Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
Abstract: Real-time vision demands models that are accurate, efficient, and simple to deploy across diverse hardware. The YOLO family has become widely deployed for this reason, yet most YOLO detectors still rely on non-maximum suppression at inference, carry heavy detection heads due to Distribution Focal Loss, require long training schedules, and can leave the smallest objects without positive label assignments. We present Ultralytics YOLO26, a unified real-time vision model family that addresses these limitations through coordinated architecture and training advances. YOLO26 uses a dual-head design for native NMS-free end-to-end inference and removes DFL entirely, yielding a lighter head with unconstrained regression range. Its training pipeline combines MuSGD, a hybrid Muon-SGD optimizer adapted from LLM training; Progressive Loss, which shifts supervision toward the inference-time head; and STAL, a label assignment strategy that guarantees positive coverage for small objects. Beyond detection, YOLO26 introduces task-specific head and loss designs for instance segmentation, pose estimation, and oriented detection, producing consistent gains across tasks and scales. The family spans five scales (n/s/m/l/x) and supports detection, instance segmentation, pose estimation, classification, and oriented detection in a single pipeline, with an open-vocabulary extension, YOLOE-26, for text-, visual-, and prompt-free inference. Across all scales, YOLO26 achieves 40.9-57.5 mAP on COCO at 1.7-11.8 ms T4 TensorRT latency, advancing the accuracy-latency Pareto front over prior real-time detectors, while YOLOE-26x reaches 40.6 AP on LVIS minival under text prompting. Code and models are available at https://github.com/ultralytics/ultralytics.














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Ultralytics YOLO26, a new family of fast computer vision models that can find and understand objects in images and video in real time. The models are designed to be both accurate and easy to run on many kinds of devices—from powerful servers to phones and small edge computers. YOLO26 works for several tasks (like object detection, instance segmentation, human pose estimation, and rotated boxes for aerial images) and can even handle “open-vocabulary” detection, where you can ask it to find new categories using text or example images.
