- The paper introduces a stochastic interpolation framework that unifies traditional shrinkage with novel eigenbasis regularization.
- It employs parametric flows, including neural ODEs, to optimize high-dimensional covariance estimation under severe data constraints.
- Empirical tests on synthetic and fMRI data demonstrate that the SI estimator achieves lower statistical risk than classical methods.
Introduction
The estimation of high-dimensional covariance matrices from limited data is a canonical problem in statistics and machine learning, complicated by the ill-conditioning and high variance of the empirical sample covariance Σ^ in regime D∼N. Classical shrinkage estimators—most notably those due to Ledoit and Wolf—operate by convexly combining Σ^ with an isotropic anchor, enforcing rotational invariance and acting solely on the spectrum. While non-linear refinements can further modulate the spectrum, the eigenbasis of the empirical covariance remains fixed. This invariance fundamentally limits the recoverability of signals not aligned with the empirical eigenspace, particularly under severe data constraints.
"Covariance Shrinkage via Stochastic Interpolation" (2606.07382) introduces a paradigm shift: classical shrinkage is subsumed under a continuous-time, parametric, stochastic flow between anchor and empirical distributions, unifying known estimators and exposing new axes of risk control. The stochastic interpolation (SI) framework admits non-linear couplings—including those parametrized by neural ODEs—which unlock regularization in the eigenbasis itself, transcending the constraints of traditional approaches.
Stochastic Interpolation Framework
The SI approach parameterizes estimators via stochastic interpolants Iθ=αX0+βX, where X0 is drawn from an anchor (typically isotropic) distribution μ0, X from the empirical measure μ^, and (α,β)∈[0,1]2 is the interpolation schedule. The resulting estimator Σθ=E[IθIθ⊤] defines a two-parameter surface of admissible covariances, with the classical Ledoit–Wolf estimator recovered as a special case along a particular trace-preserving path.
Crucially, the stochastic coupling D∼N0 between D∼N1 and D∼N2 becomes a vehicle for risk reduction. Independent couplings lead to structurally rotationally invariant estimators; in contrast, couplings induced by flow maps (e.g., learned via neural ODEs) enable the interpolant to escape the empirical eigenspace, providing regularization both in the spectrum and in the eigenbasis.
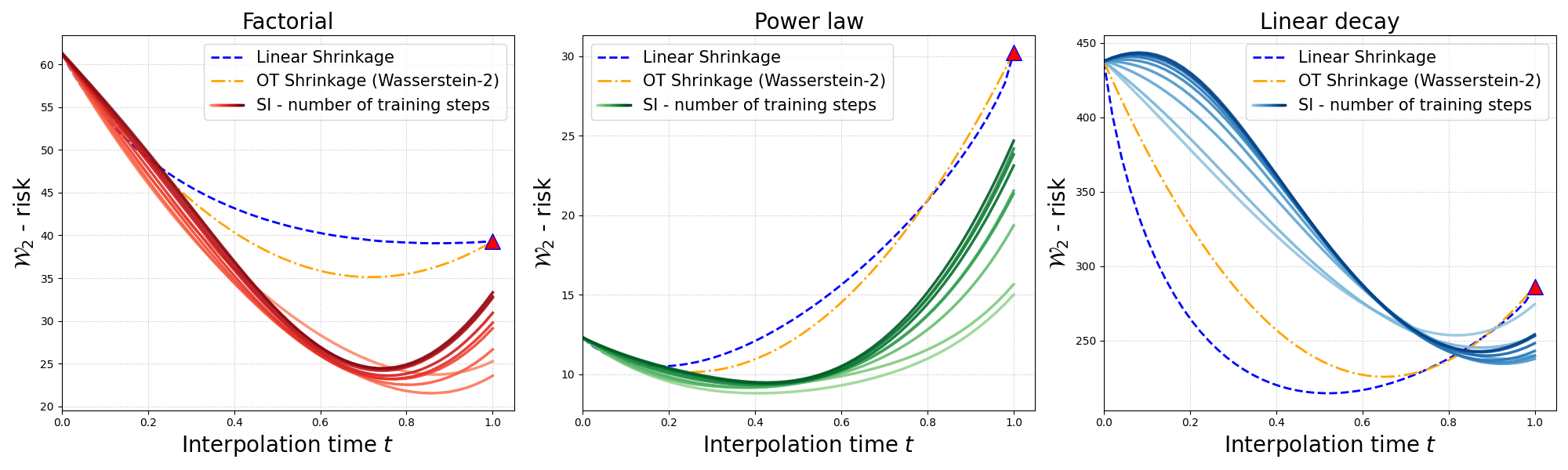
Figure 1: Risk profiles under the Bures-Wasserstein distance of several interpolant constructions for three different Gaussian distributions. The SI estimator can significantly reduce risk relative to empirical and classical shrinkage.
