- The paper introduces a hybrid time-frequency diffusion framework that mitigates isotropic noise limitations by sequential noise injection in frequency and time domains.
- The methodology employs a dual-branch transformer with frequency-aware step embedding to adaptively refine both global trends and high-frequency components.
- Empirical results demonstrate up to an 8.9% reduction in MAE and 7.5% improvement in RMSE, outperforming prior state-of-the-art imputation models.
Hybrid Time-Frequency Diffusion with Frequency-Aware Embedding for Robust Time Series Imputation
Motivation and Limitations of Conventional Diffusion-Based Imputation
Diffusion models have demonstrated superior performance in generative modeling of time series, mainly due to their iterative denoising mechanisms. However, prior time-domain-only diffusion approaches (e.g., CSDI) are fundamentally limited by isotropic Gaussian noise injection, which induces uniform energy disturbance across all frequencies regardless of the highly skewed spectral statistics of real-world time series. Specifically, these models produce over-smoothed reconstructions, struggle to recover high-frequency local dynamics, and are insensitive to frequency structure, leading to systematic underestimation of mid/high-frequency components (Figure 1).
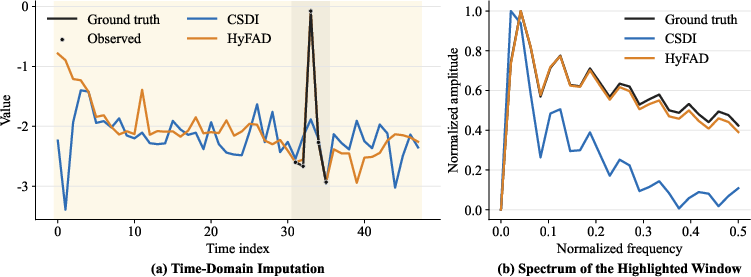
Figure 1: HyFAD corrects CSDI's spectral underestimation by better matching ground-truth sharp variations and spectral amplitudes in PhysioNet imputation.
HyFAD Architecture: Hybrid Time-Frequency Diffusion Design
HyFAD introduces a coupled time-frequency diffusion framework under the DDPM paradigm. The forward diffusion injects noise sequentially—first in the frequency domain, then in the time domain—mirrored by a reverse denoising process that removes time-domain noise followed by frequency-domain noise (Figure 2). Coarse global trends are stabilized via time-domain denoising, while high-frequency spectral components are progressively refined in the frequency domain, implementing a coarse-to-fine generative trajectory.
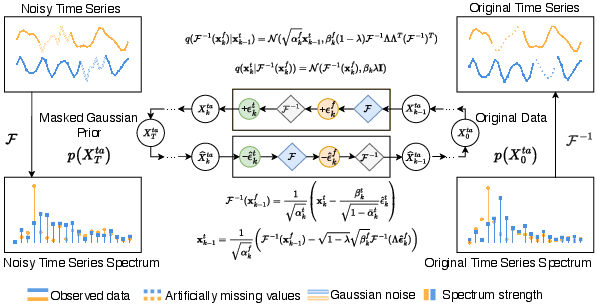
Figure 2: HyFAD’s forward/reverse process: frequency-domain noise precedes time-domain injection; reverse removes time noise before frequency.
Frequency-Aware Step Embedding: Spectral Guidance Across Diffusion Steps
Conventional step embeddings in diffusion models do not encode frequency-specific information. HyFAD’s frequency-aware embedding exploits the analytical relationship between diffusion steps and band-wise recoverability, derived from cumulative spectral energy and signal-to-noise ratios. Gating, scheduling, and reliability weights modulate the embedding, adaptively controlling emphasis of frequency bands depending on noise levels, denoising stage, and missing patterns. This guides the model to reflect progressive low-to-high frequency recovery observed in both theoretical diffusion dynamics and empirical data.
The HyFAD denoising network adopts a dual-branch transformer backbone (Figure 3), shared across time and frequency branches. The time-domain branch operates on temporal latents to reconstruct low-frequency structure, while the frequency-domain branch focuses on high-frequency refinement using frequency-aware embeddings. Both branches are coupled through residual connections and cross-transform projections, explicitly disentangling and re-integrating global and local dynamics.
