Policy-based Foveated Imaging and Perception
Abstract: Ultra-high-resolution image sensors offer the potential to capture fine spatial details critical for many visual perception tasks, but acquiring and processing all pixels at full resolution is often infeasible under realistic bandwidth, latency, and power constraints. Existing approaches address this challenge through acquisition strategies such as spatial or temporal downsampling, which irrevocably discard information before task relevance can be assessed. In this work, we introduce a real-time, predictive, and task-aware foveated imaging system that operates directly at image acquisition time. Leveraging emerging dual-stream sensor architectures, our method dynamically allocates limited pixel bandwidth to task-relevant regions of interest while maintaining a low-resolution global context. We formulate foveated acquisition as a sensor attention policy-learning problem, in which past observations guide actions that determine future measurements, closing the perception-acquisition loop. Through extensive simulation across multiple perception tasks, we demonstrate that our approach achieves high task performance under strict pixel budgets and significantly outperforms relevant baselines operating at the same bandwidth. We further validate our system on a 200-megapixel dual-stream sensor, capturing real-world videos under realistic bandwidth and latency constraints, demonstrating the practical feasibility of task-driven, acquisition-time foveated imaging.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making super high‑resolution cameras (think 200‑megapixel and beyond) smarter and faster. Instead of trying to capture every single pixel in full detail all the time—which is too slow, uses too much data, and drains power—the camera learns to “look” closely only at the most important parts of a scene. It keeps a low‑detail view of the whole scene and a high‑detail view of a small, important area at the same time. This idea is inspired by how your eyes work: your fovea sees a small spot in sharp detail while the rest is fuzzier.
What questions did the researchers ask?
The team focused on simple, practical questions:
- How can a camera decide, in real time, which parts of a scene deserve full detail?
- Can this smart “look‑where‑it‑matters” strategy keep tasks like tracking objects, reading text, or guiding a robot working well—even when the camera can’t send all its pixels?
- Can this be done on real hardware, not just in simulations?
How did they do it?
They used special “dual‑stream” sensors that can send two video streams at once:
- a low‑resolution, full‑scene view (like your whole field of vision),
- plus a high‑resolution close‑up of a small “Region of Interest” (ROI), whose position can change every frame.
Then they built a lightweight, real‑time system that decides where to place that high‑detail ROI next. Think of it as a three‑part team:
- A fast “saliency detector” (the scout): From the low‑res full view, it quickly suggests interesting spots (like a ball, a sign with text, or a robot gripper).
- A motion predictor (the guesser): It estimates where those spots will move in the next moment, so the camera can be ready before things happen.
- A selection policy (the planner): It chooses which spot to zoom into next, based on what’s most useful for the task. In the paper, “policy‑based” means the system learned rules that map what it saw before to smart choices about where to look next.
All of this runs as the camera is capturing, so the choice of where to look changes frame by frame.
What did they find?
The researchers tested their approach in simulations and on a real 200‑megapixel sensor. They compared it to common shortcuts like:
- shrinking every frame (spatial downsampling), or
- skipping frames (temporal downsampling).
Those shortcuts save data but blindly throw away important details. Here’s what they saw:
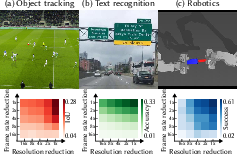
- Object tracking (like following a soccer ball): The ball is tiny and moves fast. Shrinking the whole image made the ball too blurry; skipping frames made it jump around. Their method kept a sharp view on the ball and matched or beat full‑resolution performance while using about 8 times fewer pixels.
- Reading text in road scenes: Signs and car text appear briefly and can be small. Shrinking blurred letters; skipping frames missed the right moment. The smart zoom focused on text at the right times and read more words correctly than the bandwidth‑matched baselines.
- Robotic manipulation (like inserting one object into another): Robots need both detail and fast feedback. Shrinking lost fine details; skipping frames delayed feedback. Their method kept key areas (like the gripper and contact points) sharp and responded quickly, leading to higher success rates than the baselines under the same pixel limits.
They also built a real prototype:
- A 200‑megapixel camera captured a low‑res full view plus a high‑res ROI at 30 frames per second.
- The system made decisions in real time and often read out only about 6% of the sensor area in full resolution each frame—saving a lot of data while keeping task‑critical details.
Why does this matter?
High‑resolution cameras are great for spotting small, important details, but they create huge amounts of data that are hard to move and process quickly—especially on devices like AR glasses, drones, or robots. This research shows that cameras can be “smart” at the moment of capture: they predict what matters next and spend their pixel budget there. The result is:
- better performance with far less data,
- lower latency (responses are faster),
- and lower power use.
