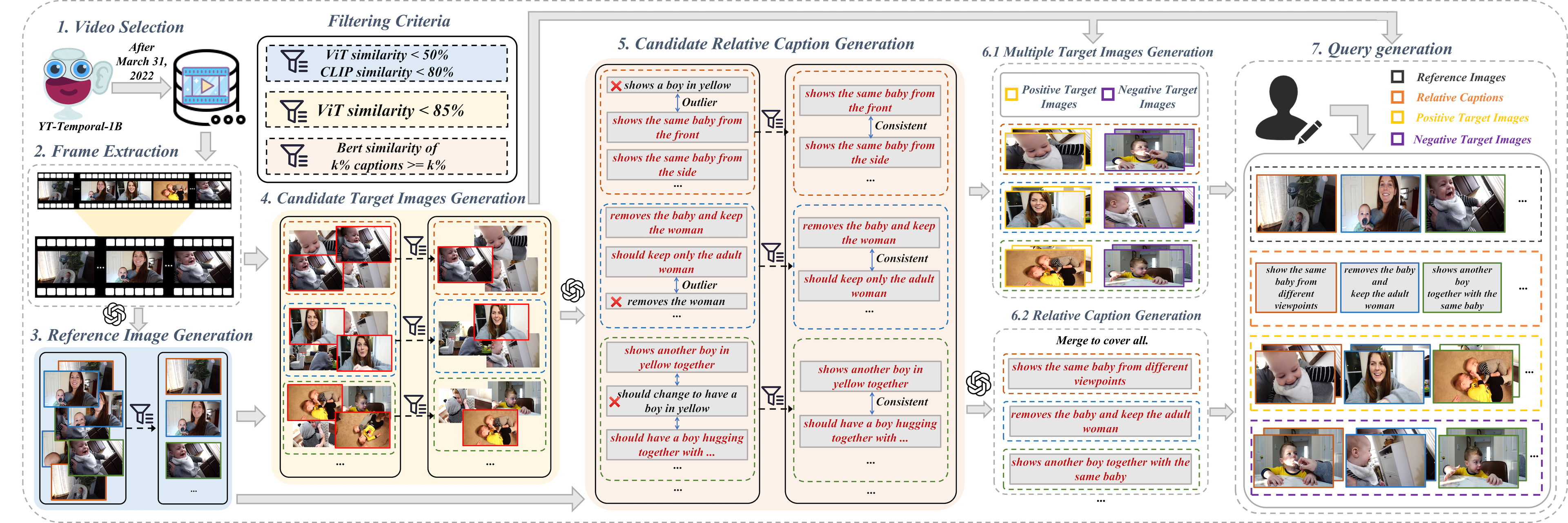
- The paper introduces ZeroSight, a new benchmark dataset that enforces visual/semantic consistency and true zero-shot learning by excluding pretraining overlap.
- It employs a multi-stage LLM-assisted pipeline to generate 54k queries and nearly 200k candidate images from diverse, post-2022 videos.
- The SC4CIR method enhances retrieval accuracy through bidirectional consistency checks, significantly improving PNR-mAP and overall system performance.
Benchmarking Genuine Zero-Shot Composed Image Retrieval with Video-Sourced Consistent Data
Introduction
This work systematically addresses key limitations in zero-shot composed image retrieval (ZS-CIR) benchmarks by introducing ZeroSight, a dataset and evaluation framework designed to enforce two critical conditions: visual/semantic consistency between reference and target images, and true zero-shot learning by ensuring no overlap with data seen by large pre-trained models (e.g., CLIP). Existing CIR datasets exhibit major weaknesses in both respects, which this paper demonstrates empirically and methodologically.
