- The paper introduces MiTaS, a framework that fuses multi-resolution tactile feedback for precise contact-rich robotic manipulation.
- It uses dedicated CNN stems and transformer fusion to integrate RGB, GelSight, and high-frequency Evetac sensors for spatial and temporal alignment.
- Experimental results show an 80% average success rate across tasks, significantly outperforming vision-only and dual-modality baselines.
Introduction
The paper "Multi-Resolution Tactile Imitation Learning for Contact-Rich Robotic Manipulation" (2606.06281) systematically investigates the fusion of heterogeneous tactile sensors for robot learning in contact-rich manipulation. The core contribution is the Multi-Resolution Tactile Sensing (MiTaS) framework, which leverages data streams from both frame-based (GelSight Mini) and event-based (Evetac) tactile sensors, in conjunction with an egocentric wrist-mounted RGB camera, to robustly parameterize a flow-matching imitation learning policy. The approach exploits the temporal and spatial complementarity between tactile modalities, thereby addressing perception bottlenecks introduced by occlusion and the fast transient dynamics that vision-only or single-modality tactile feedback cannot reliably resolve.

Figure 1: MiTaS integrates RGB (blue), GelSight Mini (red), and Evetac (yellow) sensors on the gripper, fusing their multi-resolution tactile streams for contact-rich control.
Multi-Resolution Tactile Fusion Architecture
Sensor Modality and Egocentric Mounting
MiTaS deploys a tri-modal sensory suite: an RGB wrist camera (25 Hz, 2 frames/channel), a GelSight Mini sensor (25 Hz, vision-based tactile, providing high spatial resolution of local contact geometry), and an Evetac sensor (16 event-based frames/timestep at 200 Hz, capturing fine-grained high-frequency contact events). All sensors are rigidly mounted on the robot gripper to provide synchronized egocentric observations.
Each modality is processed by a dedicated CNN stem, mapping sensor-specific frames to token grids whose spatial configuration matches sensor geometry and enables spatial alignment across modalities. Tokens are augmented with learned positional encodings and modality embeddings. All feature tokens are then concatenated and fused via a multi-layer transformer encoder with full cross-modality self-attention, avoiding typical information bottlenecks in multimodal architectures. The policy network itself is instantiated as a Diffusion Transformer (DiT), whose action chunk generation is conditioned on these fused representation tokens.
