- The paper introduces HSCHG, a two-stage hierarchical and hyperbolic graph model that effectively aligns audio-visual cues and semantic hierarchies for robust event localization.
- The method employs multi-directional temporal and cross-modal edges, combined with bidirectional semantic constraints, to capture fine-grained and long-range dependencies.
- Experimental results on OV-AVEBench show significant performance gains over baselines, notably improving generalization to unseen event categories.
Hierarchical Semantic-Constrained Heterogeneous Graph for Audio-Visual Event Localization
Introduction
Open-vocabulary audio-visual event localization (OV-AVEL) presents significant challenges due to semantic misalignments and hierarchical inconsistencies occurring across multi-modal and temporal scales. While standard approaches traditionally embed audio-visual cues within Euclidean spaces, it is increasingly evident that these representations suffer from limited expressiveness when tasked with capturing hierarchical relationships across modalities, especially for unseen event categories. To address these deficiencies, the proposed Hierarchical Semantic-Constrained Heterogeneous Graph (HSCHG) develops a two-stage pipeline: first, constructing multi-granular graph-based representations in Euclidean space, and second, mapping these representations to a hyperbolic manifold where hierarchical entailment constraints are applied. Empirical results are presented on the OV-AVEBench dataset, highlighting substantial improvements over leading baselines, particularly for generalization to unseen categories.
Methodology
Heterogeneous Hierarchical Graph Structure
HSCHG constructs a graph with two levels of granularity: segment-level and video-level nodes, for both the audio and visual modalities. Input sequences are initially featurized by a frozen, pre-trained model (e.g., ImageBind) and partitioned into non-overlapping segments.
Within each modality, nodes are connected via multi-directional temporal edges (forward, backward, and undirected) to capture both local and long-range temporal dependencies. Hierarchical edges connect segment nodes to their respective video-level nodes, enabling aggregation of semantic information across temporal scales. Cross-modal edges, regulated by a dual-threshold filtering and gated fusion mechanism, inject information between the audio and visual modalities only when cross-modal alignment confidence is high, efficiently suppressing noise due to asynchrony or spurious correlations. The combination of intra-modal and cross-modal edges produces robust, multi-scale representations.
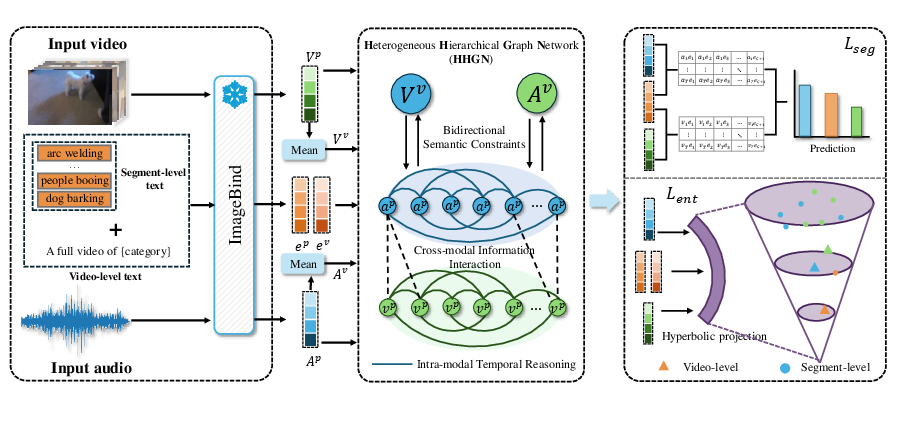
Figure 2: Architecture of HSCHG, displaying feature extraction, graph construction, hierarchical semantic constraints, and hyperbolic regularization stages.
Bidirectional semantic constraints enforce consistency: top-down calibration aligns segment updates with video-level context, while bottom-up aggregation refines the global representation by integrating evidence from relevant segments.
Hyperbolic Projection and Entailment Regularization
After graph reasoning in Euclidean space, both the learned multi-level audio-visual representations and the category text prototypes are mapped into a Lorentz model of hyperbolic space via a linear projection. Entailment cone constraints are then imposed:
- Intra-modal entailment: Segment-level embeddings are regularized to lie within the semantic cone defined by their corresponding video-level representation, capturing the parent-child relationship.
- Cross-modal entailment: Both video-level and segment-level audio-visual embeddings must also fall within the cones defined by text prototypes, which act as hierarchical semantic superordinates.
A hierarchical entailment loss, composed of terms for intra-modal and cross-modal relations, is optimized in conjunction with a standard cross-entropy segmentation loss. This hybrid objective aligns hierarchical geometric relationships throughout the multimodal graph and supports robust open-vocabulary generalization.
