- The paper presents CL-CLIP, a CLIP-based continual object detection architecture that mitigates background relegation and catastrophic forgetting.
- It introduces a cost-volume guided decoupling pathway and a multi-expert RoI head to stabilize spatial category signals and reduce cross-category interference.
- Experimental results on PASCAL VOC and MS-COCO validate improved old-category retention and balanced plasticity compared to existing state-of-the-art methods.
CL-CLIP: A Cost-Volume Decoupling Framework for Continual Object Detection with CLIP
Continual Object Detection (COD) mandates maintaining recognition performance on previously learned categories while sequentially incorporating new categories. Despite the demonstrated zero-shot generalization of recent vision-LLMs (VLMs), such as CLIP, existing open-vocabulary detectors experience severe catastrophic forgetting when applied in continual settings due to label incompleteness and the shared-head design. The core challenge arises from the background relegation effect: unlabeled objects from previous tasks are misclassified as background, which rapidly erodes decision boundaries during sequential fine-tuning.
This paper introduces CL-CLIP, a CLIP-based continual object detection architecture that systematically tackles background relegation and head interference by leveraging cost-volume-guided category decoupling. The method is specifically motivated by the observation that zero-shot image-text alignment priors from frozen CLIP models can provide stable, spatially informative category signals, which, if used for feature routing, can prevent cross-category interference regardless of annotation incompleteness.
Methodological Contributions
CL-CLIP builds upon the F-ViT-style open-vocabulary detection pipeline with two central innovations: (1) a cost-volume-guided decoupling pathway informed by dense category-wise CLIP image-text similarities, and (2) a Multi-Expert RoI head with per-category convolutional experts and a drift-regularized FPN.
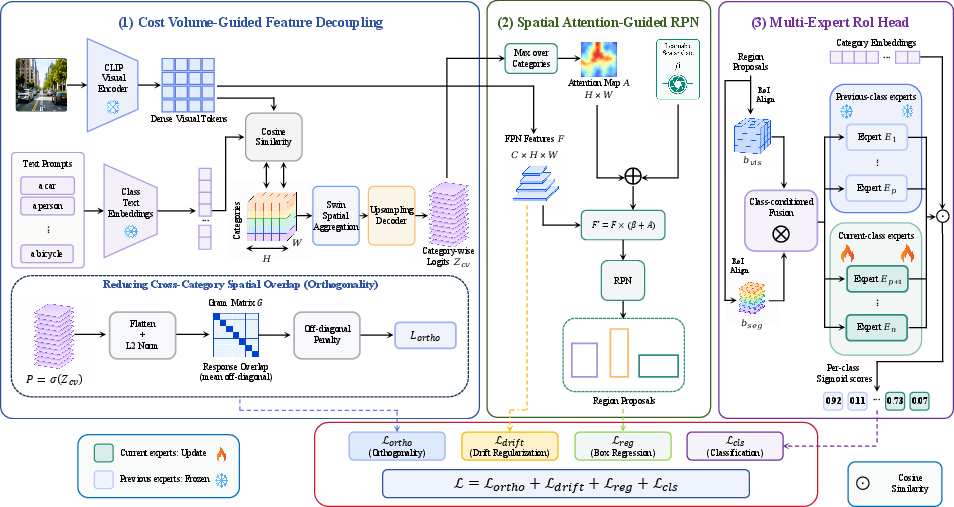
Figure 1: Overview of CL-CLIP, highlighting cost-volume-guided decoupling, spatial-attention guided RPN, a Multi-Expert RoI head, and the orthogonality loss.
The architecture proceeds as follows:
- Cost-Volume Decoupling: For an input image, dense CLIP visual tokens are aligned with all relevant textual category embeddings to form a cost volume. This category-indexed spatial map is derived from frozen CLIP encoders and provides a stable spatial prior that is invariant to downstream continual fine-tuning. To reduce the co-activation of spatial locations across categories, a Gram matrix-based orthogonality penalty is introduced, directly minimizing response overlap between category masks.
