original observation (e.g., an image).
- The case-specific simulation model and solver settings.
- The confounders (outside influences) that affected the observation.
- The solver’s results (e.g., stress, temperature, flow).
- The quantity of interest (the final number or curve you care about).
- The V&V record (evidence the solution is correct and appropriate).
This makes the data causal for the given case: if you change a model parameter and rerun, you can directly see how and why the outcome changes.
Main findings and why they matter
This is a perspective paper (a proposal and roadmap), but it argues the approach is already feasible and useful:
- Feasibility: A recent demonstration shows a multi-agent system can turn a single photo into a complete simulation with checks in minutes, including geometry, materials, meshing, solving, and a report.
- Clear definition: They precisely define what an instrumented datum is and how to build one, including how to handle uncertainty and counterfactuals.
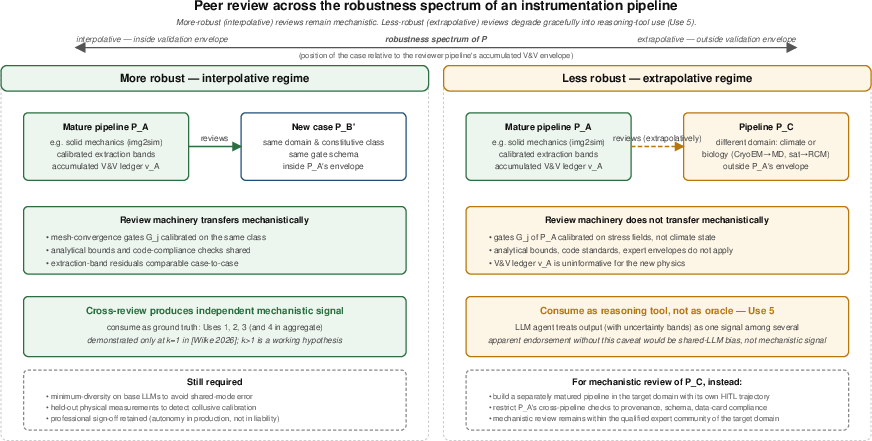
- Robustness spectrum: The approach is strongest when cases are similar to what the pipeline has been validated on (interpolative). It’s less certain when dealing with very different cases (extrapolative), where results should be treated as helpful trends rather than hard truths.
- Five practical uses:
- Training models on causal, auditable labels (no more mystery shortcuts).
- Validating existing models by stress-testing them with counterfactuals.
- Training fast surrogate models (cheap approximations) on high-quality, verified data.
- Long-term, speculative: pretraining “fewer but richer” samples to improve scientific reasoning in foundation models.
- Near-term, robust: using the pipeline as a callable reasoning tool for AI agents to run “what if” tests on demand.
Why this matters: Scientific ML often struggles with “we know what happened, but not why.” Instrumented data puts the “why” into every sample, enabling safer, more reliable AI in high-stakes science and engineering tasks.
Risks and limits to keep in mind
- Uncertainty must be calibrated against real measurements; otherwise, “error bars” may be overconfident or misleading.
- The solver’s accuracy sets a ceiling: tough physics (like fracture or turbulence) can be hard to simulate well.
- Human expert oversight is still needed, especially for safety and responsibility.
- Not every “what if” is physically realistic; feasibility checks are required.
- Anchoring on real observations reduces, but doesn’t erase, the gap to real-world deployment.
- Don’t treat fragile, out-of-domain results as hard truth; in far-out cases, use the system for trend direction and rough size, not exact numbers.
Potential impact across fields
- Biology and medicine: Turn images into patient- or molecule-specific simulations to test treatments or biomarker changes safely in silico.
- Climate and fluids: Generate trustworthy counterfactuals (e.g., changing a forcing or geometry) to probe model behavior under new conditions.
- Materials: Pair lab images with physics-based models to predict properties, then validate and improve ML predictors with grounded counterfactuals.
- Engineering: From a photo of a part, build a simulation to check safety margins and see how changes in material or load would affect performance.
If adopted widely, this could lead to “foundation models for scientific reasoning” trained or assisted by data that includes mechanism, uncertainty, and counterfactuals—bridging the gap between numbers and understanding.