In the future, this could make on‑device vision more reliable in cars, robots, medical tools, and wearable devices. The authors note some limits—surprising, one‑off events are harder to predict, and supporting multiple high‑detail areas at once is an open challenge—but the overall idea is strong: don’t just capture everything; capture the right things at the right time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes a modular, policy-based foveated acquisition pipeline and demonstrates strong results in simulation and qualitative real-world captures. However, several aspects remain under-specified, untested, or unexplored. The following list summarizes concrete gaps that future work could address:
Methodology and learning
- Training objective and supervision for the scanpath policy are unclear: how discrete ROI selections are learned end-to-end through non-differentiable cropping and task metrics (e.g., REINFORCE, Gumbel-Softmax, imitation from GT ROIs, or surrogate differentiable objectives) is not specified; sample efficiency and stability under sparse task rewards are not analyzed.
- Dependence on task-specific, fine-tuned saliency detectors limits generality; the paper does not evaluate zero-shot or cross-task transfer when detectors are not re-trained per task.
- No analysis of uncertainty-aware ROI planning: the policy does not explicitly model predictive uncertainty to adapt ROI size/margins or to trigger conservative/fail-safe allocations under ambiguity.
- Motion modeling is limited to constant-velocity Kalman filtering; the impact of non-linear dynamics, abrupt maneuvers, agent–agent interactions, and long occlusions on ROI prediction is not quantified, nor are alternatives (learned motion models, optical flow, interaction-aware trackers) evaluated.
- Scheduling across multiple concurrent targets is under-specified: the policy outputs a categorical choice per timestep, but there is no explicit budgeted optimization over multi-ROI assignment, ROI sizes, and temporal interleaving when many salient regions coexist.
- Hyperparameter sensitivity is unreported: effects of observation horizon (To), prediction horizon (Tp), receding-horizon execution window (Ta), and ROI margin/size on performance and latency are not ablated in the main text.
- Integration with downstream models is opaque: how dual streams (low-res context + high-res ROIs) are fused for each task (especially for models expecting single full frames such as DeepSolo) is not described, limiting reproducibility and interpretability of gains.
System and hardware constraints
- Multi-ROI support is limited: the prototype and method largely operate with a single ROI occupying a fixed fraction of the sensor; scalability to multiple simultaneous ROIs, variable ROI sizes/aspect ratios, and hierarchical (multi-scale) foveation is not demonstrated.
- Hardware actuation and readout constraints (ROI relocation latency, minimum dwell time, boundary tiling restrictions, exposure timing, rolling-shutter effects) are not quantified or modeled in the policy, leaving a gap between control decisions and feasible sensor operations.
- End-to-end latency and power budgets are not measured in the main paper: detailed breakdowns of sensing, inference, host–sensor communication, and readout overheads—and their variability under load—are missing, as are energy/thermal savings relative to non-foveated acquisition.
- Calibration between low-res FFoV and high-res ROI streams (geometric mapping, lens distortions, color/RAW-to-RGB processing) is not specified; misregistration could bias ROI placement in practice.
- Robustness to sensor artifacts (noise, HDR/high-contrast scenes, low light, motion blur, demosaicing choices) is not evaluated; the policy’s stability under these real-world degradations remains uncertain.
Evaluation and baselines
- Real-world evaluation is qualitative only; there are no quantitative metrics (e.g., tracking IoU, OCR accuracy) on hardware captures to verify that simulated gains transfer to deployed systems.
- Baseline comparisons omit adaptive or task-aware alternatives beyond uniform spatial/temporal downsampling (e.g., learned spatiotemporal sampling, RAM-style attention policies, compressive/coded acquisition, dynamic per-pixel binning); thus, the empirical advantage over stronger baselines is unestablished.
- Fairness of baseline metrics is partially ambiguous (e.g., IoU for temporal downsampling computed only on kept frames); sensitivity analyses with alternative evaluation protocols are not provided.
- Generalization under domain shift is untested: policies trained in simulation are not quantitatively validated on real-world data with different statistics, lighting, or motion patterns.
- Limited task breadth: only three tasks are considered; tasks requiring extensive global context (e.g., scene-level reasoning, multi-agent interactions) or long-term temporal dependencies are not evaluated.
Robustness, safety, and reliability
- Failure modes are not characterized: how often salient events are missed, how quickly the policy recovers after missed detections/occlusions, and the impact of detector false negatives on downstream tasks are not reported.
- No fail-safe mechanisms are described (e.g., fallback to wider ROIs or full-frame capture under high uncertainty, watchdog triggers for rare/safety-critical events), which is important for deployment in robotics and autonomous systems.
- Bias and coverage risks: prioritizing high-confidence detections may systematically de-prioritize small/low-contrast or rare objects; the paper does not analyze coverage guarantees or bias mitigation strategies.
Formalization and theory
- No principled budgeted optimization or guarantees: the scanpath selection is not framed as an explicit constrained optimization over pixel throughput, nor are there regret or performance bounds relative to oracle policies.
- Information-theoretic perspectives (e.g., mutual information between measurements and task outputs under a pixel budget) are not explored; such analyses could guide principled allocation and policy design.