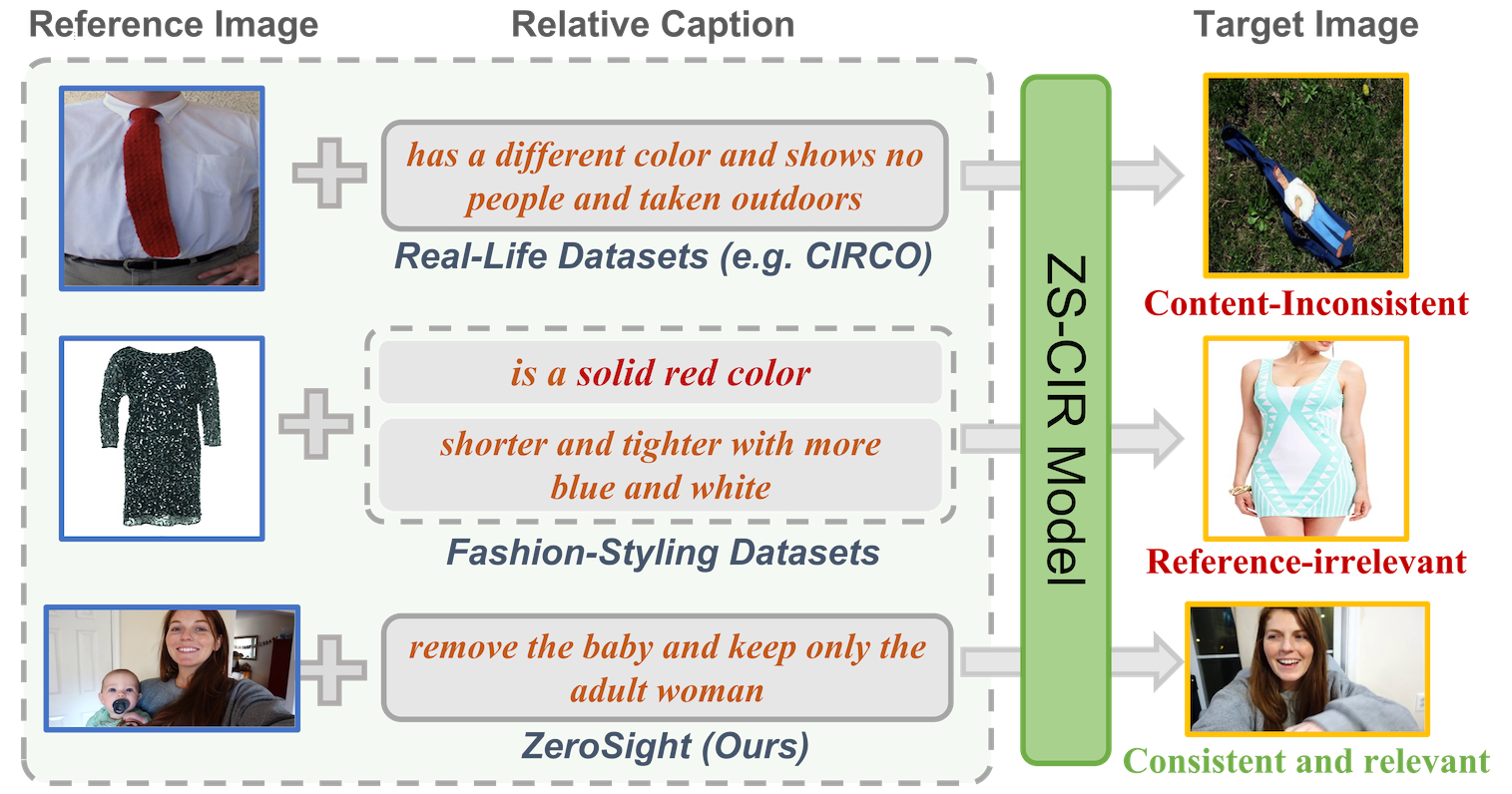
Figure 1: ZeroSight image pairs (bottom) exhibit strong visual and semantic consistency compared to prior datasets, which suffer from irrelevance and noise.
Limitations of Existing ZS-CIR Datasets
Current CIR datasets construct image pairs from public image sets (e.g., MS COCO, NLVR2, Fashion datasets), resulting in two primary flaws:
(1) Inconsistent pairs: Even when annotated with relative captions, pairs often capture only tenuous or abstract similarities, leading to visual/semantic mismatch between reference and target images. Figure 1 and Figure 2 illustrate these inconsistencies and the noisy annotation pipelines that produce them.
(2) Contamination of pretraining data: Many public datasets used for ZS-CIR evaluation were included in pretraining for CLIP, resulting in overestimation of model performance due to information leakage. This is especially problematic in evaluation protocols that purport to measure zero-shot generalization.

Figure 2: Existing ZS-CIR pipelines (top) yield inconsistent pairs and overlap with CLIP pretraining; ZeroSight replaces both with post-2022 video-sourced frames.
