- The paper introduces a novel framework using sample-aware attention to organize historical input–output pairs and enforce strict causal ordering.
- It employs a hierarchical transformer that alternates temporal, spatial, and sample-level attention to capture complex, delayed dependencies in time-series data.
- The integration of TS-SCM synthetic causal priors demonstrably improves empirical performance and interpretability across diverse benchmarks.
Trio: Sample-Aware Time-Series Forecasting with Hierarchical Attention and Structural Causal Priors
Introduction
The paper "Trio: Learning Time-Series Forecasting with Temporal-Spatial-Sample Attention and Structural Causal Priors" (2606.07291) introduces a time-series forecasting framework that structurally rethinks how historical information is incorporated into prediction models. The key innovation lies in leveraging sample-aware attention mechanisms—temporal, spatial, and sample-level attention—to explicitly extract and utilize structured historical input–output relationships, departing from conventional models that treat historical context as an undifferentiated or flattened sequence. This approach is accompanied by a bespoke Time-Series Structural Causal Model (TS-SCM) for generating synthetic training priors that embody complex, dynamic, and realistic temporal dependencies. This essay details the architectural choices, the causal synthetic task design, the empirical results, and the far-reaching implications for generalizable time-series forecasting.
Structured Historical Context and Input–Output Correspondence
Traditional time-series models adopt one of two paradigms: using short lookback windows, which limits temporal context, or incorporating long sequences without distinguishing between segments with explicit input–output relationships. Trio advances a third paradigm where long histories are explicitly organized into aligned input–output pairs, allowing downstream modules to learn correspondences and dependencies vital to accurate prediction.
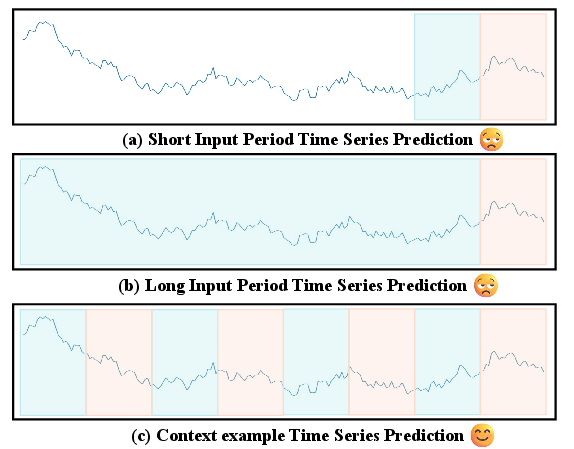
Figure 1: Representative input paradigms. Approaches (a) and (b) show short context and long undifferentiated context, while (c) (the Trio approach) exploits long historical context with explicit modeling of input–output correspondences.
This explicit episode structure aligns with the demands of PFN-style transfer learning, facilitating the reuse of historical mappings in forecasting tasks. Each episode includes multiple historical input–output pairs (lookback and future segments) plus a current query window for which future values are predicted. This hierarchy imposes strict causal ordering and prohibits temporal leakage, empowering retrieval modules to condition predictions on validated mappings from the past.
The Trio architecture integrates three principal forms of attention applied in a hierarchical and alternating manner:
- Temporal Attention: Models intra-window, within-segment dependencies, enforcing causality along the patch axis to capture lagged dynamics and multi-scale autocorrelations.
- Spatial Attention: Learns dependencies and interactions across variables at each time and window, facilitating inter-variable correlation modeling.
- Sample-Level Attention: Enables retrieval of relevant historical input–output pairs, analogous to matching the current query’s lookback with previously observed contexts and their future outcomes.
The model constructs historical and current tokens from patch embeddings of lookback and future segments (with learned query placeholders for unknown futures), arranges these hierarchically, and iteratively applies the three attention types.
