Trajectory Dynamics in Language Model Hidden States Predict Human Processing Costs Beyond Surprisal
Abstract: Human language comprehension unfolds sequentially: each word is processed in the context of those that came before, and the interpretation builds incrementally over time. Surprisal, the negative log probability of a word given its context, has been the dominant predictor of incremental processing cost. But surprisal reduces rich sequential representations to a single scalar at each word, discarding information about the direction in which the interpretation has been evolving. Dynamical-systems approaches suggest that the trajectory of the evolving interpretive state, not just its position at each moment,should shape processing, and language itself may have local momentum, since speakers plan utterances a few words at a time. We introduce trajectory extrapolation error: at each word, we fit a linear trajectory to the preceding hidden states of a transformer LLM and measure deviation from the extrapolated path. On the Natural Stories corpus, this measure is nearly orthogonal to surprisal (r = .044) and independently predicts self-paced reading times. The effect is especially pronounced in garden-path sentences, strengthens with model scale (GPT-2 Small to Large), and replicates across architectures with different positional encoding schemes (GPT-2 vs. Pythia/RoPE). A displacement control shows the effect is not reducible to representational change magnitude: displacement and extrapolation error predict in opposite directions. These findings reveal two dissociable components of processing cost: word-level prediction error (surprisal) and sensitivity to the local momentum of the unfolding interpretation (trajectory extrapolation error).

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how people read and understand sentences, one word at a time. It asks: do we slow down not only when a word is surprising, but also when a word makes the “direction” of the meaning suddenly change?
The authors introduce a new idea called “trajectory extrapolation error.” In simple terms, it measures whether a word keeps the sentence’s meaning moving in the same direction as before, or makes it take a sharp turn. They show this new measure predicts people’s reading speed even after accounting for how surprising each word is.
The main questions, in plain language
- Do readers care only about how surprising a word is, or also about whether it fits the recent flow of the sentence?
- Can we measure that “flow” using the internal workings of LLMs (like GPT-2)?
- Does this new measure explain reading slowdowns in tricky sentences (like “garden-path” sentences) and in normal stories?
- Is this effect real across different model sizes and designs?
How they studied it (using everyday ideas)
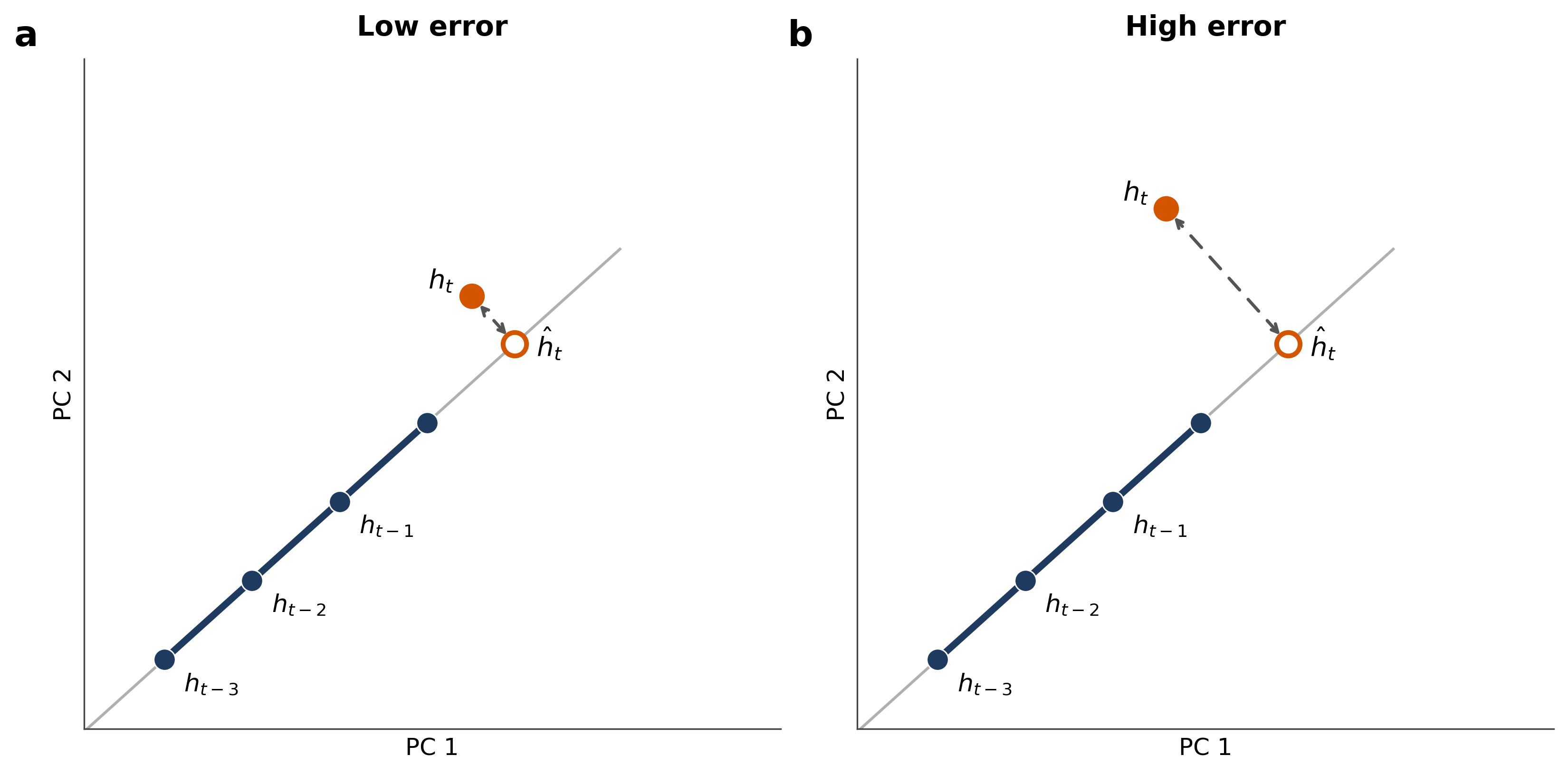
To study “flow,” the authors used a helpful analogy: imagine tracking a car’s path. If you look at the last few points of its route, you can draw a straight line to guess where it’ll be next. If the car suddenly turns away from that line, your guess is wrong—there’s a “trajectory error.”