- Spatial-Attention RPN: Proposal generation utilizes a residual gating mechanism where the maximum response across all category-wise cost-volume slices serves as a foreground prior. This form of spatial biasing overcomes naive RPN suppression of unlabeled regions and ensures higher proposal recall for both old and new categories.
- Multi-Expert RoI Head: The RoI features for each proposal are decoupled via category-specific cost-volume gating and processed by per-category convolutional experts, producing CLIP-aligned scores via cosine similarity to text embeddings. Old-task experts are frozen after their respective training steps; current-task experts are updated, providing architectural isolation and inhibiting catastrophic drift. EWC-style drift regularization on the shared FPN further stabilizes adaptation dynamics.
Experimental Analysis
Baselines and Decoupling
An empirical study across multiple CLIP variants (FineCLIP, FG-CLIP, EVA-CLIP, SigLIP2) on PASCAL VOC and MS-COCO reveals that, while zero-shot open-vocabulary detectors retain high current-class accuracy, they fail to preserve detection capacity on previously learned classes during continual fine-tuning, with mAP for the old categories frequently collapsing to nearly zero.
Main Results: PASCAL VOC and MS-COCO
On standard PASCAL VOC splits (10+10, 15+5, 19+1), CL-CLIP achieves the highest all-class mAP among compared methods, with especially large gains in old-class retention compared to F-ViT baselines and substantial advances over both prompt-based and replay-based COD approaches.
On the 4-step MS-COCO continual protocol, CL-CLIP maintains a balanced accuracy/plasticity tradeoff, outperforming IOR and MMA baselines both in [email protected] and under stricter mAP@[.5:.95] metrics.
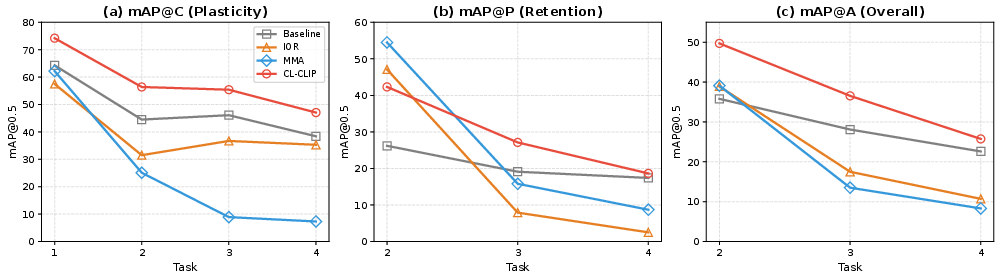
Figure 2: CL-CLIP maintains strong plasticity and overall accuracy across a 4-task COCO sequence versus baselines.
Backbone Generalization
CL-CLIP's architectural advances generalize to different CLIP backbones. Improvements in both retention and adaptation hold consistently for FG-CLIP and FineCLIP.
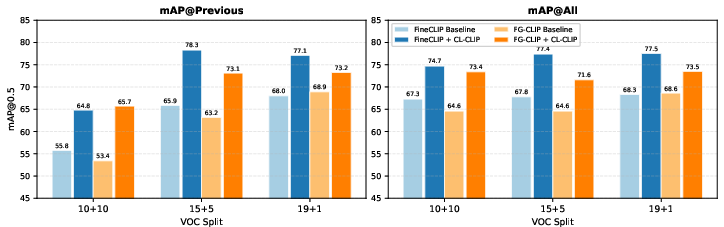
Figure 3: Consistent improvements in retention and accuracy are observed across both FineCLIP and FG-CLIP backbones on PASCAL VOC.
Feature Space Structure
t-SNE analyses of post-training RoI features show that CL-CLIP generates more semantically compact and separated feature clusters than the baseline. This demonstrates that cost-volume gating combined with category expert specialization leads to a more structured and less entangled embedding space.