What questions did the researchers ask?
The authors looked at four practical problems with many current real-time detectors (including older YOLO versions):
- Can we remove the extra “clean-up” step called NMS (non-maximum suppression) so the model can give final answers directly and faster?
- Can we make the prediction head smaller and simpler by removing a heavy module (DFL) without losing accuracy?
- Can we train the model faster and better by using smarter optimization and loss scheduling?
- Can we make sure tiny objects are not ignored during training?
They also asked: Can the same core design help with related tasks (segmenting object masks, estimating human keypoints, detecting rotated boxes) and with open-vocabulary detection?
How did they do it? (Methods in simple terms)
Think of the model like a camera app with two shooting modes, plus smarter training and task add‑ons.
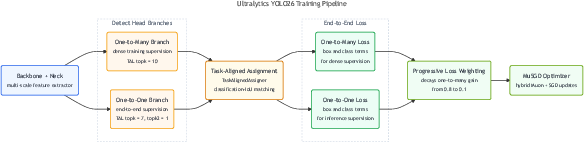
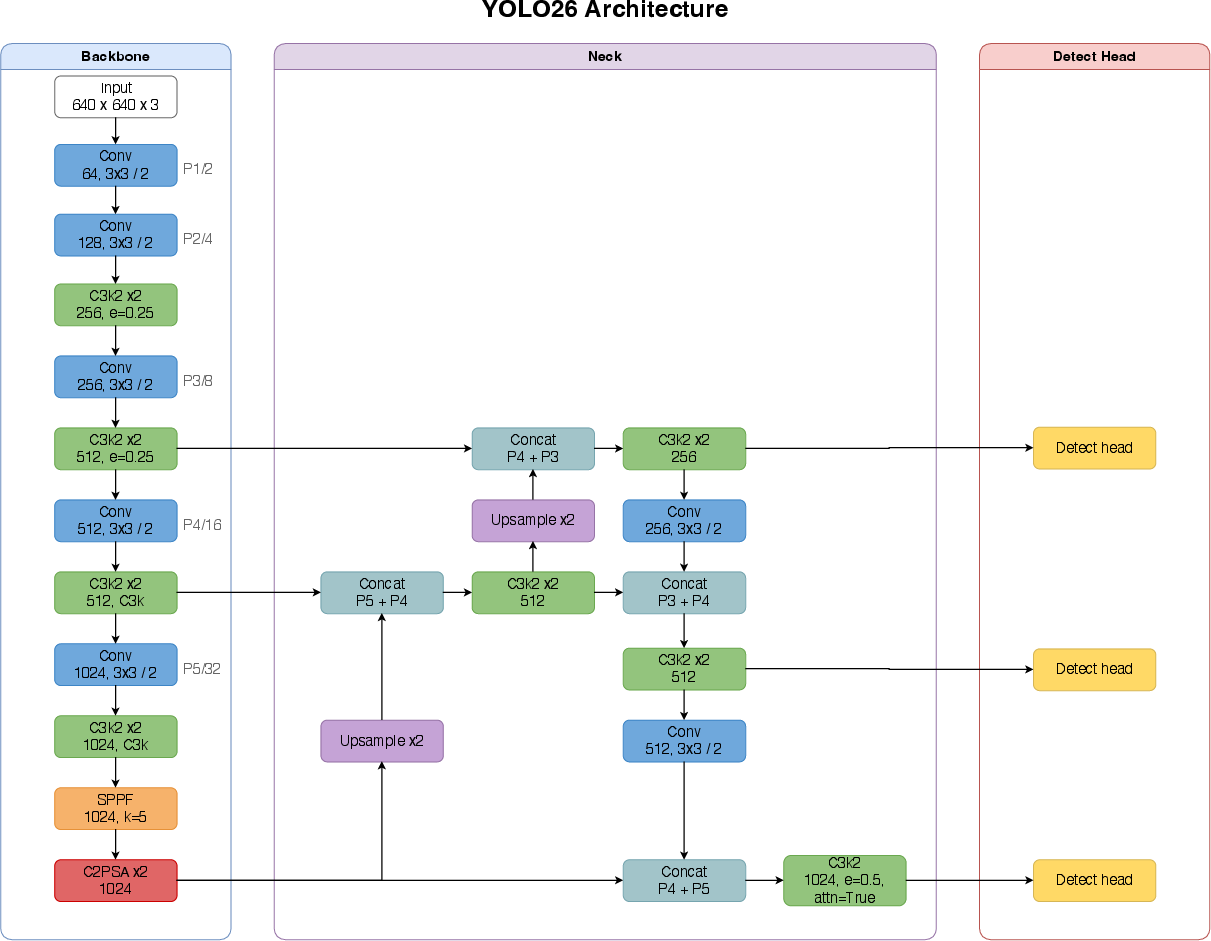
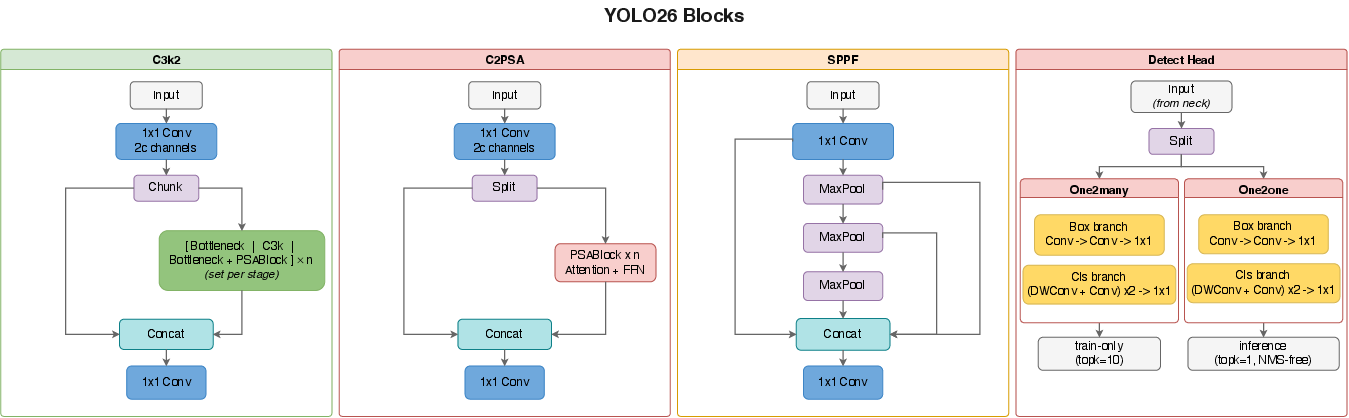
1) New model design: two “heads,” no NMS, no DFL
- Two heads (two ways of making predictions):
- One-to-one head: like a “best shot” mode that picks a limited number of final detections directly. This lets the model skip the NMS clean-up step and output final results immediately (faster and simpler).
- One-to-many head: like a “wide shot” mode that considers many options. It can be slightly more accurate if you can afford the extra NMS step at inference.
- No DFL (Distribution Focal Loss): DFL used to break box sizes into fixed bins, which made the head heavier and limited how large a box could be predicted at once. YOLO26 removes DFL and goes back to direct box regression—like switching from a ruler with fixed slots to a smooth tape measure. This makes the head smaller, faster, and removes artificial size limits.
2) Smarter training: MuSGD, Progressive Loss, and STAL
- MuSGD optimizer: a blend of two training styles (Muon and SGD). You can think of it as combining advice from two coaches—one that helps keep steps well-conditioned and steady, and one that is simple and robust—so learning is faster and more stable.
- Progressive Loss: early in training, the model leans on the “wide shot” head (easier, lots of hints); later, it shifts attention to the “best shot” head (the one used in fast, NMS-free inference). It’s like training wheels first, then riding solo.