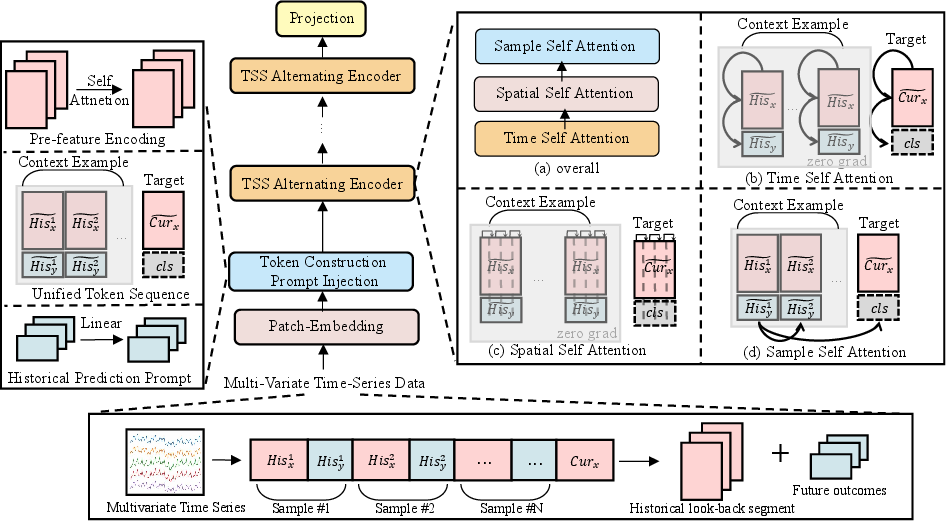
Figure 2: Overview of the sample-aware transformer architecture with temporal, spatial, and sample-level attention in a hierarchical alternating arrangement.
Sample-level attention operates beyond fixed-window architectures and is fundamentally distinct from baseline archival retrieval or nearest-neighbor search: it organizes context as explicit input–output evidential mappings, employing cross-window patch-wise retrieval via attention. This enables highly flexible and soft retrieval in latent representation space, rather than relying on raw similarity metrics.
Structural Causal Priors via TS-SCM
Training data with meaningful and diverse temporal dependencies is paramount for generalizable forecasting. Trio introduces the Time-Series Structural Causal Model (TS-SCM) as a mechanism for generating synthetic multivariate time series governed by directed graphs with configurable node mechanisms, edge-level time-varying lags, feedback loops, distributional drift, and flexible noise processes.
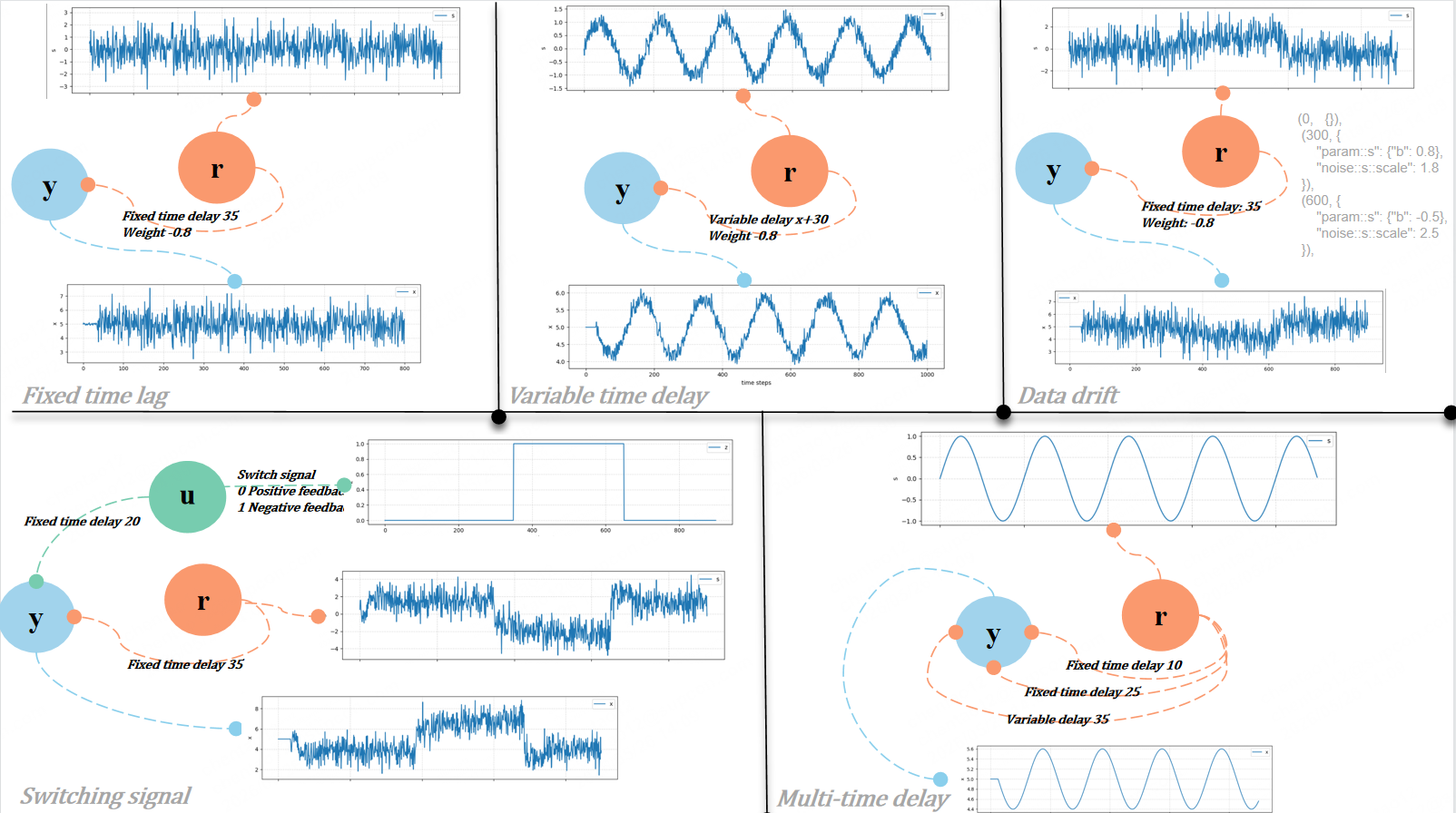
Figure 3: TS-SCM-generated structural causal dynamics showing hand-designed graphs and resulting time series with fixed-lag, variable-delay, distribution drift, feedback, and multi-delay effects.
Distinct features of TS-SCM include:
- Edge-Based Dynamic Lags: Each directed edge independently specifies delay mechanisms (fixed, random, state-dependent, or history-dependent), modeling realistic heterogeneous and non-stationary propagation latencies.
- Push-Based Event Scheduling: Signal delivery is scheduled into the future rather than pulled from a fixed history, aligning with causally correct multi-step interventions and preventing temporal misalignment.
- Noise and Drift: Synthetic sequences can exhibit nonstationary behaviors, driven by drift in node mechanisms, edge weights, or parameter perturbations, essential for robust forecasting priors.
