- The paper's main contribution is Slipstream, which leverages temporal locality in streaming embeddings to significantly reduce insertion costs for graph-based ANNS.
- Slipstream employs a proximity ratio and an adaptive controller to warm-start candidate searches, maintaining high recall while dramatically increasing throughput.
- Empirical evaluations on diverse video workloads show up to 30.8× faster insertion rates with negligible recall degradation, confirming its efficiency and scalability.
Slipstream: Locality-Aware Graph Index Construction for Streaming Approximate Nearest Neighbor Search
Introduction and Motivation
Continuous, ingestion-heavy vector streams—ubiquitous in domains such as video analytics, RAG, AI agent memory, and real-time recommendation—pose stringent efficiency demands on graph-based ANNS index construction. Existing methods, especially HNSW and its variants, incur high computational cost per insertion due to repeated neighbor searches from the global entry point. However, empirical analysis of embedding streams (notably in video data) reveals strong temporal locality, with consecutive embeddings residing in adjacent or even overlapping regions of the metric space.
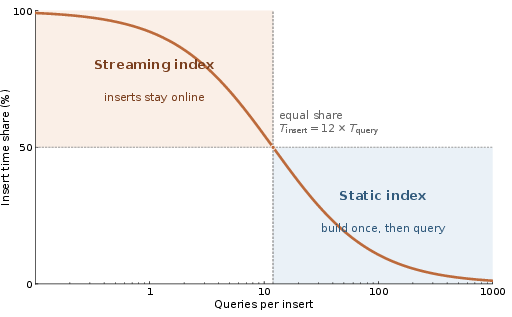
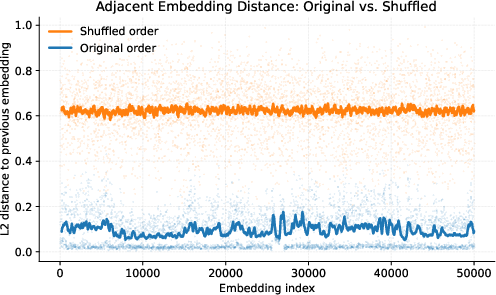
Figure 1: In index maintenance-intensive streaming workloads, the majority of online time is spent on repeated insertion; direct empirical analysis shows high temporal locality of consecutive embedding vectors.
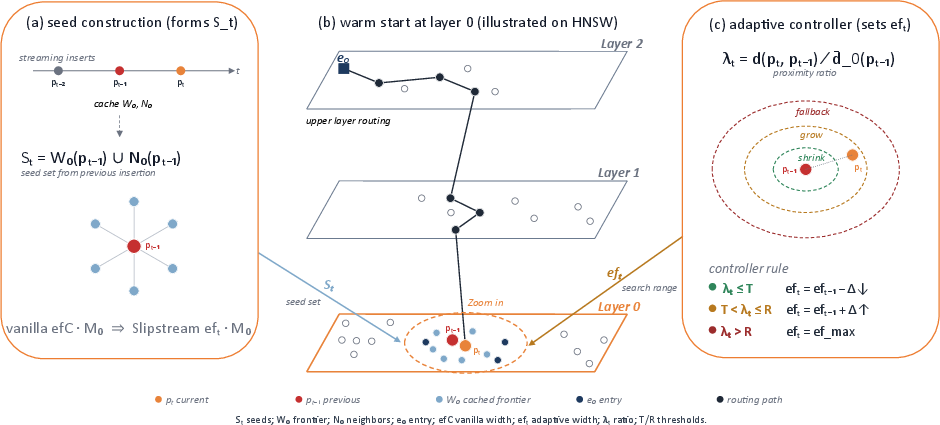
This observation motivates Slipstream, a method designed to exploit stream continuity for amortizing insertion cost. By caching and adaptively reusing promising candidate vertices from recent insertions, Slipstream introduces significant computational reductions in graph construction, all while retaining state-of-the-art query recall. The method departs from prior work by reframing insertion initialization: rather than restarting from a static or randomly chosen entry point, insertion proceeds from a dynamically maintained, locality-informed seed set, controlled by a statistical proximity ratio and an adaptive controller.
Methodology: Slipstream Index Construction
Pipeline Overview
Slipstream integrates with any graph-ANNS insertion pipeline that contains a candidate search phase (e.g., HNSW). The key innovation is the replacement of stateless, independent search initializations with a reuse mechanism underpinned by a locality-sensitive criterion. The insertion pipeline is restructured as follows:
Notably, all modifications are confined to the dense, cost-dominant bottom layer (layer 0) of HNSW, ensuring orthogonality with hierarchical routing and degree-riding mechanisms in upper layers.
Proximity Ratio and Fallback Policy
Slipstream's safety-critical criterion for cache reuse is the proximity ratio:
λt=dˉ0(pt−1)d(pt,pt−1)
where d(⋅,⋅) is the distance metric and dˉ0(⋅) is the mean distance to local neighborhood. When λt≤R (with R derived analytically from stream statistics), the cached candidates are deemed reliable; otherwise, the fallback discards the cache, and the insertion follows standard HNSW logic. The analytical underpinnings leverage an Erlang tail model for adaptive calibration of R.