Here’s how they applied that idea to language:
- They used transformer LLMs (like GPT-2). These models keep “hidden states,” which you can think of as the model’s moment-to-moment “mental snapshot” of the sentence so far.
- For each new word, they looked at the model’s last few “snapshots” (usually the past 3 words), fit a straight line through them, and predicted where the next snapshot should be if things kept going the same way.
- They then measured how far the actual snapshot landed from that prediction. This distance is the “trajectory extrapolation error.” Big distance = the sentence’s meaning took a turn.
- They also measured “surprisal,” which is a standard idea meaning how unexpected a word is in its context. High surprisal = very unlikely word; low surprisal = expected word.
They tested these measures on:
- Tricky “garden-path” sentences (like “The horse raced past the barn fell”), where readers often take the wrong path and must reverse course.
- Natural stories with thousands of words and many readers.
They compared how well surprisal and trajectory error predicted real people’s reading times.
What they found and why it matters
Here are the key findings, explained simply:
- Two separate effects, not just one:
- Surprisal (how unexpected a word is) predicts reading slowdowns.
- Trajectory error (how much the sentence’s “direction” changes) also predicts slowdowns.
- These two measures are almost independent of each other (they barely correlate), which means they capture different things.
- Garden-path sentences show strong trajectory effects:
- At the moment the sentence forces a re-interpretation (the “disambiguating” word), trajectory error jumps higher in the ambiguous versions than in the clear versions.
- This jump helps explain why readers slow down: it’s not just that the word is surprising—it’s that it flips the sentence’s direction.
- The effect shows up in normal stories too:
- Words that are not very surprising but bend the sentence’s direction still slow readers down.
- Words that are surprising but keep the direction going also slow readers down.
- This shows both “surprise” and “direction change” matter separately.
- It’s not just “big change,” it’s “wrong-way change”:
- A control test showed it’s not simply the size of the internal change in the model that matters. In one model family (GPT-2), big changes that continue the current direction can actually speed reading, while changes that break the direction slow it down. That supports the idea that direction matters, not just movement.
- In another model family (Pythia), this specific pattern differed (both types predicted in the same direction), but the main result—trajectory error matters beyond surprisal—still held.
- The effect is local and robust:
- The direction signal is very short-term: it mostly lasts over just the next word or so in the model’s internal states.
- The findings hold across different sizes of GPT-2 and across a different architecture (Pythia) that uses another way to track word positions. So the result isn’t a quirk of one model.
Why this matters: The study suggests reading difficulty comes from at least two sources:
- how surprising a word is, and
- how much it disrupts the recent flow of the sentence’s meaning.
What this could mean going forward
- For understanding the mind: People don’t just predict the next word; they also track the recent “direction” of the sentence’s meaning. A word that yanks the meaning off that path can be hard to integrate, even if it isn’t especially surprising.
- For building better AI: LLMs and writing tools might produce text that’s easier to read if they keep local “flow” smooth, not just pick probable words.
- For experiments: Future studies could design sentences where “surprisal” is the same but “trajectory change” differs (and vice versa) to test these ideas more directly. Brain measures (like EEG/MEG) could also check whether “trajectory error” shows up in neural responses.
A final simple takeaway
When you read, your mind doesn’t only ask “Was this word expected?” It also asks “Does this word keep the story moving in the same direction?” If the answer to either question is “no,” you’re likely to slow down—even more so if both are “no.” This paper shows both factors matter, and it gives a new way to measure the second one.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, articulated to guide concrete follow-up research.
- Modality and measurement sensitivity: The evidence relies on self-paced reading; it is unknown whether trajectory extrapolation error predicts eye-tracking measures (e.g., first-pass vs. re-reading) or neurophysiological responses (e.g., N400, P600) independently of surprisal and at what latencies.
- Causal disentanglement from surprisal: The study does not deploy stimuli explicitly matched on surprisal but differing in trajectory disruption (and vice versa); this leaves open whether the trajectory effect is fully independent of prediction error when tightly controlled.