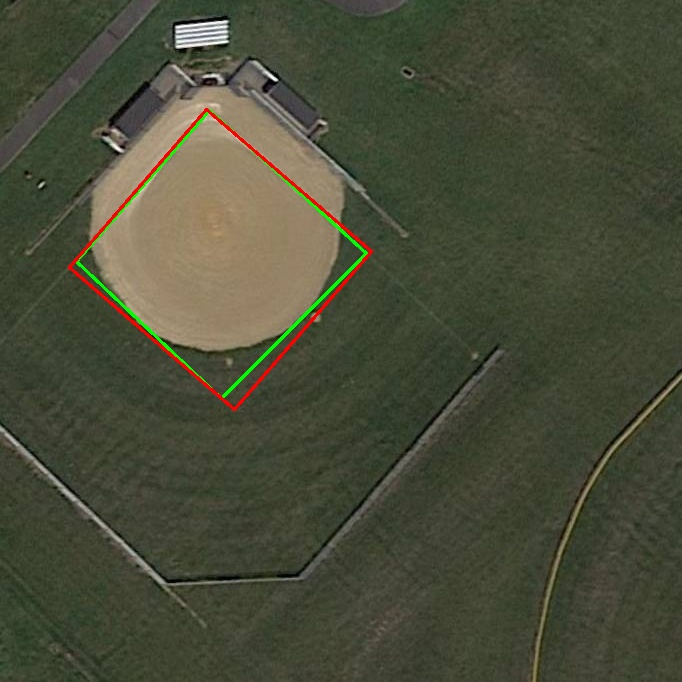
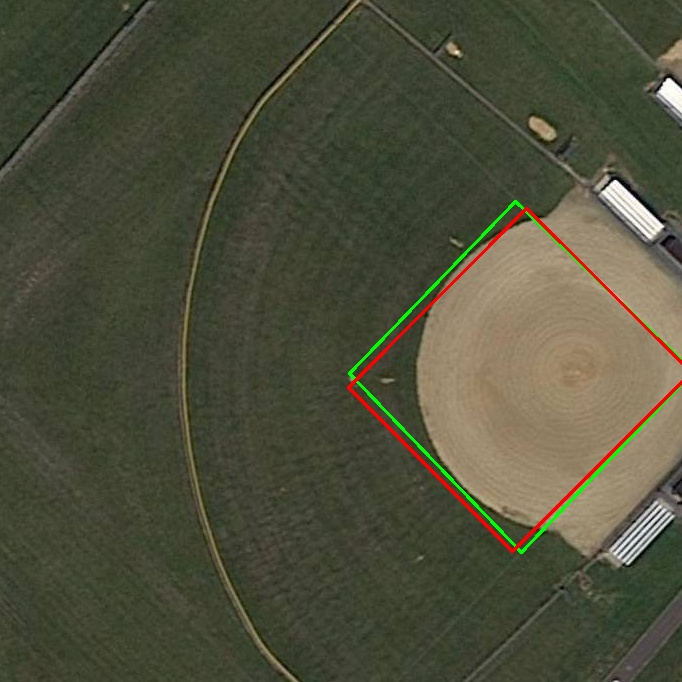
- STAL (Small-Target-Aware Label assignment): during training, tiny objects can slip through the cracks if no feature-cell center lands inside them after downscaling. STAL temporarily “pads” tiny objects for candidate selection so they get at least some positive matches. The model still learns the true box sizes; this just ensures small things aren’t ignored.
3) Extensions to other tasks
- Instance segmentation: still uses fast “prototypes + per-instance coefficients” (build each mask from shared base shapes), but now fuses features from multiple scales and adds a training-only semantic helper branch to improve mask quality without slowing inference.
- Pose estimation: lets the model estimate both keypoint positions and how sure it is about them (uncertainty). This helps it be more accurate and better calibrated, especially when joints are occluded.
- Oriented (rotated) detection: changes how angles are defined (always use the long edge for stability) and adds a special angle loss for square-ish objects, where rotation is ambiguous, to reduce confusion near angle boundaries.
4) Open-vocabulary detection: YOLOE-26
- Builds on YOLO26 to support three ways to find objects not seen in training:
- Text-prompted (describe what you want),
- Visual-prompted (show an example image),
- Prompt-free (no prompt, the model proposes categories).
- Uses a stronger detector backbone, an upgraded text encoder, and a better data pipeline to boost open-vocabulary performance.
What did they find? Why does it matter?
Here are the key results the authors highlight:
- Real-time accuracy vs. speed: On the COCO benchmark, YOLO26 models reach about 40.9–57.5 mAP while running in roughly 1.7–11.8 milliseconds on an NVIDIA T4 (TensorRT FP16). In simple terms, they’re both accurate and very fast, pushing the best-known trade-off for real-time systems.
- Better than prior YOLO versions: At the same model sizes, YOLO26 improves over YOLO11 by about +1.6 to +2.8 AP on COCO.
- Multi-task gains:
- Instance segmentation: up to +3.7 mask AP over YOLO11 on COCO.
- Pose estimation: up to +7.2 AP on COCO keypoints.