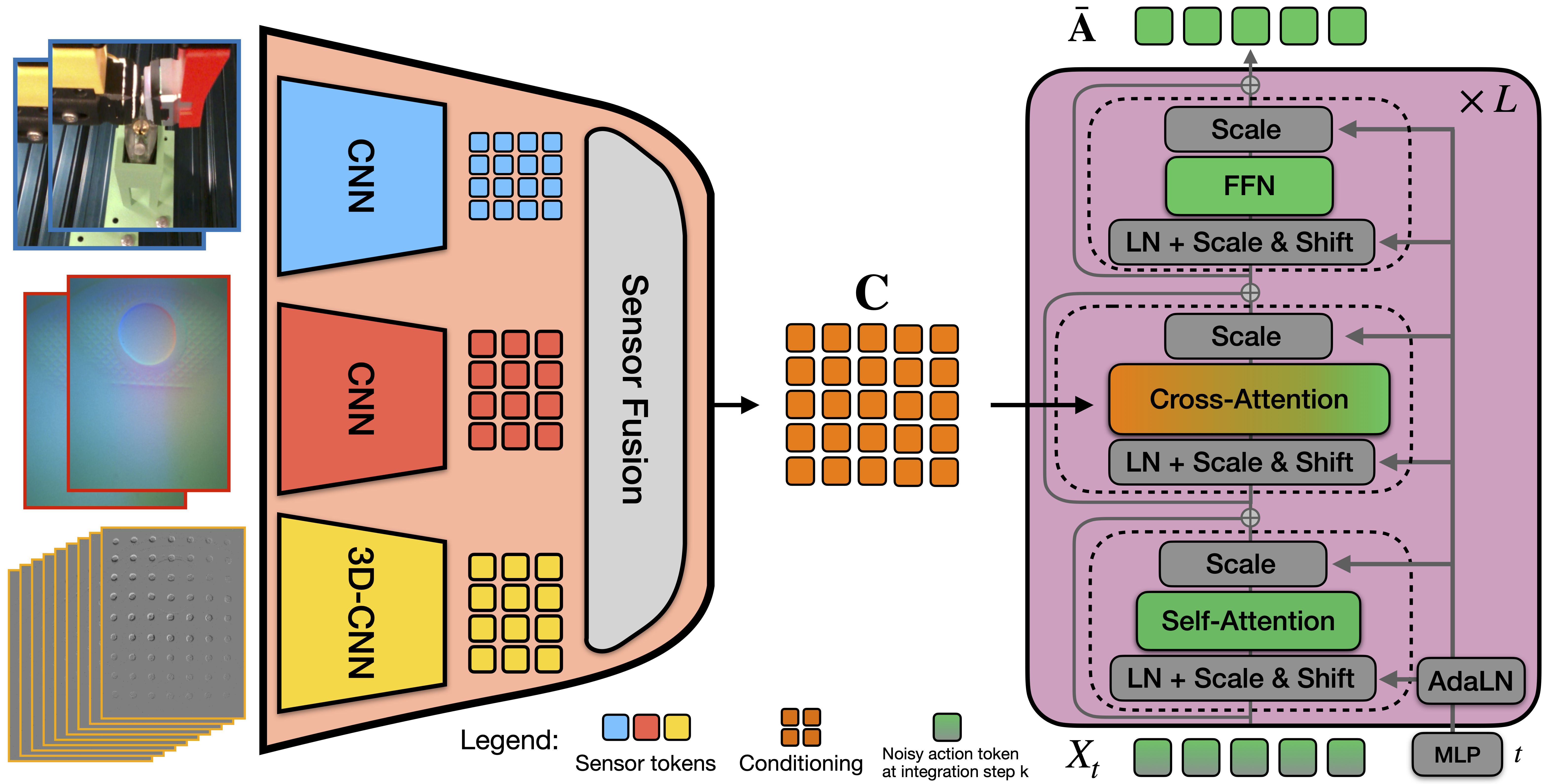
Figure 2: Modality-specific CNN encoders produce token embeddings for Vision, GelSight, and Evetac; tokens are fused by transformer attention to condition a flow-matching policy.
The control policy operates strictly in the space of relative (delta) Cartesian end-effector commands, with all inference over sequence chunks conducted from image and tactile streams alone—i.e., without robot state input—necessitating robust spatial and temporal inference from high-dimensional sensory indices.
Action generation employs a flow-matching generative model: the DiT policy is trained to produce the conditional velocity field tracing a noise-to-action path between observed demonstrations and randomized latent noise, leveraging techniques from recent generative imitation learning literature. This chunked, temporally coherent action formulation confers strong closed-loop reactivity, while the token-level transformer fusion enables dynamic modulation of modality routing depending on task phase and observation context.
The MiTaS architecture supports a multi-tactile co-training regime: during training, high-frequency Evetac features are available, but at inference time, the policy can be evaluated only with the visual and GelSight modalities (i.e., Evetac dropped), demonstrating that latent representations transfer dynamics-promoting structure into the visual-tactile stream for those tasks where full deployment of all sensors may not be possible.
Experimental Evaluation
Task Design and Setting
Performance is benchmarked on five canonical contact-rich manipulation tasks:
- Gear Assembly
- Board Wiping
- Lamp Installation (FurnitureBench)
- Key in Lock
- Lightbulb Connection
These tasks span a range of interaction modes, from transient impact and dynamic alignment (where event-based tactile information is critical) to persistent, fine-grained geometry control (where vision-based tactile sensors are essential). All policies are trained on 30 human teleoperated demonstration rollouts per task, on a Franka Panda with a parallel gripper.





Figure 3: Representative frames from the five contact-rich manipulation tasks—Gear Assembly, Board Wiping, Lamp Installation, Key in Lock, Lightbulb Connection.