Final takeaway
Most ML learns from data that shows what happened, not why. Instrumented data adds the “why” by shipping each data point with:
- A runnable scientific model for that specific case.
- Clear uncertainty (what we don’t know and why).
- An audit trail (how we checked correctness).
- An easy way to ask “what if?” and get reliable answers.
This makes training, testing, and using AI in science more trustworthy and useful. The community still needs to nail calibration, governance, costs, and benchmarks, but the path is clear: fewer, richer, better-checked data points that help machines—and people—reason about cause and effect.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems the paper leaves unresolved. Each item is phrased to guide actionable research.
- Calibration of extraction uncertainty: how to convert agent self-reported parameter bands into calibrated intervals against physical measurements; sample-complexity requirements per domain and the suitability of conformal prediction variants for heteroscedastic, structured errors.
- Aleatoric vs epistemic decomposition: protocols to separate irreducible sensor noise from reducible model/extraction uncertainty (e.g., repeated acquisitions, multi-view setups, or multi-modal sensing) without impractical data collection burdens.
- Identifiability of mechanistic parameters from single images: conditions under which the extraction operator can uniquely or reliably infer geometry, materials, and boundary/initial conditions; failure modes and detectable signatures of non-identifiability.
- Conditional causality limits: empirical tests for the validity of the “conditional on M” causality claim, quantifying how extraction error degrades counterfactual correctness and trend directions.
- Automated validation (operator F) is unproven: convergence criteria, stability guarantees, and safety constraints for transitioning from HITL sign-off to automated validation; guardrails for catastrophic automation failures.
- Cross-pipeline peer review protocols: minimum diversity requirements for underlying LLMs/tools to avoid shared-mode errors; metrics for agreement/disagreement and adjudication rules; demarcation of what checks can transfer across domains.
- Robustness-spectrum quantification: how to determine whether a case is interpolative vs extrapolative relative to a pipeline’s validation envelope; distance metrics in parameter/physics space and decision thresholds for permitted uses (Uses 1–5).
- Counterfactual realism filters: formal feasibility tests ensuring that interventions produce physically realizable and regulation-compliant scenarios; domain-specific constraints and automatic rejection rules.
- Solver fidelity characterization: standardized methods to expose and bound solver discretization, model-form, and coupling errors within ; criteria for when solver error dominates extraction error and how to flag or exclude such cases.
- Multi-physics and regime gaps: how to handle domains (fracture, plasticity, turbulence, strongly coupled systems) where governing laws are contested or regime-dependent; incorporation of model-form uncertainty into the datum and gates.
- Uncertainty propagation at scale: efficient, validated push-forward of parameter distributions through expensive solvers (sampling vs polynomial chaos vs adjoint/sensitivity methods), with error controls and reproducibility.
- Cost–accuracy trade-offs and break-even points: open benchmarks quantifying when instrumented data plus surrogates amortize computational costs; corpus sizes and regimes where benefits over observational or template synthetic data are realized.
- Surrogate training coverage guarantees: methods to ensure trained surrogates inherit the validation envelope, uncertainty structure, and counterfactual consistency of the instrumented corpus; detection of surrogate extrapolation beyond validated regimes.
- Benchmarking world-model validation: standardized suites where learned models are stress-tested against instrumented counterfactuals; fair comparison protocols and alignment of inputs/outputs to avoid selection bias.
- “Fewer-but-richer” postulate measurement: rigorous estimation of the informational-density ratio across tasks (causal reasoning, counterfactual VQA/NLI, scientific QA), matched-compute protocols, and sensitivity to instrumentation depth and domain.
- Tool-use evaluation in less-robust regimes: benchmarks and metrics for LLM agents that call instrumented tools, with scoring for qualitative correctness (sign, monotonicity, order-of-magnitude) and calibrated uncertainty weighting.
- Provenance and licensing standardization: a machine-readable data card schema that carries solver versions, gate outcomes, reviewer identities, licenses, and sensor lineage, aligned with Datasheets for Datasets and accommodating code/data IP constraints.
- Privacy and compliance for patient-specific or proprietary cases: de-identification standards, consent models, and technical means (e.g., federated storage or secure enclaves) to share instrumented data without violating regulations.