- Oriented detection: up to +3.4 mAP on DOTA-v1.0.
- Open-vocabulary: YOLOE-26x hits 40.6 AP on LVIS minival with text prompts, notably higher than some previous real-time approaches.
- Practical speed-ups: Removing DFL and simplifying the head cuts parameters and compute. The team reports up to 43% faster CPU inference for small models (e.g., YOLO26n vs. YOLO11n in ONNX) on a standard server CPU.
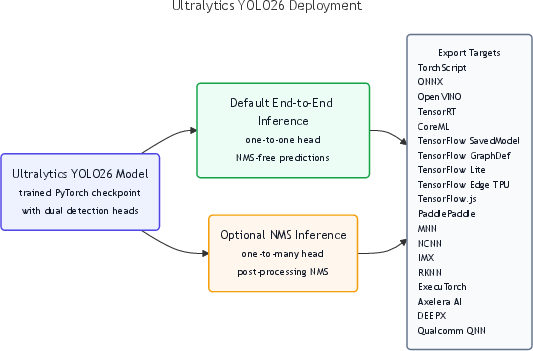
- Broad deployment: The models export cleanly to many formats (ONNX, TensorRT, CoreML, TFLite, OpenVINO, NCNN, and more), making them easy to run on different hardware.
Why it matters: These improvements mean you can run strong vision models on devices with tight speed and power limits (like drones, robots, cameras) without complicated post-processing or fragile custom operators.
What’s the bigger picture?
YOLO26 shows that careful design and training can deliver:
- End-to-end, NMS-free inference for speed and simplicity.
- Lighter, more flexible prediction heads (by dropping DFL) without giving up accuracy.
- Training that converges faster and treats tiny objects fairly (thanks to MuSGD, Progressive Loss, and STAL).
- A single, unified pipeline that works well across many vision tasks and device types.
- Open-vocabulary capabilities so models can find new categories using text or examples—useful for real-world scenarios where labels are not fixed.
In practice, this means better real-time vision for things like autonomous driving, robotics, AR, industrial inspection, and smart cameras—especially on edge hardware. It also lays groundwork for future models that are both highly capable and easy to deploy anywhere.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points capture what remains missing, uncertain, or unexplored, organized to guide follow-up research.
Detection architecture and training
- End-to-end, NMS-free capacity in crowded scenes: The one-to-one head outputs at most 300 detections per image; the impact of this cap on recall in dense/crowded datasets (e.g., CrowdHuman, WiderFace, aerial scenes) is not evaluated. How should the query count be tuned per dataset/scale without degrading latency?
- One-to-one matching sensitivity: The dual-path TAL settings (topk=7 then topk2=1 for one-to-one) are fixed without a sensitivity analysis. How robust are accuracy and convergence to these hyperparameters and to different matching rules (e.g., Hungarian, cost formulations)?
- Removal of DFL: While claimed to lighten the head and remove range limits, the precise effect on localization precision at high IoU thresholds (e.g., AP75, AP95), small- vs. large-object performance, and cross-resolution behavior (640 vs. 1280+) is not comprehensively reported. What regression loss and target parameterization replace DFL, and how do alternatives (e.g., GIoU/CIoU/EIoU/ProbIoU variants) compare?
- Progressive Loss schedule generality: The training reweighting scheme introduces new hyperparameters (α_init, α_final, schedule shape) with no systematic study of sensitivity or transferability across datasets, scales, and tasks. Are adaptive or data-driven schedules superior to a fixed linear schedule?
- Optimizer clarity and cost: MuSGD mixes Muon and SGD updates but leaves unspecified the mixing ratio, orthogonalization iterations, per-layer policies, compute/memory overhead, and interactions with mixed precision, gradient clipping, and large-batch training. What are the stability and speedup bounds vs. strong AdamW/SGD baselines under identical wall-clock budgets?
- Label-noise risks in STAL: Expanding tiny boxes to a reference size for candidate selection may admit off-object anchors, risking false positives and degraded precision. What are the precision–recall trade-offs, optimal s_ref per FPN level, and behaviors in extremely crowded tiny-object regimes?
- Cross-task applicability of STAL: STAL is introduced for detection; its impact on other heads (segmentation, pose, OBB) and on multi-task joint training is not evaluated. Does STAL require task-specific adaptations?
- Dual-head interference: Joint optimization of one-to-one and one-to-many heads can induce gradient conflicts. Are methods like loss/gradient balancing, decoupled optimization, or parameter partitioning beneficial? What is the added training memory/compute vs. single-head designs?
- Occlusion and overlap handling: One-to-one assignment inherently restricts duplicates per object; the paper does not analyze failure modes in heavy overlap/occlusion scenarios where DETR-like methods historically struggle. Can auxiliary duplicate handling or learned de-duplication improve crowded-scene recall?
Task-specific extensions
- Instance segmentation prototypes: The multi-scale proto module and auxiliary semantic branch add capacity and training signals, but the number of prototypes K, memory/latency overhead, and failure modes (e.g., thin/transparent structures) are not quantified. What is the accuracy–latency Pareto vs. single-scale prototypes, and does the auxiliary branch cause negative transfer to detection?