- Generality across languages and modalities: All data are English reading; whether the effect holds in other languages (including morphologically rich or free-word-order languages) and in spoken comprehension remains untested.
- Individual differences and cognitive moderators: The models do not assess whether trajectory sensitivity varies with working memory capacity, reading proficiency, or bilingualism; random slopes for key predictors were not reported, limiting conclusions about generalizability across participants.
- Garden-path item limitations: The garden-path analysis uses only 24 items; by-item variance absorbs much of the trajectory signal, and item-level confounds cannot be ruled out without larger, better-controlled item sets or item-matched manipulations of trajectory.
- Model–measure coupling confound: Surprisal and trajectory measures are derived from the same underlying model in each analysis; cross-model analyses (e.g., surprisal from model A, trajectory from model B) are not reported, leaving open whether results depend on model-specific idiosyncrasies.
- Parameter selection and potential overfitting: The choice of layer and window size (e.g., 3-word windows, mid-layer) appears data-driven; systematic cross-validated hyperparameter selection or preregistered choices are not presented.
- Alternative trajectory features: Only linear extrapolation error (with limited tests of quadratic fits) was examined; curvature, angular change between successive displacement vectors, higher-order derivatives, or piecewise-linear models may capture trajectory violations more directly.
- Distance metric and geometry: Euclidean distance in high-dimensional, anisotropic spaces may be suboptimal; the paper does not test cosine distance, Mahalanobis distance, whitening of hidden states, or alignment across chunks/layers to ensure geometric comparability.
- Subword aggregation choices: The measure uses the last subword’s hidden state for each word; whether alternative pooling (e.g., mean/max over subwords or attention-weighted pooling) changes the effect is unknown.
- Chunking and context-boundary artifacts: Natural Stories were processed in overlapping windows due to context limits; the impact of chunk boundaries on hidden-state trajectories and extrapolation error is not quantified or controlled.
- Punctuation and clause-boundary confounds: The analysis does not explicitly control for punctuation or clause/sentence boundary positions, which likely induce large trajectory shifts independent of lexical predictability.
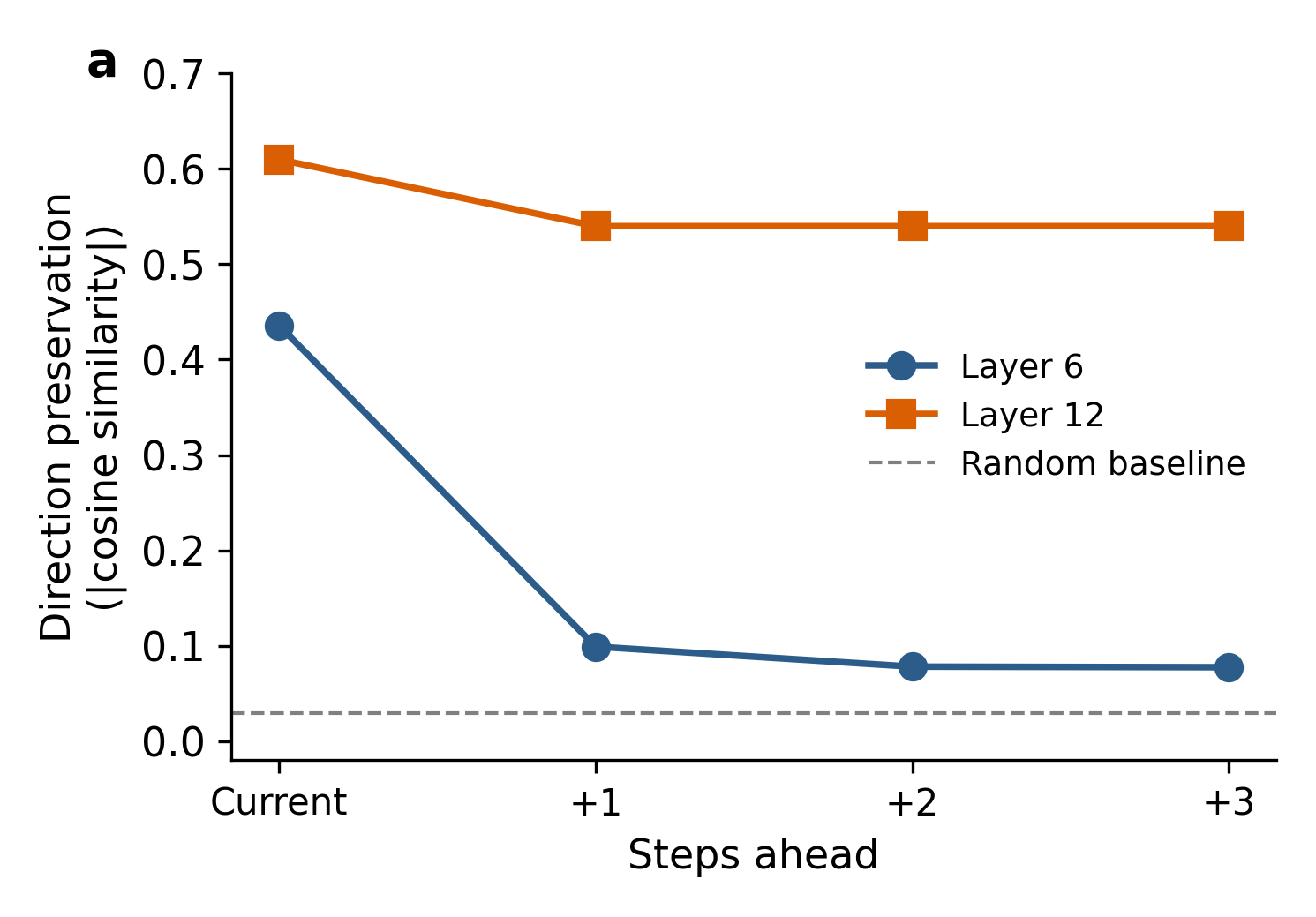
- Layer-wise dynamics and time scale: Direction preservation suggests short-horizon dynamics at mid-layers and long-horizon dynamics at final layers, yet only a few layers/windows were explored; a comprehensive layer-by-layer and window-size sweep (including 2-word windows) with rigorous model comparison is missing.