- Packaging and long-term executability: robust practices for shipping solvers with data (containers, dependency pinning, hardware determinism), mitigating software rot, and ensuring future re-runs of remain valid.
- Schema generality beyond img2sim: evidence and standards for extending the datum definition (I, M, η, u, q, v) to time-series, multi-sensor, and non-vision workflows; APIs for ODE- and PDE-based pipelines across disciplines.
- Confounder enumeration completeness: methods to discover and include missing confounders ; impact assessment of omitted variables on label bias and counterfactual validity; update procedures for the confounder schema.
- Intervention policy design: principled selection of counterfactuals (design of experiments) that maximize coverage in -space weighted by causal relevance to ; stopping rules and diversity criteria.
- Detection and defense against adversarial failures: susceptibility of LLM-driven gates and extraction to prompt-based attacks, data poisoning, or solver misuse; red-teaming protocols and robust training for gates and orchestrators.
- Governance and liability: assignment of responsibility when validation is automated; documentation and auditing practices that regulators and standards bodies (e.g., ASME V&V) will accept; pathways for certification.
- Energy and environmental footprint: accounting and benchmarks for the compute/energy cost of instrumented corpora vs alternatives; strategies (e.g., multi-fidelity sampling, active learning) to minimize footprint while preserving coverage.
- Domain-boundary failures: characterization of tasks where mechanistic instrumentation is ill-suited (e.g., commonsense, sociotechnical factors) and guidelines to avoid misuse as ground truth in such settings.
- Real-time and deployment constraints: latency-aware strategies (e.g., validated surrogates, anytime inference) for Use 5 tool calls; policies for fallback when solver deadlines cannot be met.
- Reproducibility of V&V gates: open repositories of gate definitions, analytical bounds, and test cases with expected outcomes; inter-lab reproducibility studies across different LLM bases and solver stacks.
- Data-sharing incentives and ecosystems: mechanisms (licensing, credit, marketplaces) that motivate labs to publish instrumented data with full and solver assets, given IP and cost barriers.
Practical Applications
Immediate Applications
Below are deployable applications that can be piloted or adopted now, leveraging existing V&V instrumented pipelines (e.g., image-to-simulation) and human-in-the-loop validation.
Industry
- Manufacturing and infrastructure inspection
- Sectors: manufacturing, civil engineering, construction, utilities
- What: Phone/photo-to-simulation QA of parts and field assets (e.g., brackets, anchors, joints). Generate code-compliant, V&V-backed stress/deflection reports with editable parameters and uncertainty bands. Use counterfactuals to test “what if the load doubles?” or “what if the material changes?”
- Tools/products/workflows: img2sim Copilot (LLM-orchestrated CAD/mesh/FEA), automated gate checks (mesh convergence, bounds), CMMS integration for audit trails
- Assumptions/dependencies: Verified solvers for the constitutive class, expert sign-off for validation, calibrated extraction uncertainty (or conservative bands), photos with adequate metadata (confounders η captured: viewpoint, illumination, calibration)
- Rapid aerodynamic/thermofluid screening
- Sectors: aerospace, automotive, HVAC, energy
- What: Use PIV→LES or reduced-order surrogates to do trend-accurate “what if” studies (e.g., grill geometry changes, fan RPM, duct modifications) with executable counterfactuals and V&V records
- Tools/products/workflows: Graph-network simulators, neural operators as amortized surrogates trained on instrumented corpora; CAD plug-ins for rapid studies
- Assumptions/dependencies: Regime awareness (interpolative vs extrapolative), solver fidelity disclosures in the V&V record, HITL review for nontrivial turbulence/contact regimes
- Materials R&D triage and audit
- Sectors: materials, chemicals, semiconductors
- What: Validate ML property predictors by probing with instrumented counterfactual suites; filter false positives before synthesis or expensive DFT runs