- Pose estimation with RLE: The RealNVP-based residual modeling introduces extra parameters and compute. The latency impact, convergence stability, calibration of predicted uncertainties, and robustness to occlusion and missing keypoints are not reported. How well does RLE transfer across datasets (COCO → CrowdPose/MPII) and edge devices?
- OBB angle supervision: The long-edge angle formulation and square-object angle loss hinge on λ and weighting design; there is no ablation on λ, behavior on extreme aspect ratios, or numerical stability of the modulo operation. How do these choices transfer to scene text datasets and higher-resolution aerial imagery?
Open-vocabulary (YOLOE-26)
- Modalities beyond text prompting: Results are reported for text-prompted LVIS minival; visual-prompted and prompt-free modes are not evaluated. How does performance vary across the three modes, and what calibration strategies mitigate false positives in prompt-free inference?
- Pseudo-label engine details: The data sources, scale, quality control, and potential label bias of the pseudo-label pipeline are not described, leaving open its contribution to gains and its risk of reinforcing dataset biases.
- Category bias and fairness: No analysis of performance across long-tail categories, demographic attributes, or sensitive labels is provided. How to mitigate bias amplification when coupling open-vocab heads with pseudo-labeled data?
- Segmentation decoupling: The benefit of “decoupled segmentation training” is asserted without a controlled comparison. Does decoupling improve open-vocab mask quality consistently, and what is the best coupling point with the detector?
Deployment and evaluation
- Backend coverage for E2E decoding: Some runtimes lack top-K ops and “fallback to non-E2E” inference; the accuracy and latency delta between the two paths post-export (e.g., TensorRT vs. CoreML vs. NCNN) is not quantified. What export-time transformations preserve E2E behavior across targets?
- Quantization and low-precision support: INT8/PTQ/QAT effects on the dual-head, E2E decoding, and non-standard losses (RLE, angle loss) are unexplored. Which layers are most sensitive, and what calibration schemes are needed?
- Energy and memory budgets: CPU and GPU latency are highlighted, but energy consumption, peak memory, and batch-size throughput on edge NPUs/SoCs (e.g., Qualcomm, Apple, Rockchip) are not reported. What are the deployment best practices per hardware class?
- Training efficiency claims: The paper motivates reducing long (≈600-epoch) schedules, but does not provide concrete new schedules, wall-clock time, or compute (GPU-hours) savings attributable to MuSGD and Progressive Loss at each scale. How do improvements scale with dataset size and augmentation strength?
- Generalization beyond COCO/DOTA: Most claims center on COCO (detection/segmentation/pose) and DOTA (OBB). Transfer to other domains (crowd, face, retail, industrial defects, medical, autonomous driving) and under domain shift (weather, nighttime, motion blur) is not evaluated.
- Confidence calibration: NMS-free decoding changes the score distribution; there is no analysis of calibration (ECE, reliability diagrams) or thresholding strategies for safety-critical deployments.
- Reproducibility specifics: Key training details are deferred (supplementary references, unspecified loss components, optimizer mixing), making exact reproduction difficult. Public configs with seeds, schedules, and hardware would reduce variance across reproductions.
Broader open questions
- Multi-task joint training: The family supports multiple tasks, but joint vs. per-task training strategies, task weighting, and interference are not examined. Can a single backbone jointly trained across tasks match or surpass per-task backbones under a fixed compute budget?
- Scaling laws and model size: The five scales (n/s/m/l/x) are reported, but scaling laws (data vs. model vs. compute) for accuracy and convergence under the new pipeline are not characterized. Where are diminishing returns, and how do optimizer/loss settings change with scale?
- Robustness and security: Sensitivity to corruptions, adversarial patterns, and spurious correlations is not studied. Which components (STAL, E2E head) most affect robustness, and what defenses are effective without sacrificing real-time constraints?
Practical Applications
Immediate Applications
The paper’s improvements to accuracy–latency trade-offs, end-to-end (NMS-free) inference, DFL-free lightweight heads, and broad export support enable a number of practical deployments today. Below are specific, actionable use cases, each noting relevant sectors, potential tools/workflows, and feasibility considerations.