- Inconsistent displacement control across architectures: The opposite-sign dissociation between displacement and extrapolation error in GPT-2 but not Pythia is noted but not resolved; which representational geometric properties drive this divergence remains an open question.
- Statistical specification and robustness: The methods initially describe random intercepts for participants; a “fully crossed” structure is later claimed for Natural Stories without full detail (e.g., random slopes for surprisal/trajectory, by-item/by-story intercepts); robustness to alternative random-effects structures and outlier-robust estimation is not fully demonstrated.
- Effect size characterization: Improvements are reported via AIC/likelihood tests, but standardized effect sizes, partial R², and predictive cross-validation (e.g., held-out stories/participants) are not provided, limiting interpretability and practical significance.
- Domain and corpus generalization: The near-orthogonality of surprisal and trajectory (r ≈ .044) is shown for Natural Stories and Pythia variants; whether this holds across diverse genres (news, dialogues, technical text) or conversational data is unknown.
- Beyond garden paths: The theory predicts trajectory costs at broader syntactic/discourse phenomena (e.g., center-embedding, coordination, topic shifts), but these were not systematically tested beyond garden-path sentences.
- Mapping to production planning: The proposed link between a 3-word trajectory window and human production planning horizons is speculative; direct tests connecting production measures (e.g., planning scope in speech) to comprehension trajectory sensitivity are absent.
- Cross-architecture scope: Cross-architecture replication was conducted only on Natural Stories with Pythia; garden-path replications using RoPE-based models are not reported, limiting conclusions about architecture-general effects in controlled manipulations.
- Model scale and modern LLMs: Results are shown for GPT-2 Small/Medium/Large and Pythia up to 410M; whether the effect persists, strengthens, or changes with modern larger models (e.g., Llama, GPT-3-class) and with diverse training corpora is untested.
- Interaction forms and nonlinearity: The additive model outperforms an interaction for Natural Stories, but nonlinear or threshold interactions (e.g., trajectory costs only above certain surprisal/trajectory levels) are not explored.
- Neurocognitive mechanism: The paper posits representational reorientation costs but does not specify or test neural mechanisms (e.g., whether trajectory violations align with P600-like signals while surprisal aligns with N400-like signals).
- Human–model representational alignment: It is assumed that LM hidden states approximate human interpretive states; direct tests linking trajectory measures to neural representational geometry (RSA with fMRI/MEG/EEG) are not conducted.
- Tokenization/language specificity: The reliance on subword tokenization may interact with morphology; how trajectory extrapolation behaves in languages with rich morphology and different tokenization schemes is unknown.
- Experimental design for causality: No intervention manipulates trajectory independently of other factors (e.g., controlled insertion of connective phrases or syntactic frame shifts while holding lexical probability constant); concrete experimental designs are proposed but not executed.
- Practical applications to generation: The suggestion that preserving local trajectory coherence may improve human processing of generated text is untested; quantitative metrics for trajectory coherence and human evaluations of text fluency/readability are not provided.
- Code/data transparency: The paper does not specify public availability of code and processed measures to facilitate independent replication, sensitivity checks, and extensions.
Practical Applications
Immediate Applications
The following applications can be deployed today using open-weight transformer LMs (e.g., GPT‑2/Pythia) to compute trajectory extrapolation error from hidden states. Most require only inference-time access to model activations and modest engineering.
- Publishing and content creation (media, marketing, technical writing)
- Use case: Readability linter that flags “trajectory breaks” at the sentence/phrase level to reduce processing difficulty beyond what word-level predictability (surprisal) captures.
- Tool/product: An editor plugin (e.g., for Google Docs, MS Word, or CMS) that overlays a “trajectory deviation heatmap” and suggests rewrites to minimize extrapolation error without increasing surprisal.
- Assumptions/dependencies: Access to open LMs’ mid-layer hidden states; ability to batch process text; genre-appropriate tokenization.
- Conversational AI and customer support (software)
- Use case: Response re-ranking for chatbots to favor continuations with low cumulative trajectory deviation (smoother flow, easier to read).
- Tool/product: Decoding-time reranker that combines log-probability with a trajectory-continuity score computed over the last k tokens (e.g., k=3).