ZeroSight Dataset: Construction and Properties
ZeroSight introduces a novel, large-scale CIR benchmark constructed from post-2022 videos to guarantee no overlap with CLIP's training set. The pipeline comprises multi-stage LLM-assisted selection, filtering, and captioning mechanisms that ensure each query consists of:
The resulting dataset comprises over 54k queries and nearly 200k candidate images drawn from 12,000+ diverse videos, spanning 12 main content categories (Figure 4).
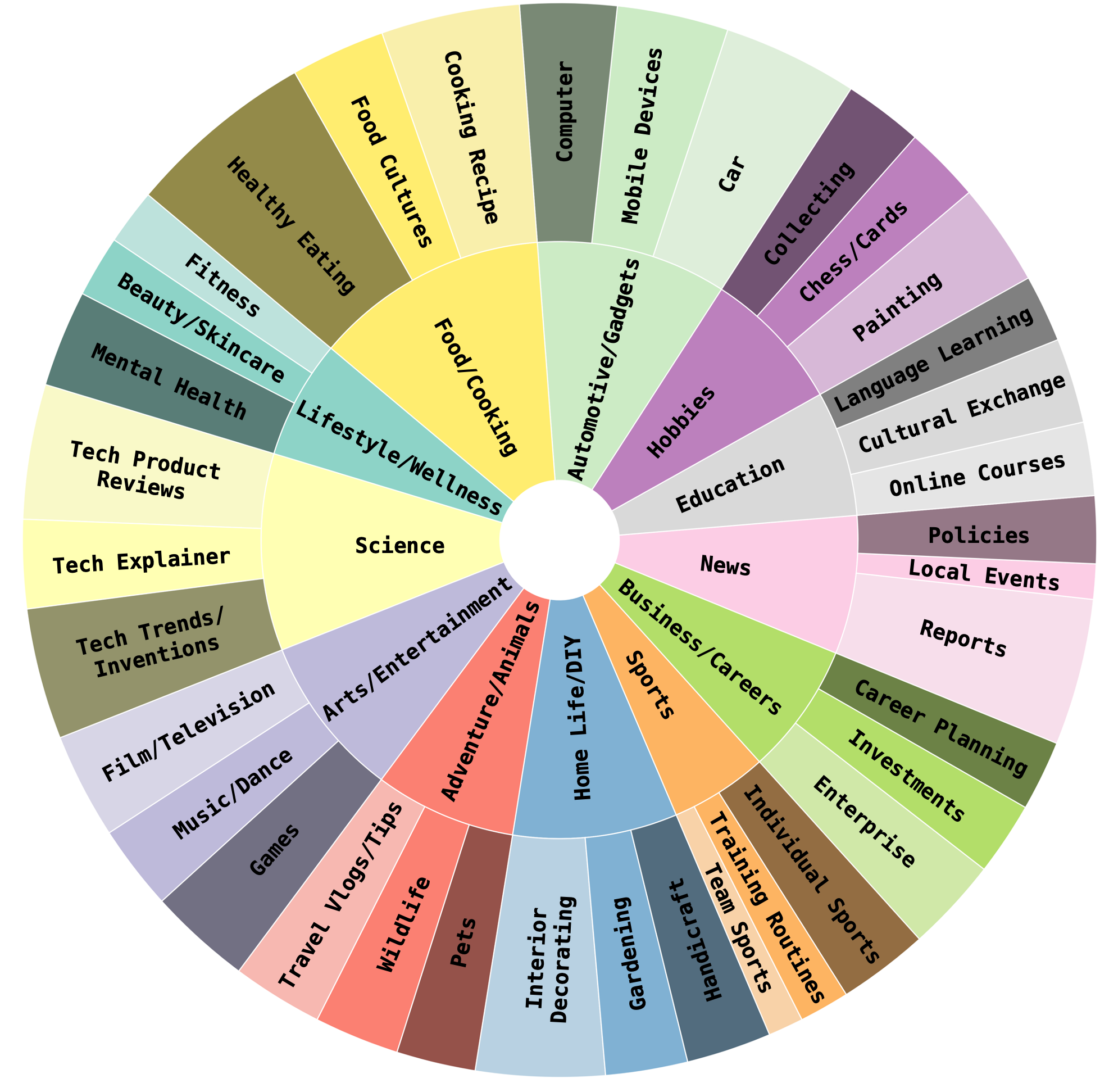