- Edge AI cameras for real-time analytics
- Sectors: public safety/smart cities, retail, logistics, transportation hubs
- Tools/products/workflows: YOLO26 one-to-one (NMS-free) head on ONNX/OpenVINO/TensorRT; CPU-friendly ONNX deployments for low-cost NVRs; per-camera analytics (people/vehicle counting, face/helmet detection subject to local policy)
- Assumptions/dependencies: backend support for top-K ops in end-to-end decoding (or fallback to one-to-many+NMS); performance measured on NVIDIA T4 FP16—latency varies by device; privacy compliance for on-device analytics
- Warehouse and factory automation
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows: unified detection+instance segmentation for pick-and-place and bin-picking; OBB for rotated parcels; STAL improves tiny fasteners/defects recall; deployment via TensorRT/NCNN/RKNN
- Assumptions/dependencies: domain-specific fine-tuning; controlled lighting; conveyor synchronization; safety validation
- Drone and aerial analytics with oriented boxes
- Sectors: energy (powerline/solar inspection), agriculture, mapping/GIS, maritime
- Tools/products/workflows: OBB head with long-edge angle and aspect-ratio-aware angle loss for aircraft/vessels/solar panels; deployment on edge NPUs (RKNN, Qualcomm QNN)
- Assumptions/dependencies: high-res imagery; altitude/geo-calibration; domain data (DOTA-like) for fine-tuning; weather robustness
- Sports, fitness, and workplace ergonomics using pose
- Sectors: healthcare/wellness, sports tech, occupational safety, XR
- Tools/products/workflows: RLE-based uncertainty-aware keypoint regression for calibrated pose; mobile exports (CoreML/TFLite) for on-device coaching, fall/awkward posture alerts
- Assumptions/dependencies: camera placement/field of view; privacy approvals; task-specific OKS constants and tuning; clinical validation for medical-grade use
- Retail shelf monitoring and e-commerce visual search
- Sectors: retail, supply chain, marketing
- Tools/products/workflows: YOLO26 for planogram compliance (detection/segmentation); YOLOE-26 text-prompted/visual-prompted detection for long-tail SKUs without retraining; on-device inference with OpenVINO/CoreML
- Assumptions/dependencies: quality of text/visual prompts (MobileCLIP2); store-specific data; lighting/occlusions; handling false positives
- Industrial quality control and micro-defect detection
- Sectors: manufacturing (electronics, automotive, textiles)
- Tools/products/workflows: STAL ensures small-object assignment for tiny defects; instance segmentation for defect masking; CPU/GPU edge inference for inline QA
- Assumptions/dependencies: high-magnification imaging; strict false-negative requirements; periodic re-calibration
- Content creation and video editing
- Sectors: media/software, AR/VR
- Tools/products/workflows: multi-scale prototype segmentation for real-time cutouts, rotoscoping, and AR overlays in creator apps; plugins integrating ONNX/TensorRT
- Assumptions/dependencies: integration into NLE pipelines; memory bandwidth on consumer GPUs/CPUs
- Education and research acceleration
- Sectors: academia, training providers
- Tools/products/workflows: MuSGD for faster detector convergence; Progressive Loss for better end-to-end alignment; reproducible baselines across 19 export targets for coursework and lab assignments
- Assumptions/dependencies: availability of GPUs for training; dataset access/licensing
- Simplified MLOps and CI/CD for vision models
- Sectors: software/devops, platform engineering
- Tools/products/workflows: DFL removal and NMS-free head reduce custom post-processing; uniform exports (TensorRT, ONNX, OpenVINO, CoreML, TFLite, NCNN, ExecuTorch) streamline packaging and testing; automated latency/accuracy checks
- Assumptions/dependencies: backend-specific kernels; fallbacks when end-to-end decoding isn’t supported
- Smart home and IoT devices
- Sectors: consumer electronics, home security
- Tools/products/workflows: CPU-efficient YOLO26n/s for pet/package/person detection, doorbell cameras, and automation triggers; local-only analytics to reduce bandwidth and improve privacy
- Assumptions/dependencies: power/thermal constraints; model size targets; privacy regulations and user consent
- ADAS/prototyping for autonomous systems
- Sectors: automotive, robotics
- Tools/products/workflows: low-latency detection with improved tiny-object recall (e.g., distant signs/cones); NMS-free path simplifies embedded pipelines
- Assumptions/dependencies: not safety-certified; requires extensive validation and redundancy for production; environment variability
Long-Term Applications
The following opportunities require additional research, scaling, or ecosystem development before widespread deployment.