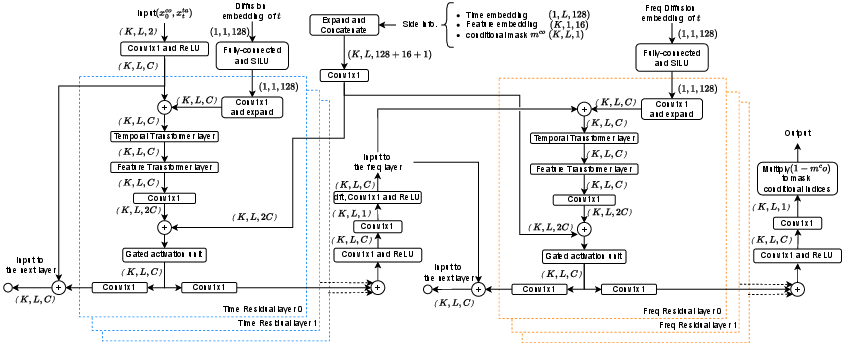
Figure 3: Denoising architecture with coupled dual-branch transformer, sharing structure but alternating embeddings for domain fidelity.
Empirical Evaluation: Quantitative and Visual Evidence
HyFAD achieves consistently superior performance across PhysioNet and Air Quality benchmarks under varying missing rates, reducing MAE and RMSE compared to deep learning and generative baselines, including ModernTCN, TimesNet, BRITS, GPVAE, CSDI, and LSCD. On PhysioNet, HyFAD reduces MAE by up to 8.9% and RMSE by up to 7.5% relative to LSCD (second-best), with statistically significant improvements across all experiments.
Qualitative visualizations underscore HyFAD's ability to preserve periodicity, recover sharp local features, and maintain spectral balance even under high missingness (Figures 4–7).