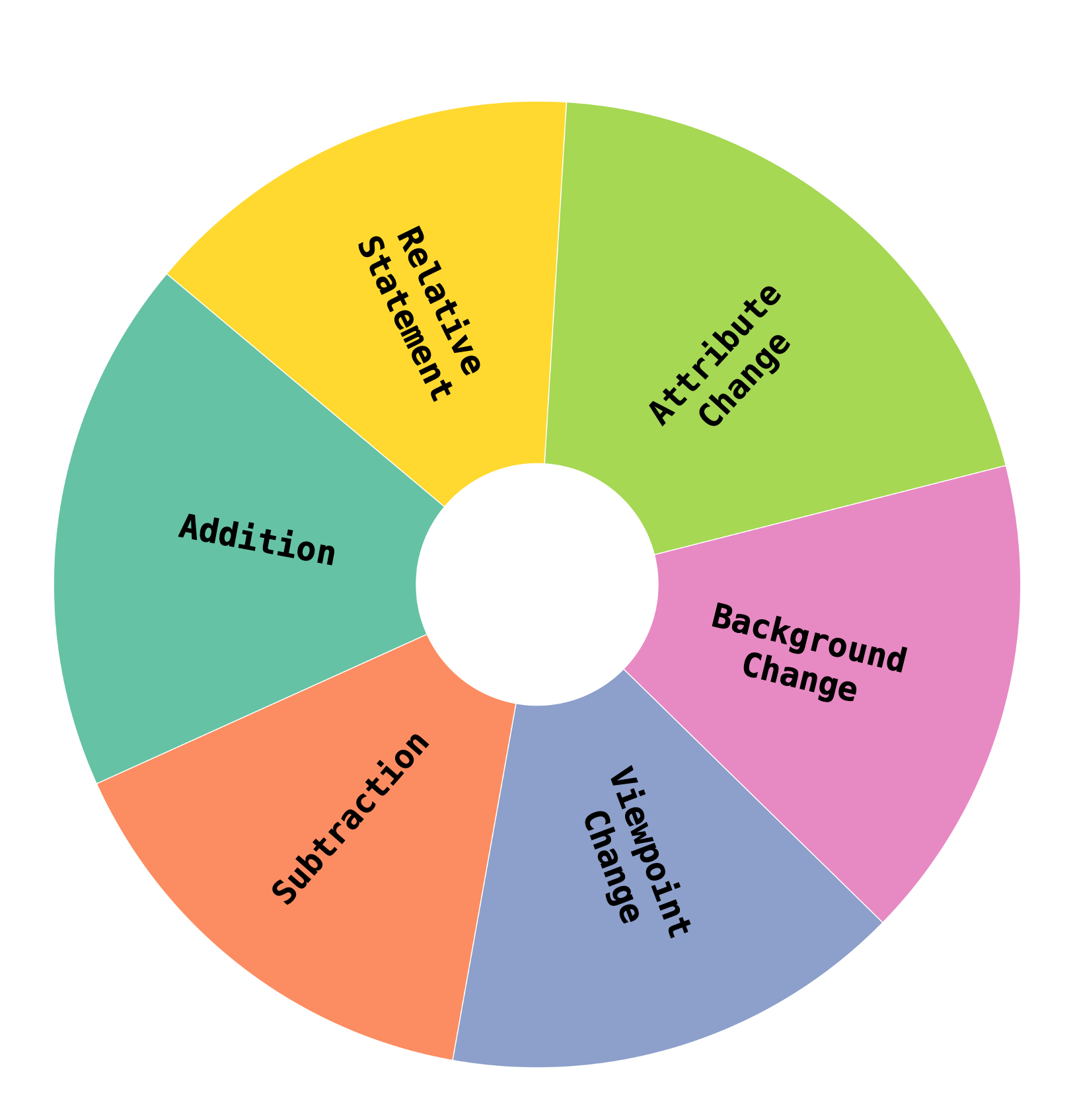
Figure 4: ZeroSight achieves broad semantic and visual coverage with a diverse distribution of video categories and subcategories.
Query types are systematically annotated to cover addition, subtraction, attribute changes, viewpoint changes, background changes, and relative statements, each defined by the nature of the desired transformation between reference and target.

Figure 5: Category-divided examples of ZeroSight queries, illustrating fine-grained control over compositional modifications.