- Safety-certified end-to-end perception stacks
- Sectors: automotive, industrial robotics, aviation
- Tools/products/workflows: leveraging deterministic, NMS-free decoding to simplify safety cases; standardized verification harnesses; interpretable failure modes
- Assumptions/dependencies: formal methods and certification processes; robustness audits across corner cases; redundancy/fusion with other sensors
- Open-world perception and inventory of long-tail categories
- Sectors: retail, biodiversity/wildlife monitoring, media indexing
- Tools/products/workflows: YOLOE-26 prompt-free and text/visual-prompted detection for novel categories; pseudo-label data engines for continual enrichment; long-tail analytics dashboards
- Assumptions/dependencies: bias/hallucination mitigation; scalable human-in-the-loop verification; stronger multilingual text encoders; data governance
- Federated and on-device continual learning for vision
- Sectors: mobile/IoT, healthcare, smart cities
- Tools/products/workflows: efficient updates with MuSGD-inspired training on edge nodes; privacy-preserving aggregation; rapid adaptation to new environments
- Assumptions/dependencies: on-device training support and energy budgets; secure aggregation infrastructure; catastrophic forgetting safeguards
- Co-design with next-generation NPUs and compilers
- Sectors: semiconductor, embedded systems
- Tools/products/workflows: hardware specialization for NMS-free, DFL-free heads and dual-branch decoding; compiler passes that fuse top-K and detection heads; memory-aware prototype fusion
- Assumptions/dependencies: vendor collaboration; standardized operator sets; longevity of operator support across toolchains
- Clinical and rehabilitation applications of pose and segmentation
- Sectors: healthcare, eldercare, physical therapy
- Tools/products/workflows: uncertainty-aware pose for progress tracking and fall-risk assessment; instance segmentation for instrument/organ tracking in surgical video
- Assumptions/dependencies: rigorous clinical trials, regulatory approval (FDA/CE); domain adaptation to medical imagery; privacy and informed consent
- Infrastructure inspection at scale with oriented detection
- Sectors: energy, transportation, construction
- Tools/products/workflows: fleet-wide drone programs leveraging OBB for crack/corrosion and component orientation analysis; automated reporting pipelines with GIS integration
- Assumptions/dependencies: environmental robustness (glare, weather); standardization of acceptance criteria; integration with asset management systems
- Enterprise-grade auto-annotation and data curation
- Sectors: MLOps, data labeling services, enterprise AI
- Tools/products/workflows: YOLOE-26-driven pseudo-labeling to bootstrap rare classes; Progressive Loss and STAL-aware curricula for improved small-object coverage; active learning loops
- Assumptions/dependencies: quality thresholds and review tooling; bias control; scalable storage and lineage tracking
- Policy and procurement frameworks for on-device vision
- Sectors: public sector, critical infrastructure
- Tools/products/workflows: guidelines emphasizing on-device inference (privacy-by-design), AP–latency Pareto reporting, and export portability as procurement criteria
- Assumptions/dependencies: standardized test suites; alignment with privacy regulations (GDPR/CCPA); lifecycle security requirements
- Human–computer interaction and AR assistants
- Sectors: consumer tech, enterprise AR
- Tools/products/workflows: multi-task perception (detection, segmentation, pose) with open-vocabulary prompts for context-aware overlays in AR glasses and industrial assist tools
- Assumptions/dependencies: power-efficient on-headset inference; robust multi-user calibration; natural language grounding and latency constraints
- Agricultural pest and plant health monitoring at scale
- Sectors: agriculture, ag-tech platforms
- Tools/products/workflows: STAL-enhanced tiny pest detection; segmentation for leaf/fruit disease; drone/edge deployments across large farms
- Assumptions/dependencies: localized datasets for species/diseases; environmental variability; integration with farm management systems
Cross-cutting assumptions and dependencies
- Reported latencies rely on NVIDIA T4 + TensorRT FP16; performance varies across devices and export targets.
- Some runtimes lack native support for top-K ops used by end-to-end decoding; exports may fall back to one-to-many+NMS.
- Generalization beyond COCO/LVIS/DOTA requires domain-specific data and calibration; open-vocabulary performance depends on the text encoder (MobileCLIP2) and data quality.
- Safety-critical use demands extensive validation, redundancy, and compliance with sector-specific standards.
- Privacy, consent, and governance are essential for on-device analytics, especially in healthcare and public spaces.
Glossary
- Anchor-free: Detection paradigm that removes predefined anchor boxes and predicts objects directly at each location on feature maps. "Anchor-free designs such as FCOS~\cite{tian2019fcos} and Ultralytics YOLOv8~\cite{ultralytics2023yolov8} further simplified the detection head"
- Angle loss: A loss term added to stabilize orientation prediction, especially when object shapes make angles ambiguous. "To address this issue, an angle loss is specifically designed for square objects in YOLO26."
- AP (Average Precision): Precision averaged over recall thresholds for a single class or evaluation setting. "YOLOE-26x reaches 40.6~AP on LVIS minival under text prompting."
- Aspect-ratio-aware supervision: Training signal that weights orientation errors based on object aspect ratio to reduce ambiguity for square-like objects. "oriented detection (long-edge angle formulation with aspect-ratio-aware supervision)"
- BCE+Dice objective: Combined binary cross-entropy and Dice loss used for class-balanced segmentation training. "We supervise this branch with a balanced BCE+Dice objective, which provides dense class-aware gradients"
- Deformable attention: Sparse attention mechanism focusing on a small set of relevant sampling locations to improve efficiency and convergence in transformers. "deformable attention or other custom operators"
- DETR: Transformer-based detector framing detection as set prediction with one-to-one matching, removing anchors and NMS. "DETR~\cite{detr} cast detection as end-to-end set prediction"
- Distribution Focal Loss (DFL): Bounding-box regression scheme predicting discrete distributions over bins per side instead of direct scalars. "YOLO26 removes the Distribution Focal Loss (DFL) module from the detection head."
- Feature-pyramid stride: Spatial downsampling factor at each level of a feature pyramid used for multi-scale detection. "let denote the smallest feature-pyramid stride."