Crucially, synthetic episodes are formatted to match the model’s input structure: collections of lookback–future pairs and a current query window, ensuring training and prediction are tightly aligned.
Empirical Evaluation
Synthetic Benchmarks: On controlled delayed-dependency synthetic datasets, standard SOTA models—including TimesNet, Crossformer, and TimeXer—demonstrate limited performance in capturing long or variable delays between input and target. Trio shows strong MSE reduction when incorporating sample-level attention, confirming the utility of explicitly retrieving and matching historical input–output pairs.
Public Benchmarks: On multivariate datasets including ETTm1, ETTm2, Weather, and Electricity, Trio delivers competitive or superior performance compared to strong baselines across a range of horizons, frequently achieving the best mean squared error (MSE). The benefit is more pronounced in domains with significant delayed or nontrivial cross-variable dependencies, and somewhat attenuated for highly regular or low-drift datasets.
Industrial Datasets and Retrieval-Based Comparisons: Trio outperforms RAFT and GTR retrieval-augmented forecasting, as well as backbone transformer and MLP baselines in industrial control applications, highlighting the effectiveness of explicit sample-level input–output modeling.
Ablation: Removal of sample-level attention degrades performance across datasets and horizons, affirming its role in capturing delayed and nonlocal dependencies. Scalability studies show that moderate context lengths offer most benefit; excessive context can dilute useful evidence and introduce noise.
Zero-Shot Transfer Using TS-SCM: Models pretrained solely on diverse TS-SCM tasks transfer better to real-world benchmarks than those trained on simpler synthetic datasets, achieving best-in-class zero-shot MAE and top MSE on most tasks. Nonetheless, no single synthetic prior dominates on all real-world dynamics, underscoring challenges in universal temporal transfer.