- Tools/products/workflows: Counterfactual Audit Suite (do-operator sweeps over composition/microstructure), M-DCARD (mechanistic data cards) logging provenance and V&V
- Assumptions/dependencies: Availability of DFT/CPFE workflows with documented error envelopes; feasibility filters for counterfactual realism
- Medical imaging decision support (trend-level)
- Sectors: healthcare (radiology, cardiology, surgery)
- What: Use radiology→patient-specific FE models as callable tools for qualitative risk direction and order-of-magnitude checks (e.g., aneurysm wall stress trends if BP increases)
- Tools/products/workflows: On-demand mechanistic tool invoked by clinical AI assistants; uncertainty bands surfaced to clinicians; HITL sign-off
- Assumptions/dependencies: Clear labeling of robustness regime, retained clinician oversight, alignment with existing clinical V&V standards and liability frameworks
- Model validation and ML assurance in production
- Sectors: software, MLOps, finance/insurance (risk models with physical inputs), climate-tech
- What: Validate already-trained models against solver-computed counterfactuals to detect shortcut features and quantify failure modes
- Tools/products/workflows: Instrumented Validation Harness integrated in CI/CD; regression tests over mechanistic counterfactual suites; model risk dashboards
- Assumptions/dependencies: Access to relevant instrumented corpora for the target domain; governance to prevent over-reliance in extrapolative regimes
Academia
- Causal, mechanistic datasets for teaching and research
- What: Course labs and benchmarks where each sample ships with its mechanistic model, uncertainty decomposition, and counterfactual family; teach causal inference and scientific ML with auditable labels
- Tools/products/workflows: Open instrumented corpora, conformal-calibrated extraction bands, V&V checklists and gates for students
- Assumptions/dependencies: Public release of pipelines/data cards; clear licensing on solvers and derived data
- Training validated surrogates (pay-once, use-often)
- What: Train neural operators/graph simulators on V&V-instrumented datasets to amortize cost and enable fast inference in downstream projects
- Tools/products/workflows: Shared academic compute queues with quota policies tuned to instrumented data cost; repository templates for v_i (V&V) records
- Assumptions/dependencies: Sufficient coverage in θ-space; documentation of training distribution and validation envelope
Policy and governance
- Auditable AI for safety-critical approvals
- Sectors: building codes, medical devices, infrastructure permitting, climate services
- What: Require V&V records per datum/model for regulatory submissions; use mechanistic counterfactual audits to assess model robustness
- Tools/products/workflows: Standardized mechanistic data cards (provenance, gates, reviewers), cross-pipeline review checklists, regulatory sandboxes using instrumented oracles
- Assumptions/dependencies: Agency capacity to read V&V; minimum-diversity requirements for LLM-based gates; held-out physical measurements for spot checks
- Climate/model assurance for public services
- Sectors: municipalities, utilities
- What: Validate learned weather or flood emulators against instrumented counterfactual suites; communicate uncertainty bands and causal drivers to stakeholders
- Tools/products/workflows: Satellite→RCM instrumented datasets; policy dashboards that visualize do-operator interventions (e.g., land-use changes)
- Assumptions/dependencies: Transparent disclosure of reanalysis assumptions; careful treatment of extrapolative forcings
Daily life and field practice
- Technician assistants with trend-level physics
- Sectors: field service, maker/hobbyist communities
- What: Mobile apps that convert a photo plus context into a quick, trend-accurate simulation (direction/sign of effect) to guide safe repairs/mods
- Tools/products/workflows: On-device reduced-order solvers or cloud-backed surrogates; QR-based capture of confounders (η) like part number and material
- Assumptions/dependencies: Clear “qualitative only” disclaimers; feasibility filters (no physically impossible counterfactuals); limits-of-use within the app UI
Long-Term Applications
These require further research, calibration at scale, automation of validation, broader coverage, or standardization.