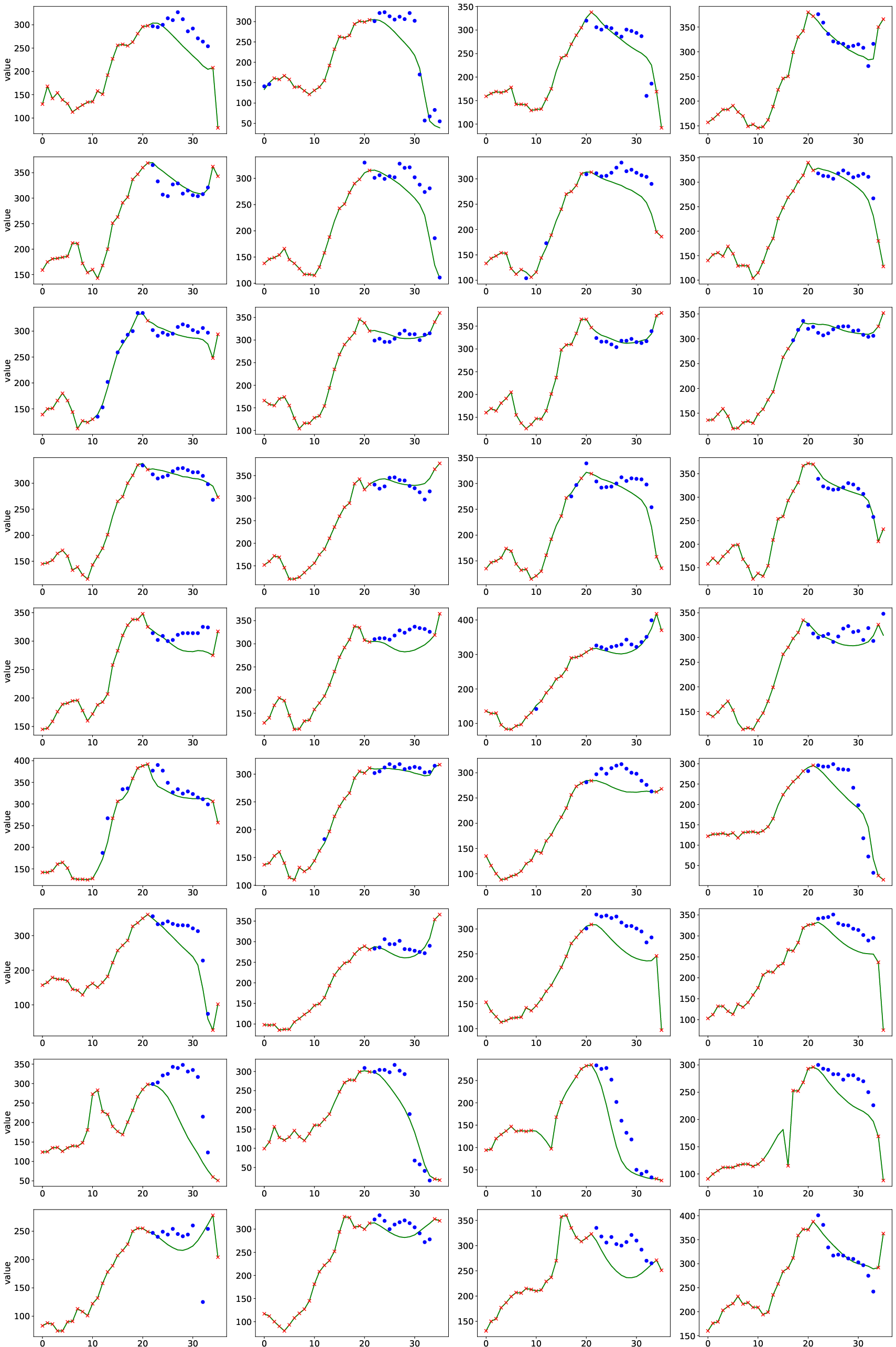
Figure 4: AQI imputation: solid line is prediction, blue is ground truth, red is observed; HyFAD maintains spectral coherence across channels.
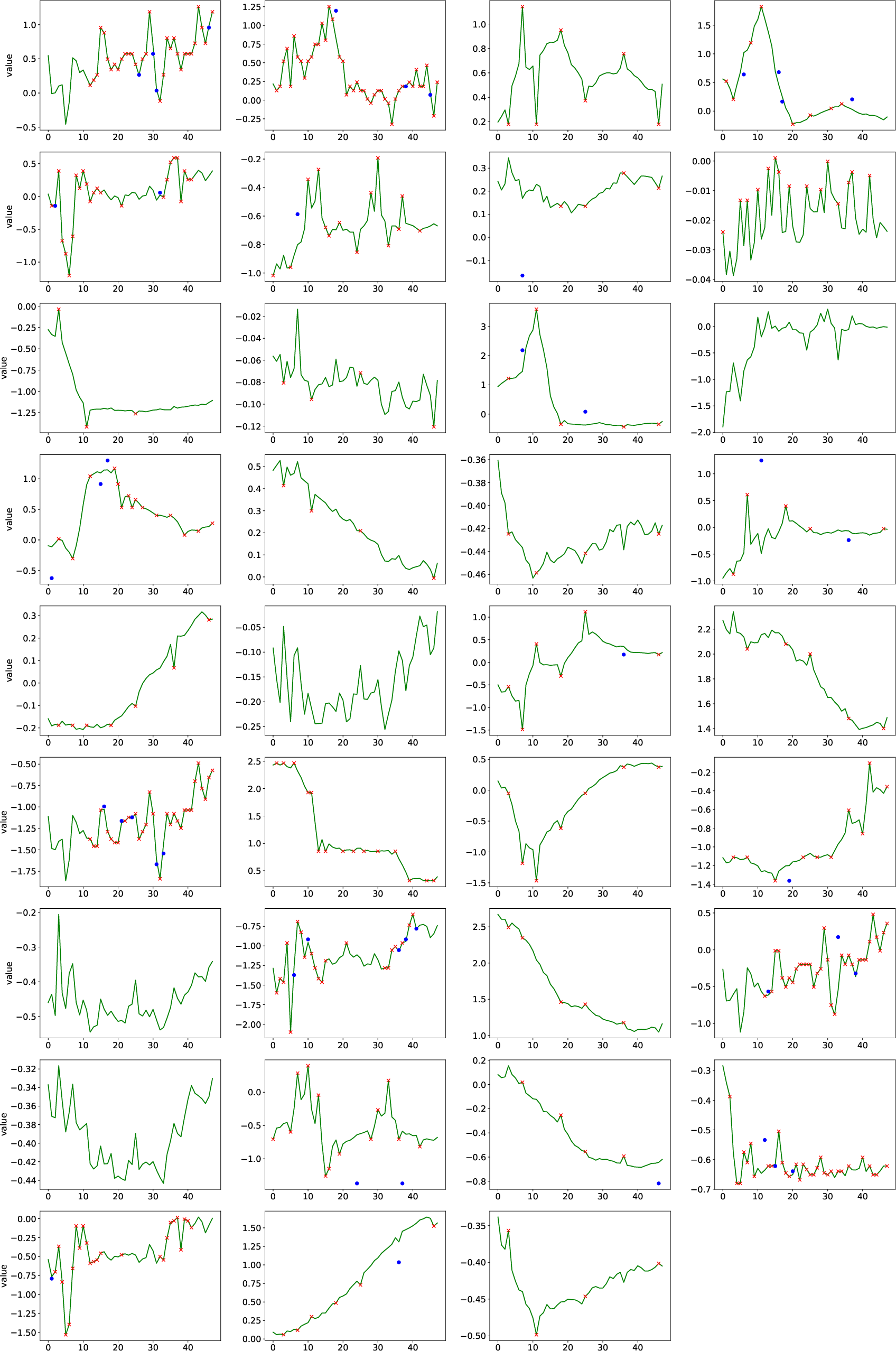
Figure 5: PhysioNet imputation (10% missing): HyFAD faithfully reconstructs local structure and global trend with minimal bias.
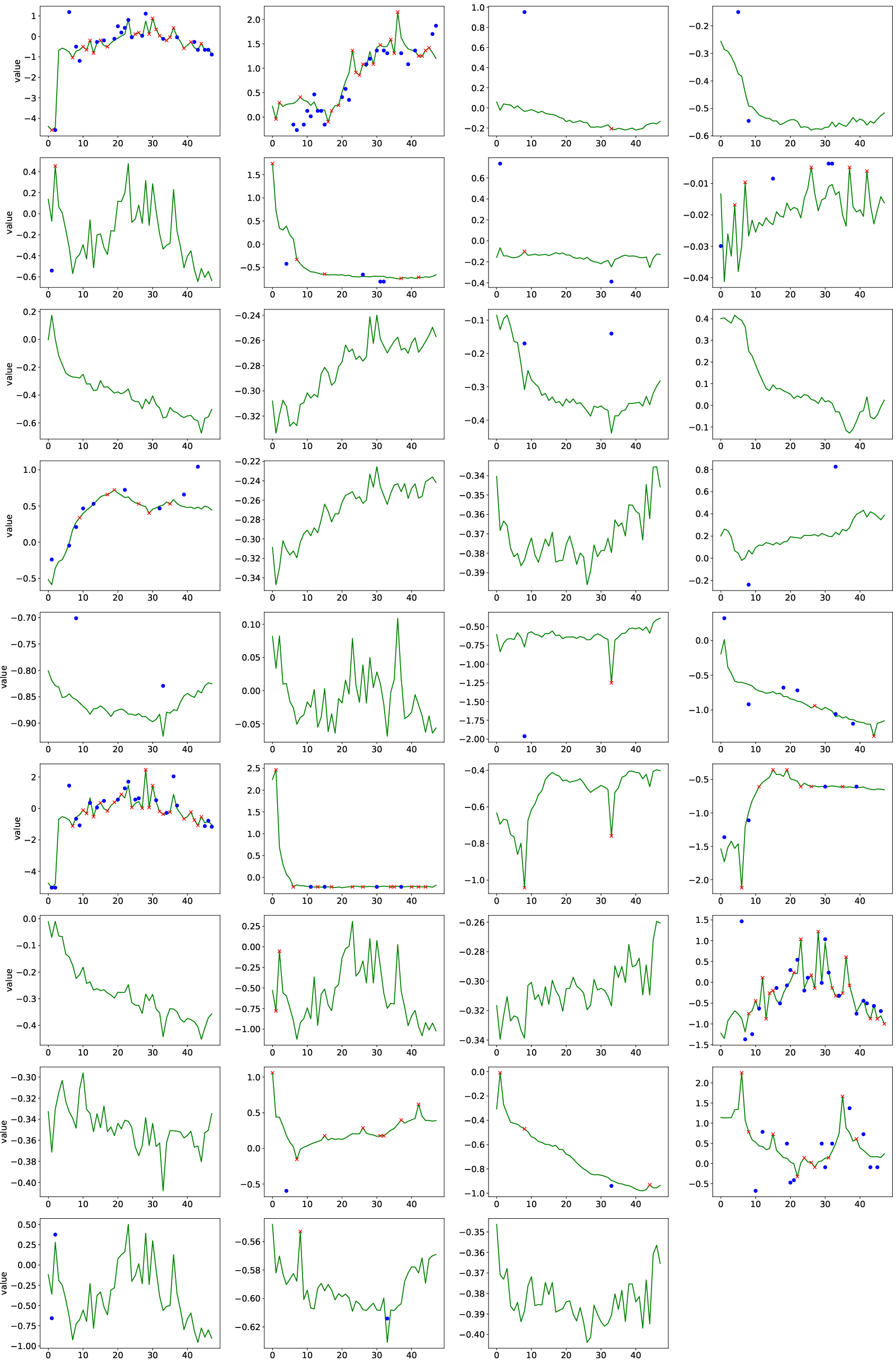
Figure 6: PhysioNet (50% missing): HyFAD retains high-frequency components and avoids over-smoothing under severe missingness.
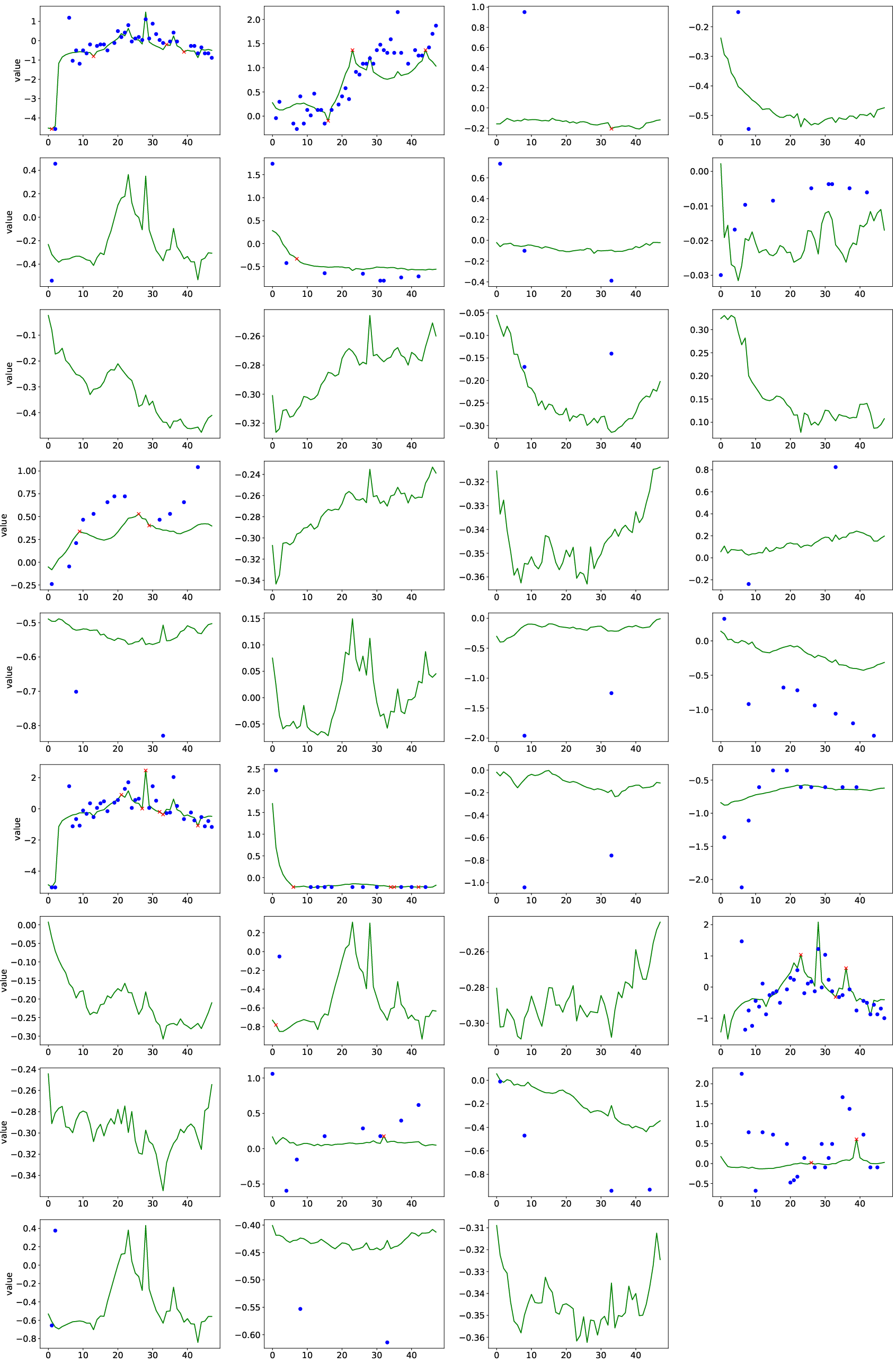
Figure 7: PhysioNet (90% missing): Even with extreme sparsity, HyFAD produces samples that match ground-truth spectral distribution.