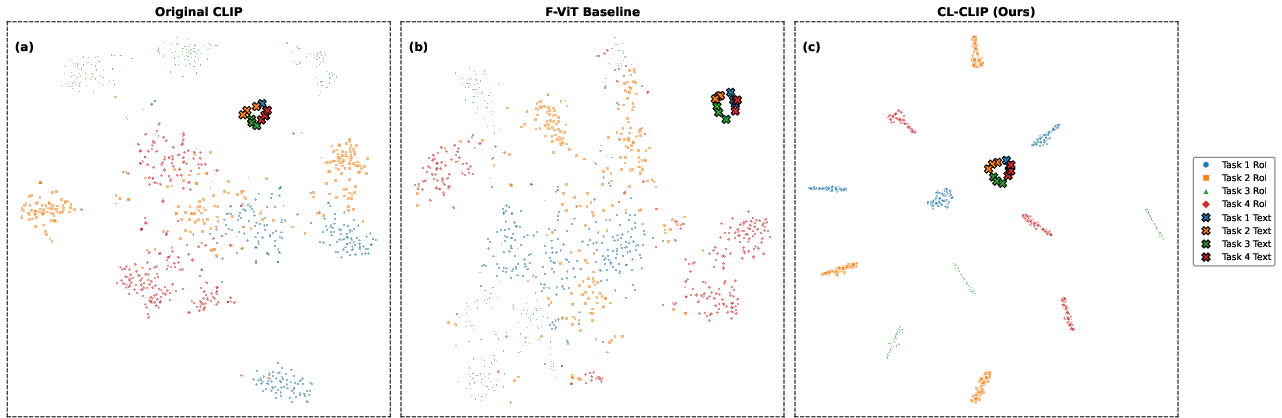
Figure 4: CL-CLIP forms more compact and separable RoI feature clusters after continual updates, contrasting with the entangled structure of F-ViT and FineCLIP.
Efficiency Tradeoffs
Inference analysis on PASCAL VOC shows that, while per-category experts cause inference FLOPs to grow linearly with the number of seen categories, CL-CLIP remains more efficient than F-ViT baselines due to a lighter cost-volume pathway, notably in low-to-moderate class regimes.
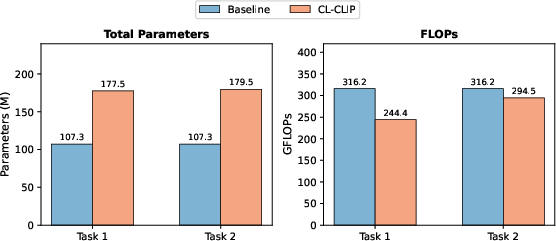
Figure 5: Despite per-category expert growth, CL-CLIP exhibits lower FLOPs than the F-ViT baseline with competitive parameter counts.
Ablation Studies
Component ablations establish that:
- Category decoupling is indispensable; drift regularization alone cannot guarantee retention.
- Orthogonality loss on the cost-volume substantially reduces response overlap and improves old-category AP. Without it, the network rapidly collapses towards category-agnostic foreground patterns.
- The class aggregation module, inherited from CAT-Seg, is detrimental under missing-label supervision and should be omitted.
- Proposal recall and detection accuracy are both improved by the residual-gated attention mechanism in the RPN.
Implications and Future Directions
CL-CLIP reframes the continual detection challenge within open-vocabulary models as a structural problem, solvable by explicit spatial category decoupling rather than exclusive reliance on optimization-level extrapolation (distillation, regularization, replay). The work suggests that foundational vision-LLMs possess stable priors exploitable for continual adaptation, provided that destructive cross-class mixing dynamics are mitigated at the architectural level.
Future research should aim to mitigate the linear growth in inference cost by exploring parameter-efficient expert sharing, sparsification strategies, or dynamic expert routing. Leveraging structured cost volumes in other dense prediction tracks (e.g., segmentation, tracking) for continual adaptation is also a promising avenue.
Conclusion
CL-CLIP establishes that cost-volume-guided category separation enables robust continual object detection atop frozen CLIP backbones, outperforming both naive open-vocabulary transfer and state-of-the-art COD-specific methods. This cost-volume routing paradigm offers a principled path forward for scalable, update-tolerant vision systems leveraging large VLMs.