Main Results
MiTaS achieves an average success rate of 80% across all tasks, outperforming both the multimodal tactile transformer baseline Sparsh-X (54%) and both vision-only ViT-style models (31% and 26%). In particular, vision-only baselines fail completely on key insertion and lightbulb connection, which are dominated by occlusions and require rapid adaptation to local contact anomalies.
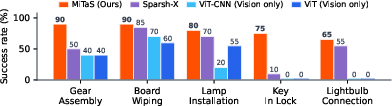
Figure 4: MiTaS achieves higher success rates than Sparsh-X and both ViT-based vision-only models on all tasks; tactile feedback is crucial in overcoming visual occlusion and unmodeled contact dynamics.
Task progression is illustrated in successful rollouts:




















Figure 5: Successful trajectories on all five tasks, demonstrating MiTaS robustness across the spectrum of contact complexities in dynamic real-world scenarios.
Sensor Contribution and Co-training Ablation
Ablation studies reveal that full tri-modal (Vision+GelSight+Evetac) policies outperform all dual-modality or vision-only variants. The Evetac stream is especially beneficial in tasks requiring rapid detection of slip, impact, or jamming. Notably, multi-tactile co-training (using all sensors during training, but omitting Evetac at test time) yields task-dependent gains, indicating successful cross-modal alignment in network representations.
Attention and Failure Analysis
Visualization of cross-modality attention weights during rollout demonstrates dynamic routing of policy attention in task phase-dependent fashion: the policy attends to vision during gross reaching motions, shifts to GelSight during persistent geometric contacts (e.g., screwing operations), and relies on Evetac for transient, high-frequency events such as initial contact and slip prediction.
Policy failures are characterized by failure modes such as premature rotation, misalignment, and contact loss, which directly correspond to the lack or suppression of informative tactile signals in those cases (see failure analysis figures).















Figure 6: Failed manipulation examples annotated across all tasks, illustrating sensitivity to missing or degraded tactile input streams.
Implications and Theoretical Significance
MiTaS demonstrates, both quantitatively and through attention analyses, the necessity of fusing multi-resolution tactile feedback to robustly solve manipulation tasks with high contact uncertainty and frequent occlusion. It empirically supports the thesis that spatially and temporally complementary tactile modalities—when encoded and fused with appropriate cross-attention mechanisms—enable effective sensorimotor control that pure vision-based or single-tactile approaches cannot match. The observed transfer from event-based sensor dynamics to vision-tactile representations in co-training is of particular note, suggesting a promising regime for scalable imitation learning with heterogeneous or partially-observed sensor sets [higuera_tactile_2025, funk_evetac_2024, george_vital_2024].
MiTaS also highlights the limitations of relying solely on visual input, a finding mirrored in systematic studies of visuotactile policy architectures [lenz_analysing_2024, hansen_visuotactile-rl_2022]. The transformer-based fusion with explicit token alignment further advances the design space for unified visuotactile architectures, aligning with recent trends in generalist multimodal policy design [xu_multimodal_2025, lygerakis2026vitapes].
Future Directions
Future work must focus on scaling MiTaS to broader sensor suites, higher-dimensional control (full 6D), and alternative demonstration pipelines that do not require human-in-the-loop teleoperation. Integrating explicit proprioceptive signals and recursive state estimation should further improve policy reactivity. Large-scale pretraining and sim-to-real transfer for multi-tactile policies, in particular using data augmentation from event-based tactile simulation, are likely to yield further improvements in data efficiency and policy robustness [ye_learning_2025, feng_anytouch_2025].
Conclusion
Multi-resolution tactile fusion, as operationalized by MiTaS, yields state-of-the-art performance on a suite of contact-rich robotic manipulation tasks. By integrating token-level transformer fusion across temporally and spatially complementary tactile sensors—without recourse to explicit state or force input—the framework establishes a new technical baseline for imitation learning in settings dominated by occlusion and fast transitions. These results reiterate the foundational role of high-bandwidth tactile feedback in robotic skill acquisition, underscoring the importance of unified visuotactile sensorimotor embeddings for advancing general-purpose, robust manipulation autonomy.