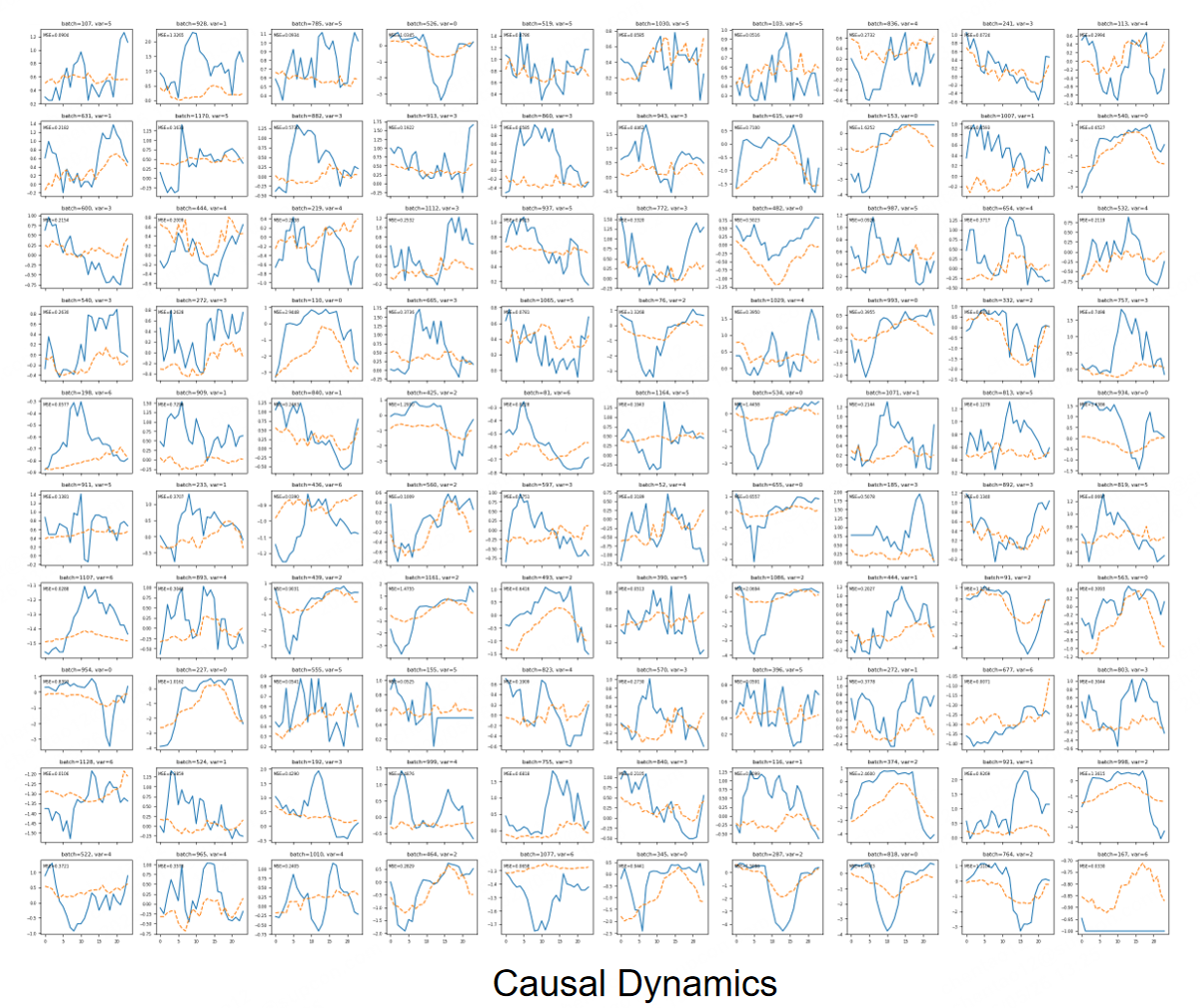
Figure 4: Qualitative results of the model trained with Causal Dynamics synthetic data: blue shows ground-truth, orange dashed are predictions.
