- The paper introduces GATE, a framework that defers SQL grounding decisions until execution feedback clarifies ambiguous mappings.
- It leverages a reusable execution-grounded memory to refine operator mappings, reducing redundant computations and boosting sample efficiency.
- Experimental results show GATE outperforms baseline models in accuracy, achieving 55.2% on RealEHR and high consistency in grounding updates.
Bootstrapping Semantic Layer from Execution for Text-to-SQL: An Expert Analysis
Text-to-SQL generation in real-world databases is confounded by pervasive underspecification: natural language queries often refer to entities or calculations that can only be meaningfully mapped to SQL after resolving how specific values, formats, or relationships are encoded in the underlying schema. This is exacerbated in expert domains, such as clinical data, where conventions are rarely fully documented and often idiosyncratic. Prevailing approaches attempt to inject a semantic layer—via documentation, expert annotations, or metadata extraction—to facilitate this mapping. However, these methods are inherently limited by the incompleteness of the documented semantic layer and the practical infeasibility of anticipating all domain-grounding requirements.
The paper introduces GATE (Grounding After Test from Execution), a framework that leverages execution feedback not solely for post-hoc validation or repair, as in many existing agentic or candidate-based pipelines, but as an explicit mechanism for bootstrapping missing groundings critical to iterative text-to-SQL generation. GATE operationalizes execution as an in-situ semantic discovery tool, maintaining a set of open grounding hypotheses for unresolved SQL fragments and resolving these only when executional context makes their interpretation testable and unambiguous.
GATE: Execution-Guided Grounding
The GATE method is structured around three core components: (1) representing partially grounded SQL plans with explicit operator interfaces and unresolved mappings (operators), (2) utilizing execution-guided feedback to test and constrain the set of viable groundings for each unresolved operator, and (3) iteratively updating and reusing execution-grounded memory that records discovered groundings for future reuse. The framework eschews premature hypothesis commitment, which is prevalent in both decomposition-first strategies and in approaches that inject candidate groundings directly into SQL before execution-based selection or repair.
In GATE, when a user query requires a grounding not directly specified or recoverable from available documentation, the corresponding operator in the SQL plan is marked as ungrounded. Candidate SQL fragments (grounding hypotheses) for this operator are generated, each holding to the operator’s interface but differing in their underlying assumptions about the data's semantics. The already-grounded parts of the plan are executed, and the resulting observations are analyzed against predicates associated with each hypothesis. Only the hypothesis supported by the execution feedback is ultimately stored in a reusable memory structure, enabling cumulative resolution of similar uncertainties in subsequent queries or planning stages.

Figure 1: GATE’s deferred hypothesis commitment allows the agent to withhold committing to an SQL grounding for query components such as runner_up_gap until execution over partially grounded operators provides evidence supporting a single interpretation.
In Figure 1, the agent maintains competing hypotheses about how to derive the "runner_up_gap" from "final_time," only grounding this component after execution confirms whether the value is an absolute time or a relative gap.
Iterative Operator Grounding with Execution-Grounded Memory
The iterative nature of GATE enables it to interleave grounding decisions with executional testing, progressively completing the SQL plan as each unresolved operator is grounded through successful hypothesis testing.
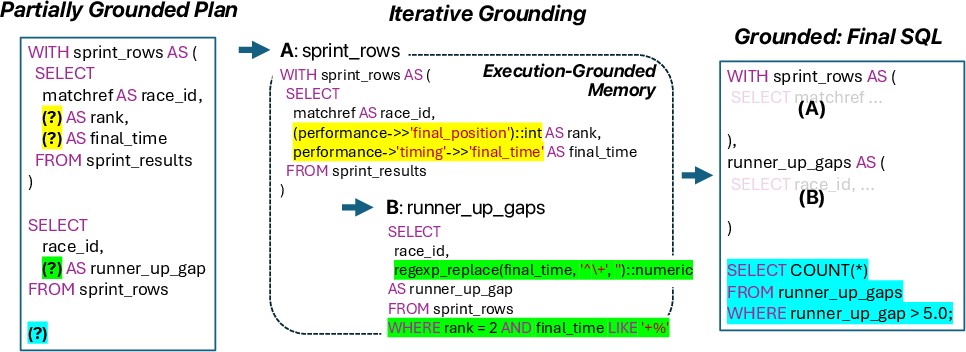
Figure 2: The accumulation of execution-grounded memory allows iterative reuse of previously tested and validated operator groundings, significantly reducing redundant computation and enabling cross-query generalization.