- Assumptions/dependencies: Ability to intercept candidate continuations; compute hidden states for each candidate; added latency budget.
- Newsletters, landing pages, and ad copy optimization (adtech/marketing)
- Use case: Predictive “friction points” that correlate with slower reading and higher drop-off; A/B test rewrites that lower extrapolation error.
- Workflow: Instrument content with a trajectory deviation profile; prioritize editorial changes where model predicts elevated processing cost.
- Assumptions/dependencies: No ground-truth RT needed; relies on the paper’s finding that the metric generalizes to naturalistic text.
- Legal, policy, and compliance communications (policy/enterprise)
- Use case: Garden-path detection and remediation—flag sentences likely to induce trajectory reversals (e.g., reduced relatives) and propose clearer alternatives.
- Tool/product: Plain-language checker that augments traditional readability scores with trajectory-disruption warnings.
- Assumptions/dependencies: Organization buy-in; domain dictionaries to preserve legal meaning while reducing trajectory error.
- Education and literacy (education)
- Use case: Authoring or adaptation of reading materials for early readers or language learners by minimizing local trajectory deviations while maintaining vocabulary targets.
- Tool/product: Curriculum design tool that scores passages and suggests substitutions/orderings to improve flow for a given grade level.
- Assumptions/dependencies: Grade-level and vocabulary constraints; open LMs suitable for the target language.
- Accessibility and neurodiversity support (healthcare/assistive tech)
- Use case: Reading simplification for dyslexia or cognitive impairments by reducing short-horizon disruptions that elevate cognitive load.
- Tool/product: Browser extension that rewrites high-extrapolation-error regions and optionally inserts micro-pauses or visual cues at unavoidable trajectory shifts.
- Assumptions/dependencies: Personalization and user testing; careful evaluation to avoid oversimplification.
- Machine translation post-editing (software/localization)
- Use case: Highlight MT segments where target-side trajectory deviates sharply from preceding context, signaling coherence issues despite high lexical adequacy.
- Workflow: Integrate trajectory-deviation flags in CAT tools for targeted human post-editing.
- Assumptions/dependencies: Hidden-state computation on target text; optional alignment to source for cross-lingual checks.
- Text-to-speech and voice design (speech technology)
- Use case: Prosody shaping—insert pauses or adjust intonation at predicted trajectory deviations to ease comprehension in audio.
- Tool/product: Prosody controller that maps extrapolation-error peaks to pause duration or pitch resets.
- Assumptions/dependencies: TTS engine with prosody control; evaluation for listener comfort.
- Academic experiment design and analysis (psycholinguistics/neuroscience)
- Use case: Stimulus control by matching surprisal while manipulating trajectory deviation, or vice versa; pre-register predicted RT/ERP effects.
- Tool/product: Open-source library to compute extrapolation error and generate balanced stimuli.
- Assumptions/dependencies: Open LMs; compatibility with experimental pipelines; cross-validation on in-lab measures.
- Quality assessment for model-generated text (AI evaluation)
- Use case: Report a “Trajectory Continuity Score” alongside perplexity to assess human-readability of LLM outputs.
- Workflow: Batch-score documents; track continuity trends across decoding strategies (e.g., nucleus sampling vs. beam with reranker).
- Assumptions/dependencies: Access to the same or comparable LMs for scoring; genre-specific baselining.
- Developer documentation and API guides (software)
- Use case: Identify sections where conceptual flow is disrupted and suggest reordering or connective scaffolding to maintain local continuity.
- Tool/product: Docs CI linter that fails builds on high trajectory-disruption thresholds in critical guides.
- Assumptions/dependencies: Integration into docs pipelines; domain glossaries.
- E-learning pacing and assessment (education/edtech)
- Use case: Predictive pacing—place comprehension checks or micro-summaries after high-deviation segments to reduce overload.
- Tool/product: LMS plugin that schedules interactions based on predicted load peaks.
- Assumptions/dependencies: Course structure metadata; privacy-compliant analytics.
- Editorial analytics dashboards (media)
- Use case: Section-level trajectory maps that correlate with scroll depth and dwell time to prioritize revisions.
- Tool/product: Dashboard with per-section extrapolation error and action suggestions.
- Assumptions/dependencies: Web analytics integration; content segmentation.
- Open-model–only workflows (engineering)
- Use case: Compute the metric with small open LMs when proprietary APIs don’t expose hidden states; use as a proxy to guide editing of text generated by closed models.
- Assumptions/dependencies: Acceptable proxy correlation; consistent tokenization between scoring and generation where possible.
Long-Term Applications
These applications require further research, engineering, or institutional adoption (e.g., retraining LMs, clinical validation, policy standardization).
- Trajectory-aware decoding and training (AI/ML)
- Use case: Incorporate trajectory continuity as an auxiliary objective or decoding constraint to produce text that reads more smoothly for humans.
- Product/workflow: Fine-tune models with a loss that penalizes abrupt mid-layer trajectory deviations, or apply a two-pass decoder (generate candidates, select by combined log-probability and continuity).
- Assumptions/dependencies: Training-time access; validation that continuity improves human outcomes without harming factuality/diversity.