Industry
- Autonomous validation and cross-pipeline peer review
- Sectors: all safety-critical engineering domains
- What: Migrate from HITL to semi-/fully-automated validation via an update operator trained on expert residuals; enable mature pipelines to peer-review sibling pipelines through typed gates
- Tools/products/workflows: Gate libraries with adversarial probes, diversity across base LLMs, peer federation governance
- Assumptions/dependencies: Demonstrated calibration and non-collusion; robust extrapolation guardrails; retained professional liability conventions
- Closed-loop discovery with mechanistic active learning
- Sectors: materials, biotech/pharma
- What: Couple instrumented DFT/CPFE or CryoEM→MD data with robotic labs; active learners choose counterfactuals to reduce epistemic uncertainty and drive synthesis
- Tools/products/workflows: Lab orchestration platforms that consume v_i and η, experimental feasibility filters, uncertainty-aware design-of-experiments
- Assumptions/dependencies: High-fidelity solvers for target regimes; alignment between simulated and experimental conditions; IP/licensing clarity for derived datasets
- Fleet- and city-scale digital twins with executable counterfactuals
- Sectors: transportation, energy grids, smart cities, insurance
- What: Maintain instrumented twins where each asset/environmental observation anchors a mechanistic model; run scenario analyses for maintenance and risk pricing
- Tools/products/workflows: Streaming assimilation of observations into case-specific models; pricing/maintenance policies tied to do-operator analyses
- Assumptions/dependencies: Data infrastructure for provenance; solver scalability; governance to prevent misuse of magnitude-uncertain outputs
- Robotics and control with grounded world models
- Sectors: robotics, industrial automation
- What: Use surrogates trained on instrumented data as controllers’ internal models for planning and safety envelopes
- Tools/products/workflows: Real-time neural operators; online uncertainty monitoring; fallback logic when outside validation envelope
- Assumptions/dependencies: Tight latency and reliability constraints; certification paths for model-based control
Academia
- Foundation models for scientific reasoning pretraining on “fewer-but-richer” corpora
- What: Pretrain on mechanistic, counterfactual, uncertainty-aware samples to improve causal reasoning and calibration at fixed compute
- Tools/products/workflows: Benchmarks (e.g., CLadder-type) and measurement protocols to estimate informational-density ratio ρ; process-level rewards from structural equations
- Assumptions/dependencies: Empirical verification that ρ>1 on target tasks; dominance of interpolative samples to avoid baking in extrapolation error
- Standards, benchmarks, and governance for instrumented datasets
- What: Community standards for mechanistic data cards, counterfactual coverage metrics, cost–accuracy frontiers, and tool-use evaluation in less-robust regimes
- Tools/products/workflows: Open benchmark suites pairing instrumented corpora with surrogates and tool-using agents; conformal calibration protocols for extraction bands
- Assumptions/dependencies: Broad community participation; accessible solvers; sustainable funding for shared infrastructure
Policy and governance
- Regulatory adoption of instrumented-data standards
- Sectors: healthcare, transportation, construction, climate policy
- What: Codify requirements for mechanistic provenance, executable counterfactuals, and V&V records in approvals and audits; establish minimum-diversity LLM requirements in automated gates
- Tools/products/workflows: Procurement specs, compliance checklists, audit APIs that read v_i and η fields
- Assumptions/dependencies: Workforce upskilling for regulators; testbeds with held-out physical measurements; clear liability lines (“autonomy in production is not autonomy in liability”)
- Scenario planning and intervention design with causally grounded models
- Sectors: urban planning, public health, disaster risk
- What: Use satellite→RCM and domain-specific instrumented pipelines to evaluate policy interventions (e.g., zoning, mitigation measures) with do-operator scenarios
- Tools/products/workflows: Policy simulators with calibrated uncertainty decomposition; citizen-facing transparency dashboards
- Assumptions/dependencies: Reliable solver chains under shifting forcings; cross-agency data-sharing agreements; careful communication of uncertainty
Daily life and education
- AR/VR science tutors and “instrumented labs” at home and school
- Sectors: education, lifelong learning
- What: Interactive lessons where students change physical parameters and see executable counterfactuals; grading based on causal explanations aligned to structural equations
- Tools/products/workflows: Lightweight ODE/PDE surrogates on devices; teacher dashboards with v_i summaries; lesson plans tied to counterfactual sets
- Assumptions/dependencies: Age-appropriate safety filters; equitable access to compute; curated, validated content libraries
- Consumer safety advisors with mechanistic checks
- Sectors: DIY, maker ecosystems, prosumer engineering
- What: On-device assistants that provide conservative, mechanistically justified guidance for small projects (e.g., load-bearing shelves)
- Tools/products/workflows: Library of validated cases; strong feasibility filters; clear “not a substitute for professional advice” framing
- Assumptions/dependencies: Robust handling of confounders (materials, fasteners); careful scope limitation to avoid unsafe extrapolation
Cross-cutting assumptions and dependencies (impacting feasibility)
- Solver fidelity and V&V coverage: Performance is bounded by solver accuracy in the operative regime (e.g., plasticity, fracture, turbulence). Each datum must carry v_i to surface limits.