Regularization Axes: Schedule, Coupling, and Early Stopping
The SI construction exposes three principal regularization axes:
- Interpolant Schedule: The location D∼N3 defines a surface of achievable covariances; the empirically minimal risk typically lies in the interior, away from both the empirical and anchor endpoints and outside classical shrinkage paths.
- Coupling Structure: Optimally coupled interpolants (e.g., via the Monge map in OT) lower risk compared to independent couplings but retain rotational invariance. Deterministic flow-based couplings—especially those parameterized by neural networks—lift this invariance, leading to eigenvector regularization.
- Training Budget (Early Stopping): For neural flow-based models, continued training drives the estimated distribution towards the empirical; early stopping halts at intermediate points, providing bias-variance trade-off calibrated by out-of-sample risk or Stein-corrected surrogates.
The theoretical analysis introduces a data-driven Stein Unbiased Risk Estimate (SURE) for optimal integration time selection, generalizing Stein–Haff identities beyond rotational invariance. This enables rigorous, observable calibration of the early-stopping criterion in regimes of high dimensionality and data scarcity.
Numerical Validation: Synthetic and Real Data
Synthetic Covariance Estimation
Empirical results on synthetic Gaussian benchmarks demonstrate that the SI framework yields lower statistical risk—with both Bures–Wasserstein and Frobenius metrics—for a range of covariance structures, including factorial (spiked), power law, and linearly decaying spectra. The neural SI estimator achieves minimal risk at interior interpolation points and is robust to the presence of sparse noise, with the risk rising only when overtraining induces overfitting (Figure 1).