- Model architecture innovations (AI/ML)
- Use case: Architectures that explicitly maintain short-horizon state continuity (e.g., local dynamical controllers, trajectory-regularized layers).
- Assumptions/dependencies: Benchmarks linking trajectory structure to human evaluation; compute resources; stability research.
- Clinical cognitive assessment (healthcare)
- Use case: Use trajectory deviation to design probes that isolate reorientation costs in reading; complement with EEG/MEG markers for diagnostics (e.g., aphasia, mTBI).
- Product/workflow: Digital reading tests with parametric manipulation of trajectory deviation at constant surprisal; brain–behavior correlation tools.
- Assumptions/dependencies: IRB-approved trials; normative datasets; cross-population validation.
- Adaptive readers and personalized accessibility (assistive tech/education)
- Use case: Real-time personalization that rewrites or re-chunks text based on an individual’s sensitivity to trajectory deviations.
- Product/workflow: Reader apps that learn user profiles and dynamically adjust sentence structure, connectives, and pacing.
- Assumptions/dependencies: On-device inference efficiency; privacy-preserving profiling; user acceptance.
- Government and industry readability standards (policy/standards)
- Use case: Update plain language guidelines to include local trajectory continuity, especially for critical communications (health, finance, safety).
- Product/workflow: Standardized “Trajectory Continuity Index” with thresholds per audience.
- Assumptions/dependencies: Broad empirical validation; multilingual generalization; stakeholder consensus.
- Multilingual and cross-genre generalization (global media/education)
- Use case: Validate and adapt the metric across languages and genres; build language-specific baselines and tools.
- Assumptions/dependencies: Open LMs/encoders per language; corpora with reading-time data; handling of morphology and tokenization.
- Simultaneous interpreting and live captioning (media/events)
- Use case: Pace control and segmentation guided by predicted trajectory disruptions to reduce listener load.
- Product/workflow: Interpreter-support HUD or captioning system that anticipates high-cost segments and adjusts chunking/pauses.
- Assumptions/dependencies: Real-time inference; integration with ASR/NMT; professional workflow trials.
- Speech synthesis and narration (speech technology)
- Use case: Prosody models trained to align emphasis and phrasing with predicted trajectory deviations for audiobooks, education, and screen readers.
- Assumptions/dependencies: Listener studies; alignment with content semantics to avoid unnatural prosody.
- Knowledge delivery in complex domains (enterprise/education)
- Use case: Auto-structuring of long-form explanations (e.g., onboarding, medical instructions) to maintain short-horizon continuity while introducing new concepts.
- Product/workflow: Authoring assistants that schedule definitions/examples at points minimizing trajectory disruption.
- Assumptions/dependencies: Domain ontologies; human-in-the-loop authoring.
- Content safety and misinformation mitigation (policy/platforms)
- Use case: Detect manipulative writing patterns that exploit trajectory breaks for rhetorical misdirection.
- Product/workflow: Risk scoring that combines rhetorical features with trajectory disruption patterns.
- Assumptions/dependencies: Ground-truth datasets; risk of false positives.
- Cognitive-friendly UI/UX for long-form reading (software)
- Use case: Interfaces that adapt pagination, headings, and previews around segments with high predicted reorientation cost.
- Product/workflow: Adaptive layout engines for e-readers and knowledge bases.
- Assumptions/dependencies: UI evaluation; device performance constraints.
- Data generation and evaluation for LLMs (AI/ML)
- Use case: Construct training corpora and evaluation sets stratified by trajectory deviation to stress-test human-readability and robustness.
- Product/workflow: Benchmarks that decouple surprisal from trajectory to diagnose models’ human-aligned processing.
- Assumptions/dependencies: Automated stimulus generation pipelines; community adoption.
Common Assumptions and Dependencies
- Hidden-state access: Immediate implementations rely on open models (e.g., GPT‑2/Pythia) to compute the metric. For closed APIs, use smaller open models as proxies or train lightweight encoders to predict trajectory deviation from text features.
- Computational overhead: Per-token linear fits over short windows (k≈3) are inexpensive but may require batching and caching for long documents or real-time applications.
- Domain calibration: Thresholds for “high” deviation may vary by genre, language, and audience; initial deployments should include human-in-the-loop tuning.
- Generalization: The paper’s evidence comes from self-paced reading; further validation on eye-tracking and listening tasks is advisable for high-stakes use (policy, clinical).
- Tokenization and representation geometry: Results depend on subword tokenization and the geometry of a model’s hidden space; cross-model consistency checks are recommended.
Glossary
- Absolute positional embeddings: A method of encoding token positions by adding learned position vectors to hidden states in transformer models. "Pythia (which uses Rotary Position Embeddings rather than the absolute positional embeddings of GPT-2)"
- Akaike Information Criterion (AIC): An information-theoretic metric for model comparison that estimates out-of-sample prediction error; lower is better. "Model comparisons were evaluated using the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), and likelihood ratio tests."
- Bayesian Information Criterion (BIC): A model selection criterion that imposes a stronger penalty for complexity than AIC; lower indicates better fit. "Model comparisons were evaluated using the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), and likelihood ratio tests."