Evaluation Framework and Metrics
ZeroSight supports rigorous benchmarking via mean average precision (mAP) and a novel positive-negative ranking mAP (PNR-mAP) that penalizes retrievals in which hard negatives are prioritized over true positives, addressing the practical retrieval setting where discrimination between highly similar candidates is crucial.
Empirical evidence (Section 7, Figure 6) reveals severe inflation in prior datasets due to overlap with pretraining data: CLIP models see substantial gains in retrieval performance after being explicitly fine-tuned on the same image set. Larger architectures are especially susceptible to this effect.
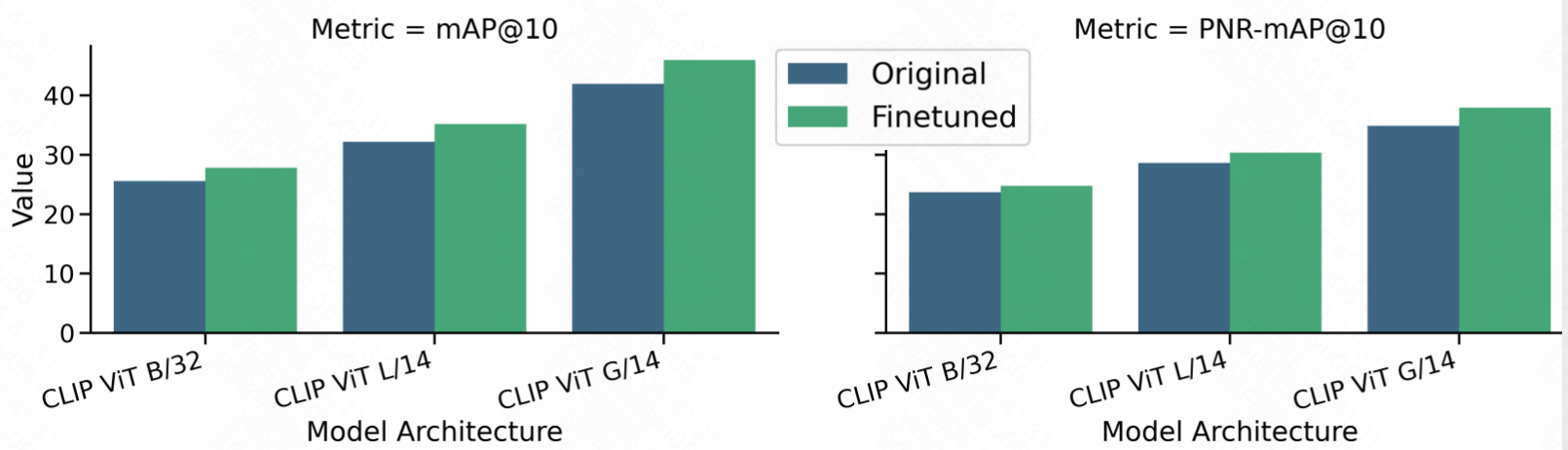
Figure 6: Training on the evaluation set dramatically inflates ZS-CIR performance; increases are more pronounced for larger CLIP architectures.
SC4CIR: Symmetric Consistency Checking for Robust Retrieval
To further increase the rigor of benchmarking and method validation, this work proposes SC4CIR, a training-free, plug-and-play MLLM-driven method for filtering and re-ranking candidate target images through a set of symmetric consistency checks:
- Forward retrieval: Reference + text → candidate
- Reverse process 1: Candidate – text → reference
- Reverse process 2: Candidate – reference → text
These checks are used to compute aggregate symmetry-aware similarity scores for reranking. As demonstrated empirically, SC4CIR provides substantial improvements in PNR-mAP, with the largest gains occurring for training-free CIR methods.