- Focal Loss: Loss that down-weights easy negatives to address class imbalance in dense detection. "RetinaNet addressed foreground--background imbalance via Focal Loss"
- Gaussian Wasserstein Distance (GWD): IoU surrogate measuring similarity between rotated boxes modelled as 2D Gaussians using Wasserstein distance. "Gaussian-based methods bypass the issue by modelling rotated boxes as 2D Gaussians and measuring similarity via Wasserstein distance (GWD~\cite{gwd2021})"
- GFLOPs: Giga floating-point operations, a measure of computational cost. "YOLO11n with DFL has 2.6M parameters and 6.5~GFLOPs"
- Hungarian matching: One-to-one assignment algorithm used to match predictions to ground-truth in set-based detectors. "Transformer-based detectors cast detection as end-to-end set prediction with one-to-one Hungarian matching"
- IoU (Intersection over Union): Overlap metric between predicted and ground-truth regions, commonly used for box regression losses. "remain primarily constrained by the rotated IoU loss."
- Kalman-filter-inspired IoU (KFIoU): IoU surrogate derived from Kalman filtering principles for rotated boxes. "a Kalman-filter-inspired IoU surrogate (KFIoU~\cite{kfiou2023})"
- Label assignment (Task-Aligned Learning, TAL): Strategy selecting positive samples based on combined classification and localization quality aligned to the task. "The Task-Aligned Learning (TAL)~\cite{feng2021tood} label-assignment strategy"
- Long-edge angle definition: OBB angle parameterization constraining width≥height and defining angle over a continuous range to reduce boundary ambiguity. "In YOLO26, the angle definition is changed to the long-edge definition following MMRotate~\cite{zhou2022mmrotate}"
- mAP (mean Average Precision): Mean of AP across classes (and sometimes IoU thresholds), the main detection benchmark metric. "YOLO26 achieves 40.9--57.5~mAP on COCO"
- MobileCLIP2: Lightweight text encoder used for vision-language tasks in open-vocabulary settings. "an upgraded text encoder (MobileCLIP2~\cite{mobileclip2})"
- MuSGD: Hybrid optimizer mixing Muon updates with SGD momentum for improved conditioning and convergence. "MuSGD, a hybrid Muon--SGD optimizer adapted from LLM training"
- Non-maximum suppression (NMS): Post-processing to remove duplicate detections by suppressing lower-scoring overlapping boxes. "Most CNN-based detectors still rely on non-maximum suppression at inference."
- Normalizing flow: Invertible generative model used to learn residual distributions for uncertainty-aware regression. "normalizing-flow-based probabilistic objective"
- Object Keypoint Similarity (OKS): Pose metric and training objective normalizing keypoint errors by object scale and keypoint-specific constants. "OKS-based training objective"
- Open-vocabulary: Ability to detect/segment categories not seen during closed-set training via language/vision embeddings. "Open-vocabulary detection methods can be broadly categorized"
- Oriented bounding box (OBB): Bounding box with rotation angle to better fit objects not aligned to image axes. "oriented bounding box (OBB) detection"
- Pareto front: Set of models that are non-dominated in accuracy vs. latency trade-offs. "advances the Pareto front over prior real-time detectors"
- ProbIoU: Probabilistic IoU-based loss that models localization uncertainty, used for rotated boxes. "the ProbIoU \cite{probiou2021} loss used in YOLO11 models becomes insensitive to angle variations"
- Progressive Loss: Curriculum-style loss reweighting that shifts emphasis from dense one-to-many to one-to-one head during training. "Progressive Loss, which shifts supervision toward the inference-time head"
- Prototype-based instance segmentation: Method reconstructing instance masks as linear combinations of shared mask prototypes with per-instance coefficients. "YOLO-style instance segmentation adopts a prototype-based representation"
- Pseudo-label: Automatically generated labels from models to supervise training without manual annotations. "a pseudo-label data engine"
- RealNVP: Specific normalizing flow architecture used to estimate log-density of residuals. "A shared RealNVP normalizing flow~\cite{dinh2017realnvp} estimates "
- RepRTA: Re-parameterizable Region-Text Alignment mechanism for aligning text prompts with regional features. "Re-parameterizable Region-Text Alignment (RepRTA) strategy~\cite{yoloe}"
- Residual Log-Likelihood Estimation (RLE): Probabilistic regression framework that learns residual distributions and per-axis uncertainties. "Residual Log-Likelihood Estimation (RLE)~\cite{rle2021}"
- STAL (Small-Target-Aware Label Assignment): Label assignment variant ensuring tiny objects always receive positive candidates. "STAL (Small-Target-Aware Label Assignment)"
- TensorRT FP16: NVIDIA inference backend and half-precision mode used to benchmark latency. "Latency is measured on an NVIDIA T4 GPU with TensorRT FP16."
- Top-K: Strategy selecting the K highest-scoring elements (e.g., proposals or candidates) during matching or decoding. "a two-stage top- proposal initialization variant"
Collections
Sign up for free to add this paper to one or more collections.