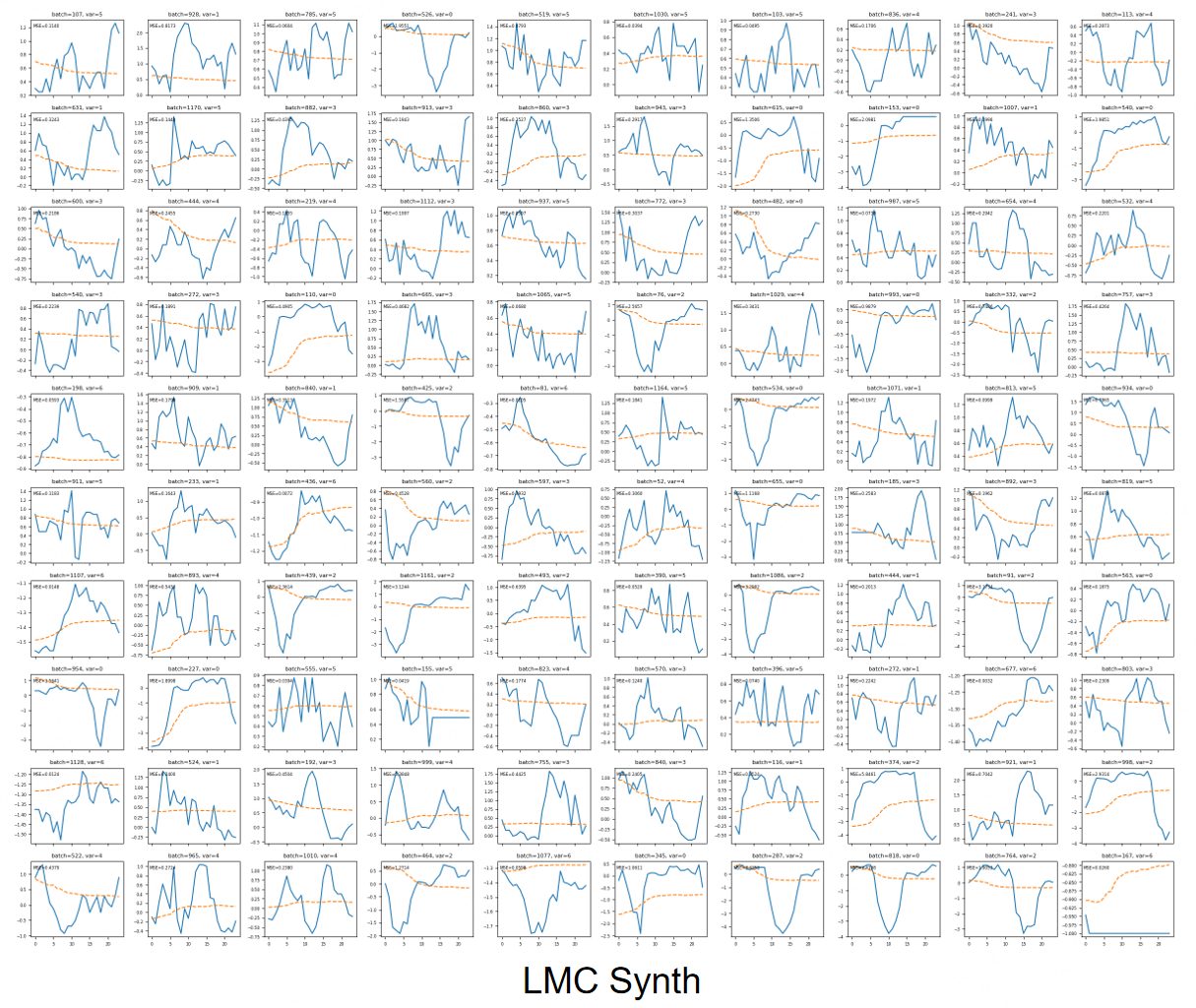
Figure 5: Qualitative results of LMC Synth-trained predictions show more stable yet oversmoothed outputs.