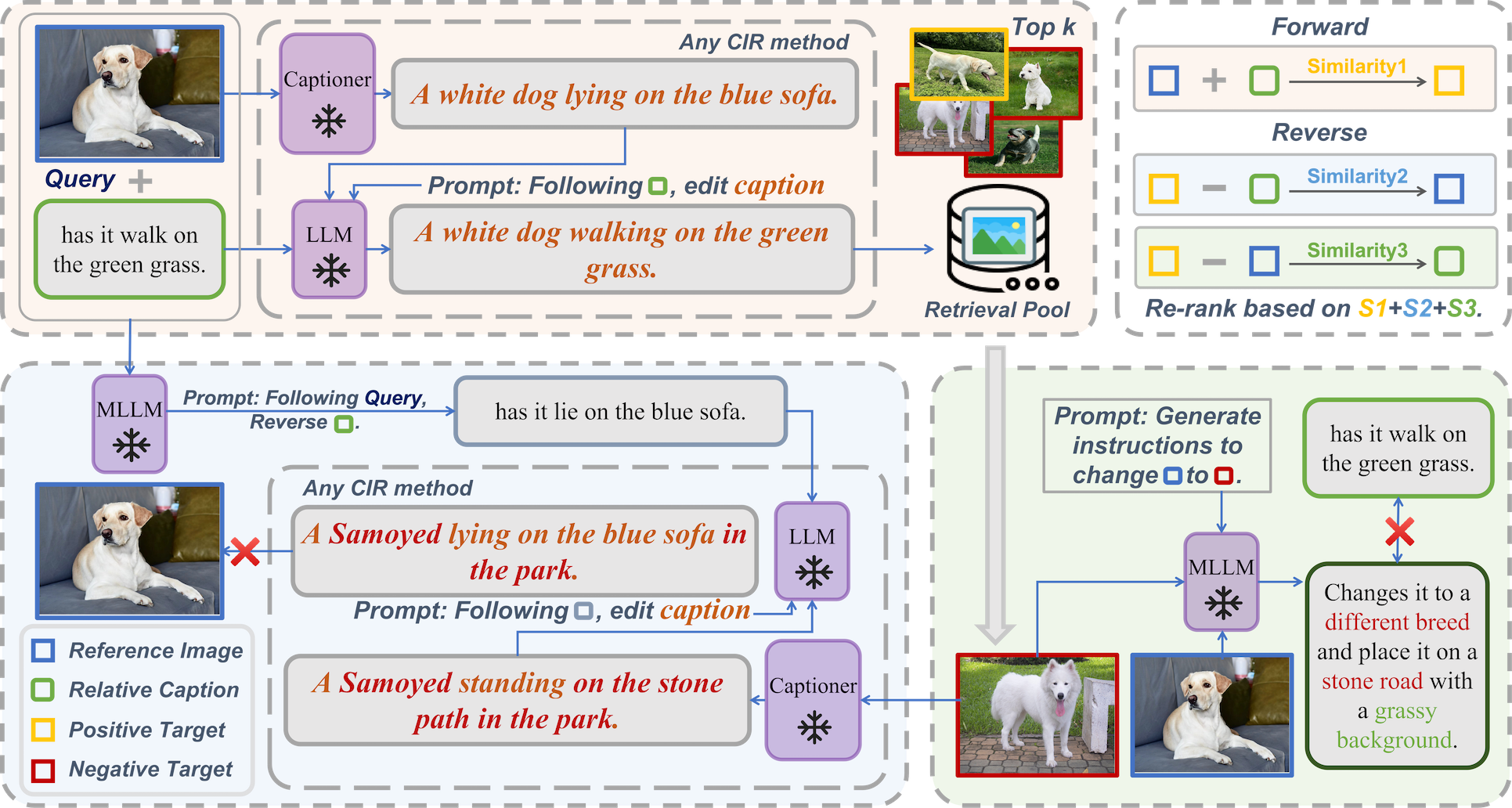
Figure 7: SC4CIR alternates forward and reverse flows via MLLMs for robust verification of candidate-target correspondence.
Experimental Results
Comprehensive evaluations are performed with 27+ ZS-CIR and CIR methods. Key findings:
- Training-based methods outperform training-free methods when true-consistency data is provided.
- SC4CIR consistently improves PNR-mAP and mAP across backbones and methods; gains are especially large for models without task-specific training.
- Existing datasets provide inflated performance metrics—for example, SEIZE (ViT-L/14) achieves mAP@5 of 13.02 on ZeroSight versus 24.98 on CIRCO, reflecting the improved discrimination and zero-shot nature of the new benchmark.
- Ablation studies further confirm the importance and additive benefits of bidirectional, LLM-driven consistency checks.
Qualitative Analysis
Case studies (Figure 8) show that ZeroSight poses a significant challenge for existing CIR retrieval systems: methods relying only on image or text features frequently return hard negatives, failing to distinguish subtle compositional changes that are typical in highly consistent video frame pairs.