Spectral-MAE, Log-SMAE, and Leading Frequency Error analyses confirm HyFAD’s explicit frequency-domain modeling improves reconstruction in middle and high-frequency bands where time-domain baselines fail.
Ablation and Parameter Sensitivity Analysis
Ablation studies show frequency-aware step embedding yields consistent gains over vanilla diffusion embedding. HyFAD's design—dominant temporal noise (λ=0.75), moderate temporal diffusion schedule, and tightly coupled objective—produces optimal recovery of both aggregate and spectral-based metrics. Excessive frequency-domain noise or weak temporal denoising degrades performance, reaffirming the necessity of hybrid composition.
Theoretical Foundations and Practical Implications
The fundamental insight is that, under isotropic noise injection, higher-frequency bands degrade faster than lower-frequency bands. Analytically, HyFAD’s frequency-aware embedding and coupled denoising are grounded in this relationship, resulting in adaptively prioritized spectral recovery.
Practically, this advances applications where accurate recovery of fine-grained local dynamics is crucial (e.g., healthcare monitoring, environmental sensing). The framework is extensible to alternate spectral transforms (e.g., DCT, wavelets), enabling broader applicability to heterogeneous time series modalities.
Computational Cost and Limitations
HyFAD incurs additional computational overhead in frequency-transform and dual-branch modeling. While inference latency increases modestly (training time per epoch ~3x that of CSDI), empirical gains warrant this for critical settings. Current limitations include reliance on DFT-based transformation and deterministic imputation; future exploration may extend to probabilistic sampling, alternate frequency bases, and improved stabilization for spectral-domain diffusion.
Conclusion
HyFAD establishes a hybrid time-frequency diffusion architecture that outperforms prior models in time series imputation, especially in preserving high-frequency and local structure. The frequency-aware diffusion embedding provides principled guidance for multi-scale reconstruction, shown to deliver statistically and spectrally superior results. This paradigm offers a trajectory for integrating spectral dynamics in generative models, with implications for robust imputation methodologies and broader generative time-series tasks.