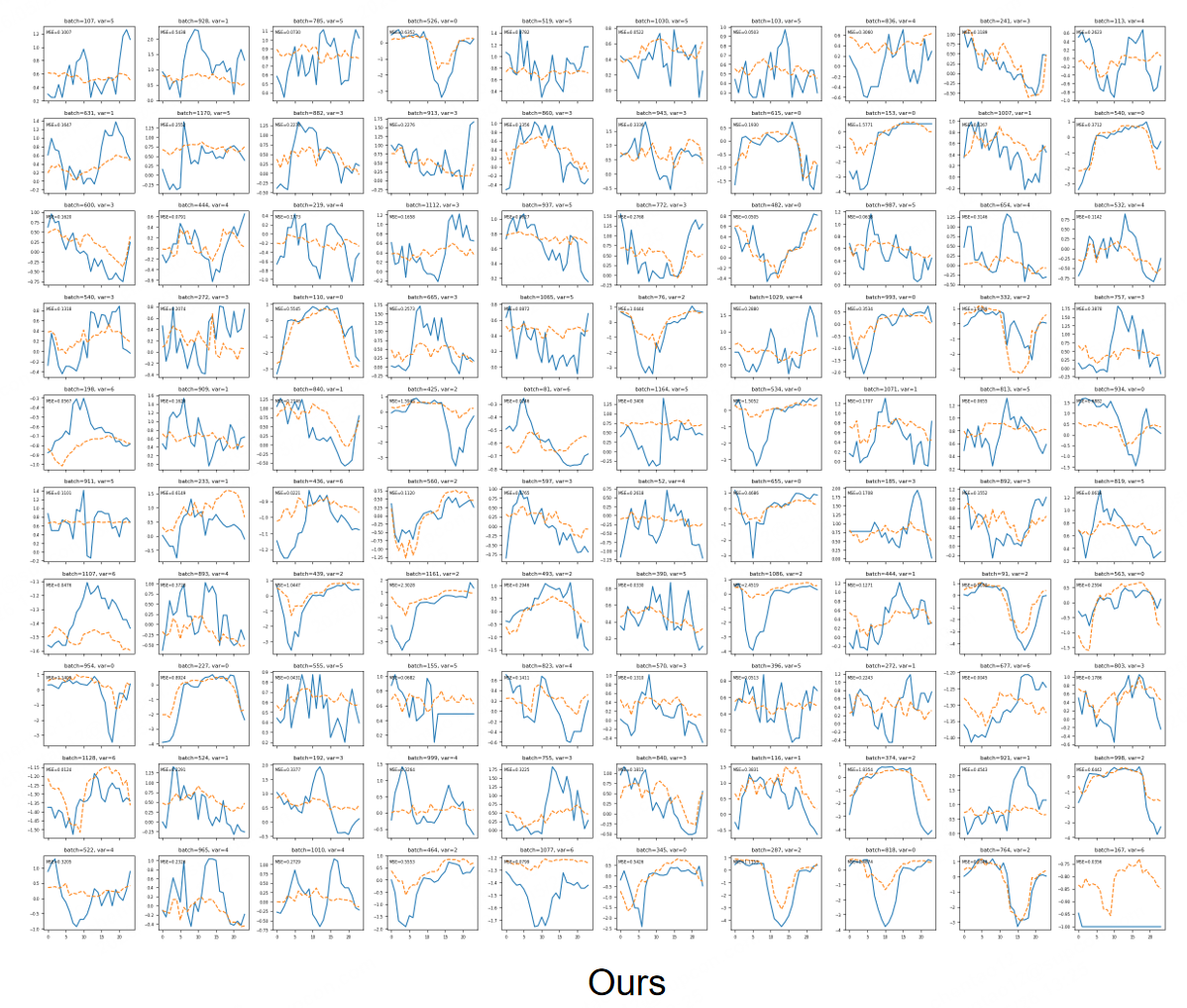
Figure 6: Model trained with the proposed TS-SCM synthetic data captures local fluctuations and peak–valley structures more faithfully.
Theoretical and Practical Implications
Trio’s explicit historical input–output modeling has significant implications:
- Transferability: By training on structured causal priors, Trio partially bridges instance-specific supervised learning and generalizable inference, offering a new path toward foundation models for time series.
- Interpretability: Explicit alignment of lookback with future allows downstream analysis of which historical episodes contributed to predictions, lending interpretability and troubleshooting capabilities absent in pure blackbox transformers.
- Retrieval-Quality Dependence: Performance depends on the composition and diversity of historical episode formats. Advances in context selection, episode curriculum, and loss scheduling may further boost retrieval fidelity.
- Synthetic-to-Real Transfer: While the exploratory zero-shot setting shows promise, general PFN-style forecasting remains challenging due to the gap between synthetic and real temporal distributions. Diagnostics for synthetic task realism and causal graph alignment will be critical.
- Modularity and Extension: The hierarchical attention design naturally extends to integrate exogenous variables, causal interventions, or domain-specific structural priors, supporting adaptation to industrial applications with complex lagged feedback and drift.
Conclusion
Trio establishes a rigorous and modular approach to multivariate time-series forecasting by organizing historical context into explicit input–output pairs and equipping architecture for temporal, spatial, and sample-level reasoning. The integration of causal synthetic priors via TS-SCM enhances both empirical accuracy and potential for transfer across heterogeneous domains. While significant challenges remain for full generalization and universal zero-shot forecasting, the advances in attention architectures and causal synthetic design presented in this work suggest promising directions for robust, interpretable, and transferable time-series models.