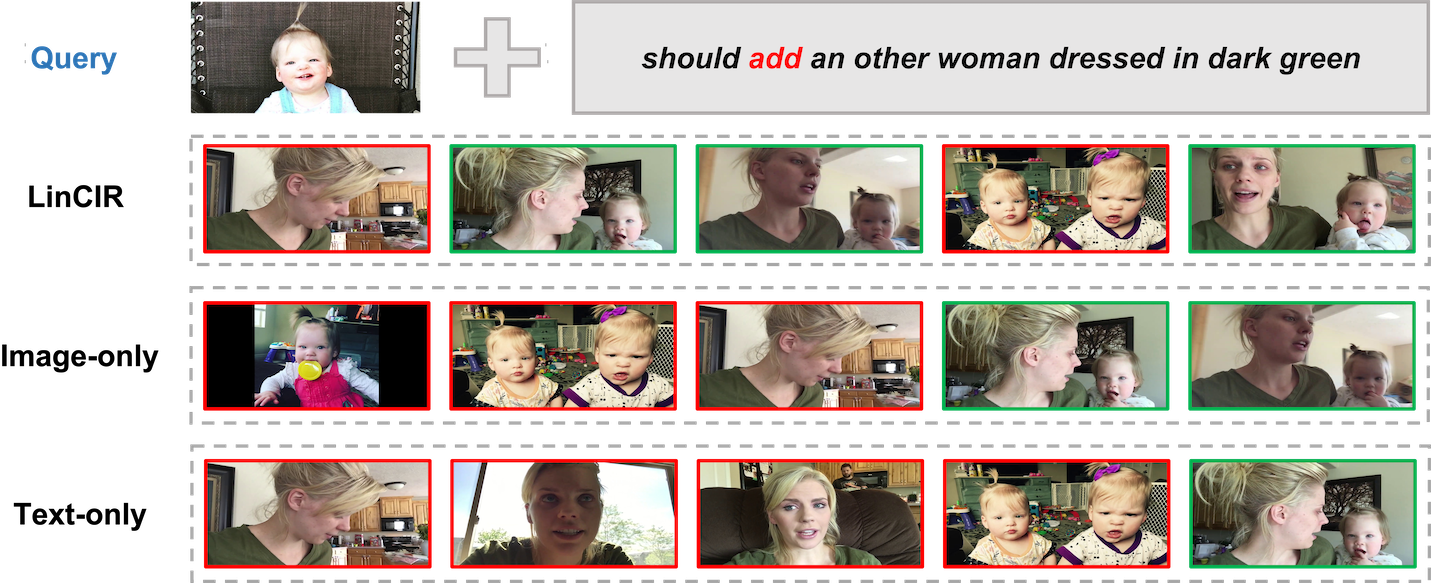
Figure 8: Hard negative challenge—state-of-the-art methods often retrieve visually similar, but incorrect, images in the ZeroSight setting.
Theoretical and Practical Implications
The results establish that prior CIR evaluations substantially misestimate zero-shot image-language composition capabilities due to both flawed dataset construction and score inflation via pretraining overlap. By formalizing video-sourced, strictly out-of-pretraining-sample CIR, ZeroSight redefines rigorous benchmarking. The inclusion of SC4CIR further advances compositional retrieval methodology toward settings demanding maximal accuracy in fine-grained discrimination, supporting applications from medical to satellite imagery.
The demonstrated effect of dataset overlap on evaluation sets provides a cautionary benchmark for future multimodal AI research. The robust pipeline introduced for dataset construction sets a standard for future benchmarks in compositional and retrieval tasks.
Future Directions
- Extension of the ZeroSight protocol to other compositional or multimodal retrieval domains (e.g., video-to-text, multimodal QA).
- Derivation of stronger baseline methods capable of solving SC4CIR-formulated tasks without significant manual or annotation cost.
- Exploration of generalization characteristics in models fully prevented from seeing test-distribution data during pretraining, including continuous monitoring of public image/video dataset overlap.
Conclusion
The introduction of ZeroSight and SC4CIR establishes a new standard for benchmarking compositional retrieval in truly zero-shot regimes. The experimental analysis highlights substantial overstatement of model capabilities in existing benchmarks and underscores the need for strictly disjoint and semantically fine-grained datasets. The provided pipeline and methods are adaptable to a wide range of evaluation protocols, and will play a critical role in the continued maturation of research in compositional vision-language retrieval and multi-modal generalization (2606.07032).