- Cosine similarity: A measure of directional alignment between vectors based on the cosine of the angle between them. "we measured the absolute cosine similarity between the fitted trajectory direction (from the preceding words) and the actual displacement vector"
- Cross-Architecture Replication: Evaluating whether an effect holds across different model architectures. "Cross-Architecture Replication"
- Crossed random-effects model: A mixed-effects model with random effects crossing multiple grouping factors (e.g., participants and items). "the contribution of trajectory extrapolation error is further attenuated in a crossed random-effects model that includes by-item intercepts."
- Direction preservation: The extent to which the direction of representational change is maintained across steps in hidden-state trajectories. "we computed a direction preservation measure on the Natural Stories corpus."
- Direction-preservation analysis: An analysis quantifying how well the direction of change persists over subsequent steps. "A direction-preservation analysis on the Natural Stories corpus characterizes the temporal scale of the underlying trajectory structure in the model."
- Disambiguating word: The word that resolves a prior ambiguity in a sentence. "the disambiguating word and two subsequent spillover positions"
- Displacement (embedding displacement): The magnitude of one-step representational change between consecutive hidden states. "embedding displacement ()"
- Displacement Control: A control analysis testing whether effects reduce to representational change magnitude rather than trajectory deviation. "A displacement control shows the effect is not reducible to representational change magnitude"
- Euclidean distance: The straight-line distance between two vectors in a geometric space. "trajectory extrapolation error is defined as the Euclidean distance between the extrapolated and actual hidden states"
- Garden-path sentences: Sentences that lead the reader toward an initial misparse, later requiring reanalysis. "Garden-path sentences provide an intuitive illustration"
- GPT-2: A family of transformer LLMs used for next-token prediction and surprisal estimation. "We computed extrapolation error using GPT-2 (117M parameters; \citealp{radford2019})"
- Hidden state: The internal vector representation produced by a model at a given time step or token position. "Let denote the hidden-state vector at word position in a given layer of a transformer LLM."
- Likelihood ratio tests: Statistical tests comparing nested models by evaluating the ratio of their likelihoods. "Model comparisons were evaluated using the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), and likelihood ratio tests."
- Linear mixed-effects models: Regression models that include both fixed effects and random effects to account for hierarchical or grouped data. "We fit linear mixed-effects models predicting log-transformed reading times, with random intercepts for participants."
- Lossy-context surprisal: A framework where prediction is based on an imperfect, lossy representation of prior context rather than full context. "This framing connects to lossy-context surprisal \citep{futrell2020}, which proposes that comprehenders work with a lossy representation of context rather than a perfect one."
- Natural Stories corpus: A corpus of naturalistic narratives with associated human reading-time data used for psycholinguistic evaluation. "we used the Natural Stories corpus \citep{futrell2018}, which consists of 10 naturalistic narratives totaling approximately 10,000 words."
- NP/S ambiguity: A syntactic ambiguity where a noun phrase can be parsed as a direct object or the start of a sentential complement. "NP/S direct-object/sentential-complement (e.g., ``The suspect showed the file deserved more attention'')"
- NP/Z ambiguity: A syntactic ambiguity where a noun phrase may be analyzed as an object (transitive) or as a subject of a following clause (zero complement). "NP/Z transitive/intransitive (e.g., ``While the man hunted the deer ran into the woods'')."
- Ordinary least squares (OLS): A method for estimating linear models by minimizing the sum of squared residuals. "we fit a linear trajectory to the hidden states at positions through by ordinary least squares."
- Orthogonal (statistical usage): Having near-zero correlation, indicating independence between measures. "this measure is nearly orthogonal to surprisal ()"
- Perplexity: A measure of a LLM’s predictive performance; lower values indicate better prediction. "as LLMs grow larger and achieve lower perplexity, their surprisal estimates become worse predictors of human reading times"
- Positional encoding scheme: The method by which a transformer represents token positions (e.g., absolute embeddings, RoPE). "across architectures with different positional encoding schemes (GPT-2 vs.\ Pythia/RoPE)."
- Principal-component space: A lower-dimensional space obtained via principal component analysis, used here for visualization of high-dimensional states. "projected into a two-dimensional principal-component space for visualization."
- Pythia: A family of transformer LLMs that use RoPE positional encodings, used here for cross-architecture tests. "we replicated the Natural Stories analysis using Pythia models \citep{biderman2023}, which use Rotary Position Embeddings (RoPE)"
- Rotary Position Embeddings (RoPE): A positional encoding method that represents positions via rotations in vector space rather than additive embeddings. "which use Rotary Position Embeddings (RoPE), a fundamentally different approach that encodes position through rotation of the hidden-state vectors rather than through additive position embeddings."
- SAP Benchmark: A benchmark dataset for syntactic ambiguity processing in psycholinguistics. "the Classic Garden Path subset of the SAP Benchmark \citep{huang2024}, a large-scale syntactic ambiguity processing dataset."
- Self-paced reading: A behavioral paradigm where participants read text word-by-word at their own pace, yielding reaction times per word. "Surprisal has been remarkably successful as a predictor of reading times across self-paced reading"
- Spillover positions: Word positions following a critical word where processing difficulty often continues. "the disambiguating word and two subsequent spillover positions"
- Subword tokenization: A tokenization method that splits words into smaller subword units for modeling. "For sentences with subword tokenization, we used the hidden state at the last subword token of each word."