- Robustness regime awareness: Treat interpolative cases as quantitative ground truth; treat extrapolative cases as qualitative tools (trend/order-of-magnitude). Misuse is the main deployment risk.
- Human-in-the-loop oversight: Professional sign-off remains essential in safety-critical contexts; automation of validation requires evidence against shared-mode and collusive failures.
- Calibration and uncertainty: Extraction bands are self-reports until calibrated against physical measurements; conformal prediction and held-out tests are needed.
- Counterfactual realism: Not all interventions are physically realizable; enforce feasibility filters and document assumptions in η.
- Data governance and licensing: Standardized mechanistic data cards (provenance, solver licenses, reviewer identity, gates) must accompany datasets; clear IP for derived data.
- Compute and cost: Instrumented samples are costlier than scraped data; amortize via surrogates and prioritize tasks where counterfactual coverage is most valuable.
- Diversity of LLMs/gates: Cross-pipeline reviews require diversity across base models and adversarial probing to avoid correlated errors.
Glossary
- Aleatoric uncertainty: Irreducible randomness arising from inherent variability (e.g., sensor noise or material variability). "Aleatoric uncertainty is irreducible (sensor noise, material variability); epistemic uncertainty is reducible by more information (viewpoint ambiguity, model-form uncertainty)."
- Boundary conditions: Constraints specified on the boundaries of the domain in a mathematical or computational model. "geometry , governing law , boundary conditions , initial conditions , forcing , and solver "
- Causal graph: A directed graph that encodes causal relationships among variables in a system. "Unlike a labelled image, exposes the causal graph, the confounders, and the record by which both V{paper_content}V questions were answered."
- Conformal prediction: A framework for constructing prediction sets with guaranteed coverage under minimal assumptions. "Conformal prediction~\cite{Vovk2005, AngelopoulosBates2023} over extraction--measurement residuals is a natural candidate."
- Confounders: Variables that influence both the observed data and outcomes but lie outside the mechanistic model, potentially biasing inference. "and the confounders carried explicitly outside "
- Constitutive class: A category grouping materials or systems by their stress–strain behavior or governing material laws. "shared constitutive class, gate schema, review history"
- Constitutive law: A material-specific relation (e.g., stress–strain) used in continuum mechanics to close governing equations. "microstructureCPFE workflow on DFT constitutive laws"
- Counterfactual: A hypothetical scenario constructed by intervening on model parameters to ask “what if” questions. "an executable family of counterfactuals."
- CryoEM→MD: A workflow linking cryo-electron microscopy data to molecular dynamics simulations for structural biology. "cryogenic-electron-microscopy-to-molecular-dynamics (CryoEMMD) workflow"
- Crystal-plasticity finite element (CPFE): A finite-element approach incorporating crystal plasticity to model deformation at the grain/crystal scale. "microstructure-to-crystal-plasticity-finite-element (microstructureCPFE) / DFT workflow"
- Density-functional theory (DFT): A quantum mechanical method for computing electronic structure and material properties. "graph-network predictors trained on density-functional-theory (DFT) corpora"
- do-operator: Pearl’s formal intervention operator that sets a variable to a specified value to assess causal effects. "supports causal interventions through Pearl's -operator."
- Epistemic uncertainty: Uncertainty due to lack of knowledge, reducible with additional information or better models. "epistemic uncertainty is reducible by more information (viewpoint ambiguity, model-form uncertainty)."
- Extrapolative regime: The regime where a case lies outside the validated operating envelope of a pipeline, reducing robustness. "inside its validation envelope (interpolative regime), \emph{less robust} when they sit outside (extrapolative regime)."