Adaptive Controller
To further optimize insertion effort, an adaptive controller operates whenever cache reuse is permissible. The controller contracts or expands the insertion beamwidth (number of concurrent candidates) based on observed stream drift. Tuning is regulated by escalation and contraction steps, with a threshold T separating the "stable" (narrow) and "unstable" (wide) regions. The controller achieves a fine balance, ensuring robust recall while maximizing efficiency—converging to a predictable equilibrium governed by segment-level stream statistics.
Theoretical Guarantees
Slipstream's design is accompanied by a rigorous analytical framework:
Empirical Evaluation
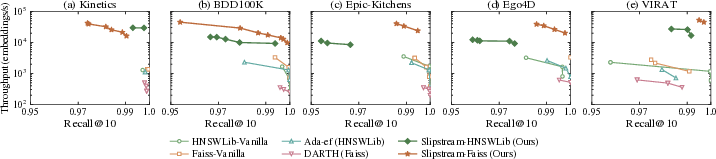
A comprehensive set of experiments evaluates Slipstream on five diverse streaming embedding workloads: Kinetics, BDD100K, Epic-Kitchens, Ego4D, and VIRAT, all utilizing CLIP-encoded frame embeddings. Slipstream is integrated into both HNSWLib and Faiss and benchmarked against four baselines: HNSWLib-Vanilla, Faiss-Vanilla, Ada-ef, and DARTH.
Throughput–Recall Tradeoff
Slipstream achieves substantial improvements in streaming throughput, with no material sacrifice in recall@10:
Runtime Decomposition
A breakdown of online latency confirms that Slipstream eliminates the insertion bottleneck—unlike Ada-ef and DARTH, whose adaptation mechanisms induce additional overhead via estimator recomputation and model retraining, respectively.
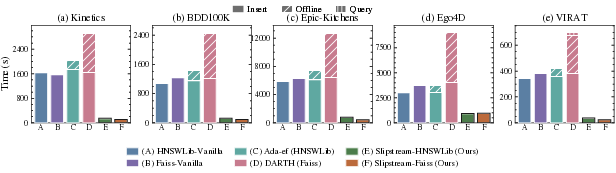
Figure 5: Operation time composition: Slipstream’s online runtime is dominated by efficient insertion, whereas adaptation-centric baselines pay substantial maintenance overheads.
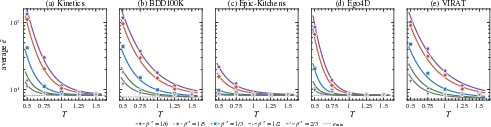
Sensitivity and Ablations
Parameter sweeps confirm the stability of Slipstream with respect to its core knobs: the choice of initial and minimum beamwidths, as well as the proximity and escalation thresholds, yields plateaued performance surfaces rather than narrow optima.
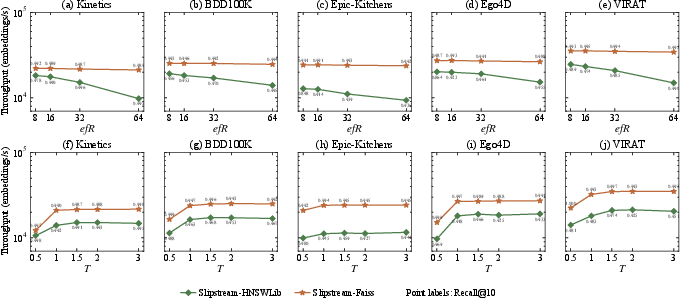
Figure 6: Streaming throughput and recall@10 are robust to wide ranges of Slipstream parameterization, consistent across all streaming workloads.
Ablation analysis identifies the fallback mechanism as the single most impactful contributor to throughput, followed by further gains from the adaptive controller. Memory analysis shows that Slipstream does not incur additional persistent space overhead.
Implications and Future Directions
The theoretical and empirical results in this work mandate a reconsideration of index construction in streaming scenarios. By exposing and capitalizing on temporal locality, Slipstream fundamentally changes the cost structure of online ANNS. This is directly applicable to RAG systems, long-form video analysis, adaptive agent memory, and real-time personalized search—settings where high insertion rates under high recall constraints are required and streams are locally structured. Slipstream’s minimal intrusive design enables compatibility with existing and future hierarchical graph-based indexes, facilitating rapid adoption in production vector databases.
Future research directions include generalizing locality-adaptive cache reuse to distributed or disk-based graph indexes, integration with active learning for automatic stream drift detection, and deep co-design with vector quantization/partitioning methods to further amplify throughput gains in ultra-large scale settings.
Conclusion
Slipstream introduces a novel paradigm in streaming ANNS index construction by systematically exploiting stream locality through proximity-aware cache reuse and adaptive control of insertion effort. It is analytically grounded, empirically validated across diverse workloads, and achieves up to an order-of-magnitude increase in streaming throughput at fixed recall—without requiring additional memory or sacrificing retrieval fidelity. This establishes a new standard for efficient, locality-aware streaming graph index construction for high-throughput, real-time vector search scenarios.