Each iteration focuses on grounding one operator judged to be the most informative bottleneck—selected through a plan evaluation policy that scores partially grounded plans by progress, bottleneck location, and estimated benefit of resolution. GATE maintains multiple concurrent partial plans, facilitating structured exploration of alternative resolution orders and grounding hypotheses.
Once a grounding is established for an operator, the corresponding SQL fragment, together with supporting execution evidence, is stored as a "grounding update" in memory. This update can be directly reused in other candidate plans with compatible operator interfaces, enabling downstream plans to avoid redundant execution and achieve higher sample efficiency.
Experimental Evaluation and Numerical Results
GATE is evaluated on three benchmarks reflecting varying degrees of semantic underspecification and domain constraint: RealEHR (least controlled, proprietary clinical data warehouse), EHRSQL (public clinical benchmark based on MIMIC), and LS-Hard (controlled setting derived from LiveSQLBench with web-recoverable groundings withheld).
Over all tested settings and model backbones (Qwen3-8B, GPT-5.4-mini), GATE achieves the strongest accuracy and execution accuracy metrics. On RealEHR with GPT-5.4-mini, GATE delivers 55.2% accuracy compared to 48.6% for ReFoRCE and 42.9% for ReAct. On EHRSQL, GATE yields 34.4% execution accuracy versus 27.6% and 32.2% for ReFoRCE and ReAct, respectively. On the most controlled LS-Hard, GATE reaches 45.1% accuracy, outstripping all baselines.
Ablation studies reveal that plan evaluation (bottleneck identification), evidence summarization (cumulative information integration for grounding decisions), and update reuse are all critical to GATE's performance. Removing plan evaluation leads to a 10.5pp accuracy degradation on RealEHR, while ablations of evidence summarization and grounding update reuse cause 8.4pp and 2.0pp drops, respectively. These results underscore the necessity of structured, memory-augmented, execution-guided grounding as opposed to naive repeated exploration or multi-agent delegation.
Cost analysis further establishes that GATE's gains are not attributable simply to larger search budgets: repeated ReAct runs with a comparable number of LLM calls (39.1 average) only reach 51.1% accuracy, whereas GATE attains 55.2% at 36.0 calls, emphasizing GATE's higher search efficiency given equivalent resources.
Consistency and Reusability of Execution-Grounded Memory
A comprehensive audit of grounding updates on RealEHR reveals 912 updates across 47 queries (average 19.4 per query), with 97.8% reused at least once in compatible plans. Contradiction analysis, both automated and manual, demonstrates a genuine contradiction rate of only 0.011% among table-overlap update pairs, signifying extremely high consistency and reliability in the memory structure. This confirms that execution-grounded updates are rarely locally inconsistent, even in complex, under-documented domains; remaining conflicts are attributable to genuine clinical ambiguities in grounding (e.g., multiple plausible laboratory measures corresponding to a single natural-language concept).
Implications and Future Directions
GATE exemplifies the advantages of maintaining deferred hypothesis commitment in semantic parsing for text-to-SQL—a strategy enabled by tight executional integration and memory-augmented planning. Execution becomes not merely a validation tool but an interactive, bootstrapping process for incrementally constructing a reusable semantic layer from experience.
Practically, this approach provides a highly robust fallback in domains where documentation lags data conventions, allowing LLM-based agents to adaptively discover and record groundings that circumvent static annotation bottlenecks. Theoretical implications extend to any semantic parsing setting in which underspecification, data convention drift, or incomplete schema knowledge preclude a single upfront mapping between natural language and formal representations.
Potential future work includes extending GATE to multi-turn, interactive settings where user intent itself is dynamic or underspecified; combining execution-guided grounding with online documentation augmentation; and integrating memory consolidation mechanisms to enable transfer of grounding updates across databases or downstream tasks in lifelong semantic parsing scenarios.
Conclusion
GATE advances execution-guided text-to-SQL generation by transforming execution from a post-hoc repair tool into an active mechanism for constructing semantic memory. By deferring grounding commitments until informed by concrete execution feedback and accumulating reusable memory entries, GATE outperforms both agentic and decomposition-based baselines on benchmarks encompassing highly controlled, public clinical, and real-world institutional settings. Its robust grounding mechanism is likely to inform future work in adaptive semantic parsing, database QA, and AI systems required to operate amid severe documentation deficits and idiosyncratic data conventions.