- Finite element (FE): A numerical method (and modeling framework) for solving boundary value problems by discretizing the domain into elements. "radiology-to-patient-specific finite-element (FE) workflow"
- Forcing: External inputs or drives applied to a system’s governing equations. "geometry , governing law , boundary conditions , initial conditions , forcing , and solver "
- Governing law: The constitutive or physical law (e.g., PDE form, material law) defining the system’s behavior. "geometry , governing law , boundary conditions , initial conditions , forcing , and solver "
- Graph network simulators: Neural simulators based on graph neural networks that learn to approximate physical dynamics. "graph network simulators~\cite{SanchezGonzalez2020, PfaffMeshGraphNets2021}"
- Human-in-the-loop (HITL): A process where human experts oversee, validate, or steer automated systems. "validation is supplied by a human-in-the-loop (HITL)"
- Image-to-simulation (img2sim): A pipeline that converts sensor images into runnable mechanistic simulations. "Image-to-simulation (img2sim) refers to a pipeline that converts a sensor observation into a runnable mechanistic simulation;"
- Interpolative regime: The regime where a case lies within the validated operating envelope of a pipeline, yielding higher robustness. "inside its validation envelope (interpolative regime), \emph{less robust} when they sit outside (extrapolative regime)."
- Large-eddy simulation (LES): A turbulence modeling approach that resolves large eddies while modeling smaller scales. "particle-image-velocimetry-to-large-eddy-simulation (PIVLES) workflow"
- Mesh convergence: A verification check assessing solution stability as the computational mesh is refined. " carries verification artefacts (mesh convergence, residuals against analytical bounds, gate outcomes, domain-standard flags)"
- Multiphysics: Coupled simulations involving multiple interacting physical processes (e.g., fluid–structure interaction). "(PDE, ODE, multiphysics, or reduced-order)"
- Neural operators: Models that learn mappings between function spaces to solve families of PDEs efficiently. "neural operators~\cite{Li2021, Kovachki2023}"
- Ordinary differential equation (ODE): A differential equation involving functions of a single variable and their derivatives. "ordinary-differential-equation (ODE) integrator"
- Partial differential equation (PDE): A differential equation involving multivariable functions and their partial derivatives. "partial-differential-equation (PDE) discretiser"
- Particle image velocimetry (PIV): An experimental technique to measure flow velocities by tracking particle motion in images. "particle-image-velocimetry-to-large-eddy-simulation (PIVLES)"
- Physics-informed networks: Neural networks trained with physics-based constraints or residuals of governing equations. "physics-informed networks~\cite{Raissi2019}"
- Push-forward: The distribution of an output quantity obtained by propagating uncertainty through a model or solver. "yields a push-forward over the quantity of interest"
- Quantity of interest (QoI): A specific output metric derived from simulations that the analysis focuses on. " the quantity of interest (stress, drag, temperature, modal frequency, biomarker concentration, etc.)"
- Reanalysis: A meteorological dataset produced by assimilating observations into a consistent numerical model over time. "learned-weather emulator pipelines on reanalysis-plus-simulation corpora"
- Reduced-order surrogate: A low-dimensional, computationally cheaper approximation of a high-fidelity model or solver. "ordinary-differential-equation (ODE) integrator or reduced-order surrogate; the substrate definition does not privilege either."
- Reynolds number: A dimensionless quantity indicating the ratio of inertial to viscous forces in fluid flow, governing regimes. "learned fluid surrogates trained on fixed Reynolds-number ranges break out of regime"
- Structural causal model: A formal model defined by structural equations specifying how variables cause one another. " is a known structural causal model in the sense of Pearl"
- Surrogate (model): A learned, cheaper approximation of an expensive simulator used to accelerate predictions. "A surrogate is a cheap neural approximation to an expensive solver; amortised surrogate training pays the simulation cost once so inference is fast."
- Validation envelope: The region of problem instances for which a pipeline has been validated and is deemed reliable. "inside its validation envelope (interpolative regime)"
- Verification and validation (V{paper_content}V): Verification checks numerical correctness; validation checks physical correctness for the case. "Verification-and-validation (V{paper_content}V) instrumented image-to-simulation pipelines are one realisation:"
- World models: Generative or predictive models that learn an environment’s dynamics for planning or reasoning. "The world-models programme~\cite{HaSchmidhuber2018, LeCun2022, Hafner2023} pursues a related generative stance"
Collections
Sign up for free to add this paper to one or more collections.