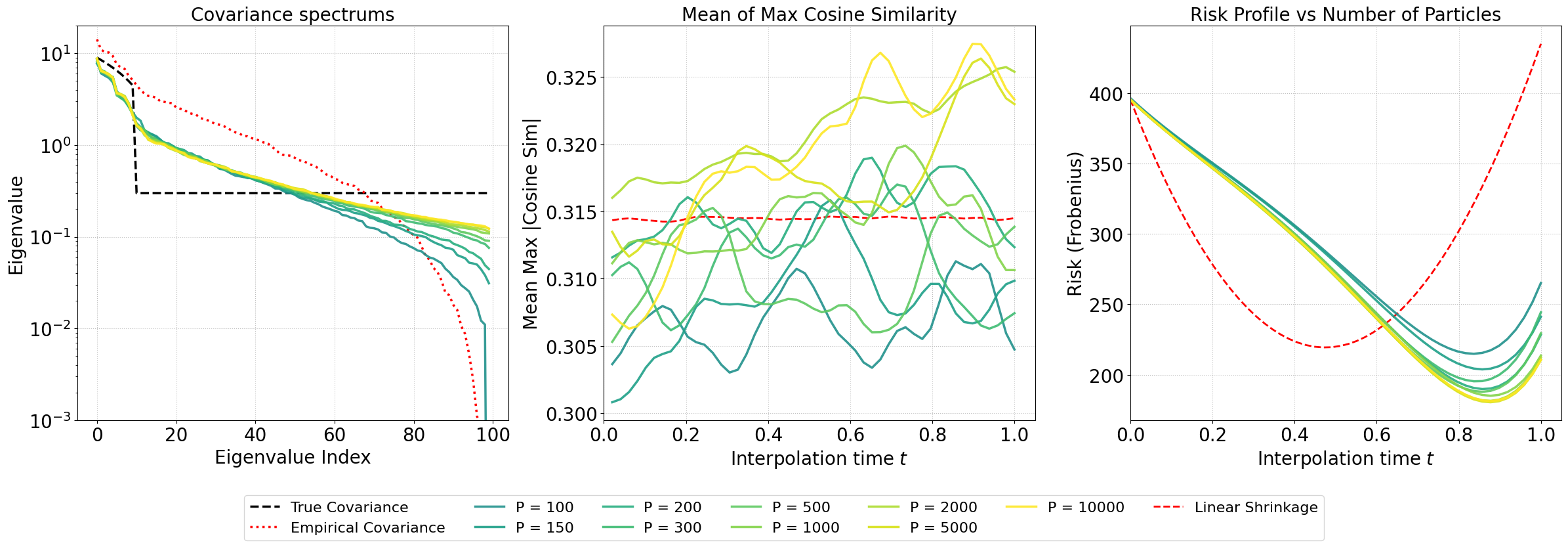
Figure 2: Monte Carlo estimates for covariance recovery: spectrum tails benefit most from SI; eigendirection alignment improves with larger sample size; total risk correspondingly decreases.
An explicit investigation into estimator behavior as a function of data ratio D∼N4, schedule, and neural architecture capacity reveals that the regularization effect of SI persists even in highly data-limited regimes and can be further enhanced by calibrating schedule and network width.
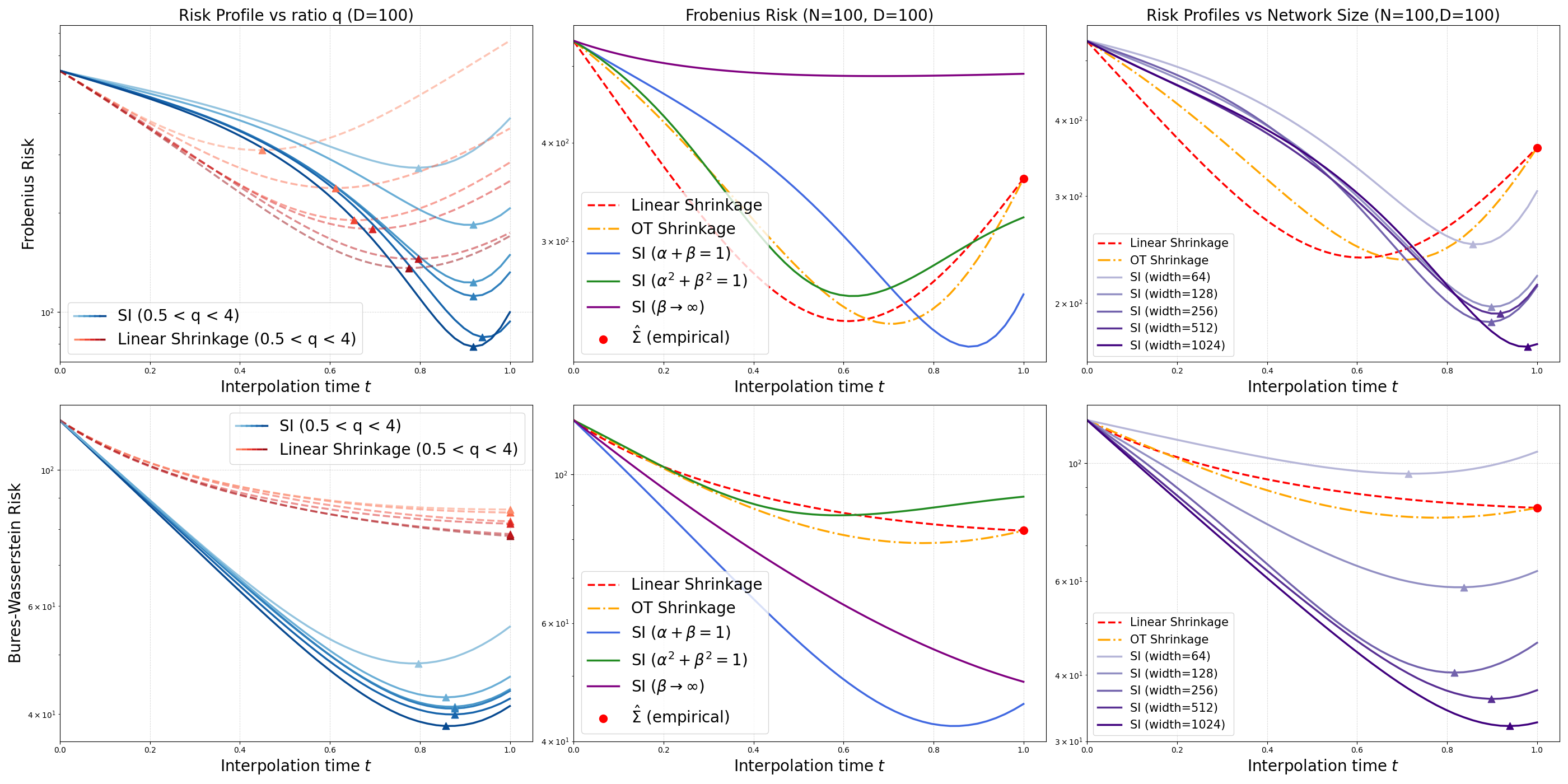
Figure 3: Risk profiles across varying data regimes, interpolation schedules, and model capacities, demonstrating SI's adaptability and lower minimal error than linear interpolation.
Real-World Application: fMRI Covariance Estimation
The practical efficacy of the SI estimator is validated on resting-state fMRI data (ABIDE-PCP/CC200 atlas), where D∼N5 and D∼N6—a regime where empirical covariances become singular. SI estimators, calibrated with the SURE penalty, achieve substantially lower out-of-sample negative log-likelihood than both Ledoit–Wolf linear shrinkage and Wasserstein-2 OT shrinkage, indicating superior generalization and robustness.
Theoretical Implications
By expressing covariance estimation as empirical risk minimization over parametric stochastic flows, the SI formalism intrinsically unifies spectrum-centric and eigenspace-regularizing estimators. Neural ODE parameterization of continuous-time vector fields decouples estimation from the empirical eigenspace, allowing the covariance estimator to nonlinearly adapt to signal structure. The observed risk improvements are underpinned by a weak error bound on the SI estimator, which demonstrates linear scaling with the D∼N7 vector field approximation error, controlled directly by the structural regularity of the true flow.
Practical Impacts and Future Directions
The SI estimator's ability to regularize both spectrum and basis addresses limitations endemic to classical shrinkage, enabling robust high-dimensional covariance estimation even in severe data-constrained scenarios such as neuroimaging. These advances naturally generalize to higher-order moment estimation and open research directions in efficient flow map parameterization, scalable risk estimation in nonsmooth settings, and integrative modeling—where covariance structure is entangled with generative assumptions beyond Gaussianity.
Computational cost remains higher than analytic estimators due to flow integration; thus, ongoing research into architectural simplification and efficient trajectory sampling is warranted. Further, the SI framework's compatibility with data-driven risk estimation portends its utility for automated model selection and calibration in broader probabilistic inference pipelines.
Conclusion
The stochastic interpolation framework reimagines covariance shrinkage as the optimal integration along a parametric flow—admitting both classical estimators and genuinely new, non-rotationally invariant regularizers. Neural parameterizations endow the estimator with the flexibility to adapt not only the spectrum but the eigenspace itself. Empirical evidence from both synthetic and neuroimaging data substantiates the SI estimator's lower statistical risk and improved out-of-sample performance, marking a significant advancement in high-dimensional covariance estimation and regularization methodology.