- Surprisal: The negative log-probability of a word given its context; a measure of prediction error. "Surprisal, the negative log probability of a word given its context, has been the dominant predictor of incremental processing cost."
- Surprisal scaling paradox: The empirical finding that larger, lower-perplexity models yield surprisal estimates that are worse predictors of human reading times. "a phenomenon known as the surprisal scaling paradox."
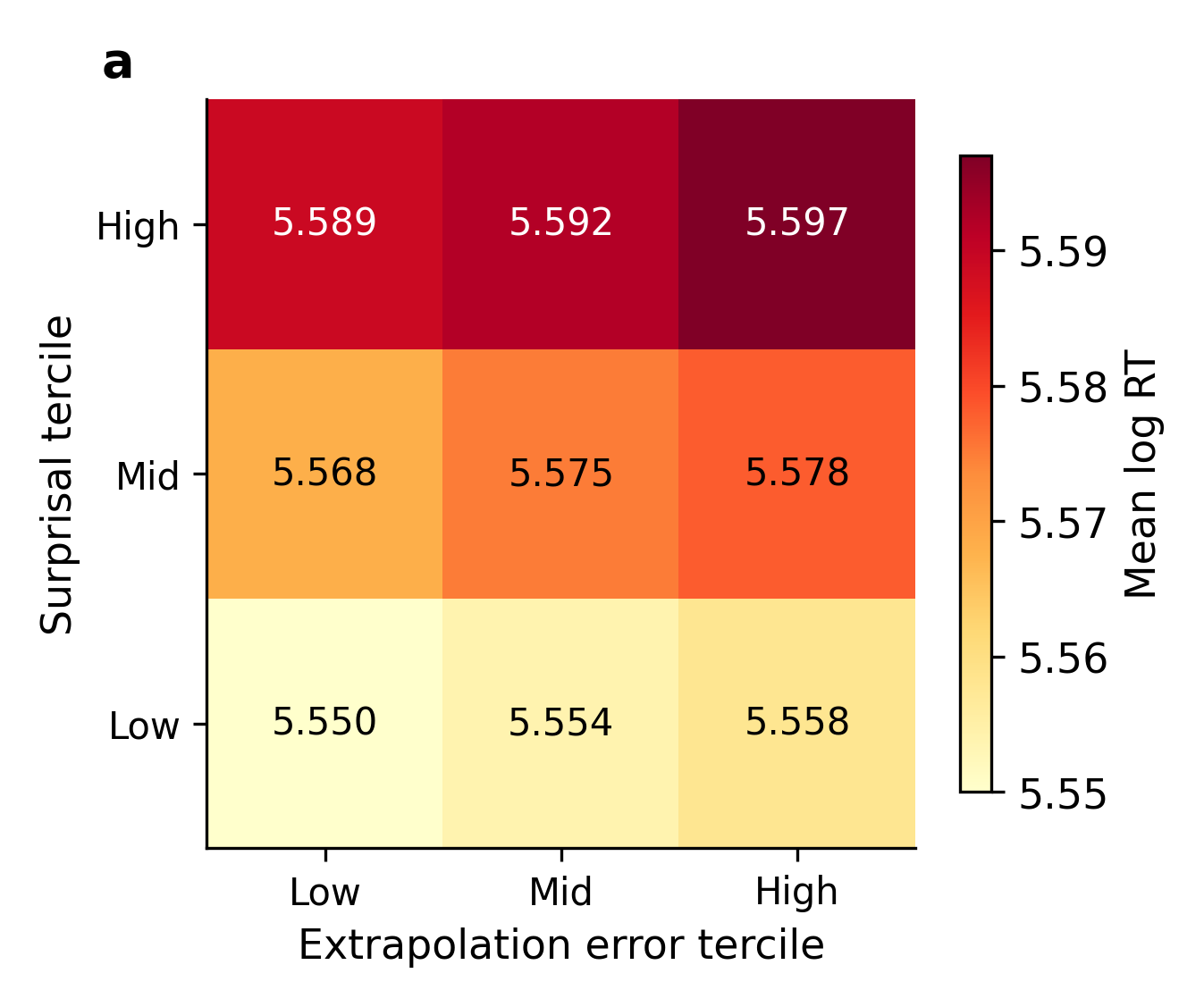
- Tercile: One of three equal-sized groups obtained by splitting a distribution into thirds. "We split words into terciles on both surprisal and extrapolation error"
- Trajectory extrapolation error: The deviation of the current hidden state from a linear extrapolation of recent hidden-state trajectories; indexes local continuity violations. "We introduce trajectory extrapolation error: at each word, we fit a linear trajectory to the preceding hidden states of a transformer LLM and measure deviation from the extrapolated path."
- z-scored: Standardizing variables by subtracting the mean and dividing by the standard deviation. "All continuous predictors were -scored prior to entry."
- Zipf score: A logarithmic measure of word frequency used as a psycholinguistic control. "log word frequency (Zipf score; standard psycholinguistic control, e.g., \citealp{smith2013})"
Collections
Sign up for free to add this paper to one or more collections.