Experimental Analysis
Benchmark Comparison
On the OV-AVEBench dataset, HSCHG is directly compared with strong baselines including CMRA, PSP, MM-Pyramid, and the previous state-of-the-art OV-AVE. Notably, HSCHG achieves the highest overall 'Avg.' (mean of accuracy, segment F1, and event F1) in the total category setting: 59.7 versus OV-AVE's 57.8. The improvements for unseen categories are especially pronounced where robust generalization is most challenging, yielding an 'Avg.' of 56.5 compared to 55.8 for OV-AVE. These gains are attributed to the structure-aware regularization and explicit hierarchical modeling unique to HSCHG.
Ablation Studies
Removing the Heterogeneous Hierarchical Graph Network (HHGN) or the hierarchical entailment regularization loss (Lent) both yield demonstrable drops in performance across all metrics. Detailed ablations further show that multi-directional temporal edges, dual-threshold gated fusion, and bidirectional semantic constraints each contribute synergistically to the final results.
Hyperparameter Sensitivity
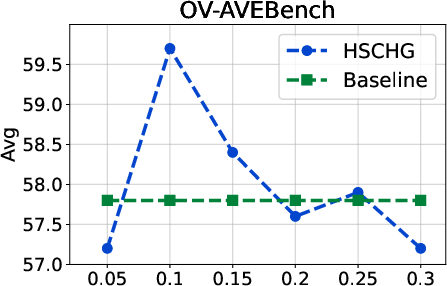
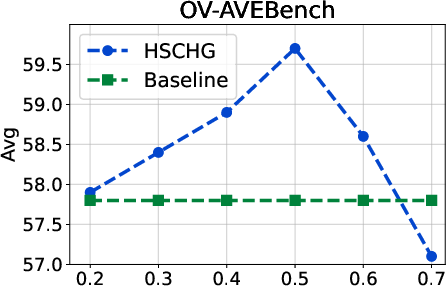
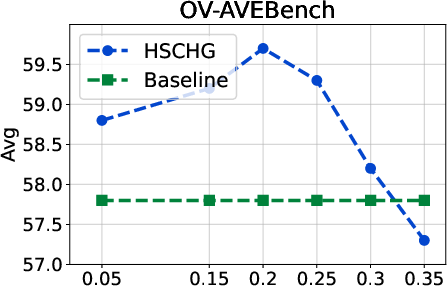
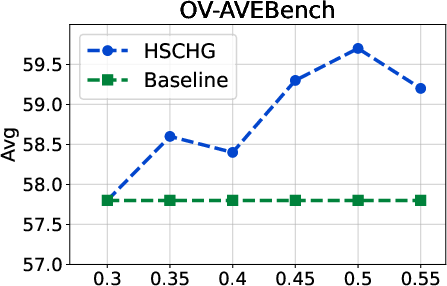
Figure 4: Hyperparameter analysis on OV-AVEBench, indicating the effect of intensity and threshold parameters on localization performance.
Analysis of hyperparameters illustrates that optimal results are obtained by balancing the strength of top-down context propagation with thresholding for intra-modal and cross-modal aggregation. Excessive global influence or overly permissive thresholding both degrade performance, indicating that the hierarchical structure is most beneficial when local and global signals are judiciously fused.
Qualitative and Visualization Analyses
T-SNE and UMAP visualizations confirm that HSCHG produces high-quality, discriminative embeddings with strong intra-class consistency and well-formed hierarchical structure. The positioning of segment-level versus video-level nodes clearly reflects the hierarchical entailment relations imposed in hyperbolic space; segment nodes cluster per category around their video-level parent, and all modal embeddings are anchored by the associated text prototypes.
Heatmap analysis of cross-modal cosine similarity supports the assertion that the dual-threshold mechanism effectively filters asynchronous or spurious correlations, reinforcing robust temporal alignment where both audio and visual cues are event-relevant—while down-weighting mismatched or background segments.
Implications and Future Directions
The HSCHG framework sets a precedent for integrating hierarchical semantic constraints and non-Euclidean relational priors within the challenging context of open-vocabulary multi-modal event localization. Practically, these advances support deployment in content retrieval, surveillance, and automated video understanding scenarios where novel event types and noisy cross-modal alignments are ubiquitous.
Theoretical implications suggest that further exploration of hyperbolic and other curved geometries may continue to produce gains in tasks with inherent compositional or hierarchical structure. Notably, the separation of representation learning (in Euclidean space) and relation alignment (in hyperbolic space) may generalize to other multi-scale, multi-modal reasoning tasks in AI.
Conclusion
HSCHG, by leveraging a hierarchical, heterogeneous graph for modeling temporal and cross-modal structure, and imposing geometric regularization in a hyperbolic manifold, surpasses existing methods for open-vocabulary audio-visual event localization. The explicit enforcement of both intra-modal and cross-modal entailment constraints leads to strong localization accuracy and robust generalization, as demonstrated on OV-AVEBench. These contributions underline the importance of hierarchy- and geometry-aware approaches in advancing multimodal AI systems.
Reference: (2606.07033)