Extensions and applicability
- Applicability to sensors without dual-stream ROI hardware (or to alternative modalities like event cameras, depth, or multi-camera rigs) is discussed only at a high level; concrete adaptations and experiments are absent.
- Dynamic ROI shapes and non-rectangular sampling patterns (e.g., radial profiles, content-adaptive binning) are not explored; these may better match sensor/readout constraints and task needs.
- Language/visual-prompt conditioning is mentioned but not empirically validated; the system’s ability to follow high-level task instructions or switch objectives on-the-fly remains an open question.
- Integration with closed-loop robotic systems beyond simulation (physical manipulation with end-to-end task metrics) is not demonstrated; real-world control performance under foveated sensing is unquantified.
Practical Applications
Overview
Below are actionable, real-world applications of policy-based foveated imaging, organized by immediacy. Each item names target sectors, concrete tools/products/workflows that could emerge, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Sports broadcast and analytics camera pipelines
- Sectors: media, sports tech, software
- What: Dual-stream broadcast cameras that keep low-res full-field video while ROI streams track balls/players/referees for highlights, offside lines, and tactical analysis; reduced uplink bandwidth from stadiums; near-real-time telestration tools driven by ROI crops
- Tools/products: Foveated Camera SDK for broadcast switchers; “Ball/Player Focus” plugin for sports analytics suites; encoder that prioritizes ROI tiles
- Assumptions/dependencies: Availability of dual-stream, programmable-ROI sensors; sub-30 ms end-to-end control latency; integration with existing production switchers/encoders
- Traffic sign and license plate OCR in ADAS/dashcams
- Sectors: automotive, mapping, mobility
- What: Edge OCR that foveates on briefly visible signs/plates while maintaining global scene context; improved transcription under bandwidth constraints
- Tools/products: In-vehicle foveated capture module for ADAS SoCs; map data enrichment pipeline for fleet vehicles
- Assumptions/dependencies: Dual-stream support in automotive-grade sensors; robust OCR models on ROI crops; compliance with privacy regulations
- Industrial robotic workcells (pick-place, insertion)
- Sectors: robotics, manufacturing
- What: Vision loops that keep high-res attention on gripper/object interfaces for precise alignment while preserving low-latency context for safety; better success rates at lower sensor throughput
- Tools/products: PLC-compatible “Foveation Node” for robot vision; URCap/ROS 2 packages integrating the policy with manipulation policies
- Assumptions/dependencies: Deterministic latency budgets; stable illumination; calibrations for camera–robot extrinsics; limited number of concurrent ROIs
- Warehouse scanning and parcel sortation
- Sectors: logistics, retail
- What: ROI focus on barcodes, labels, damage points; higher read rates with fewer pixels and lower illumination requirements
- Tools/products: Foveated scanner head retrofits; WMS integration to request task-conditioned ROIs (e.g., prioritize fragile labels)
- Assumptions/dependencies: Barcode/label detector performance on downsampled context; conveyor speed and ROI reposition latency constraints
- UAV/drone inspection and mapping
- Sectors: energy, construction, agriculture
- What: Allocate full-res to defects (cracks, hotspots), crop health indicators, or utility insulator hardware while maintaining global navigation context at low resolution
- Tools/products: On-drone foveated imaging middleware for Nvidia Jetson-class compute; ROI-first photogrammetry pipeline
- Assumptions/dependencies: Reliable dual-stream over MIPI and constrained radio links; stable ROI prediction under motion/rolling shutter; wind-induced dynamics handled by motion model
- Smart city cameras and VMS optimization
- Sectors: public sector, security, urban tech
- What: Reduce backhaul by streaming low-res global feed plus high-res ROIs on events (pedestrians crossing, near-collisions); supports edge analytics while minimizing PII exposure
- Tools/products: VMS plugin to store high-res ROI only on policy triggers; event-driven ROI encoders
- Assumptions/dependencies: Policy configuration for safety outcomes; privacy governance; reliable on-pole compute or NVR acceleration
- Smartphone “Smart ROI Video” mode
- Sectors: consumer electronics, mobile software
- What: Live video mode that dynamically sharpens faces, pets, text, or sports objects and saves ROI as enhancement layers; improves zoomed clarity without full-sensor readout
- Tools/products: Camera app feature; OEM firmware module for dual-stream sensors (e.g., 200 MP class)
- Assumptions/dependencies: OEM sensor firmware exposing ROI; thermal/power budgets; cooperation with ISP stack
- AR remote assistance and telepresence
- Sectors: enterprise software, field service
- What: Head-worn or phone-based capture that keeps high-res ROI on tools, connectors, serial numbers while streaming low-res scene context; lower uplink with better task fidelity
- Tools/products: Foveated WebRTC encoder; remote pointer-to-ROI workflow for expert operators
- Assumptions/dependencies: ROI metadata signaling in RTC; on-device policy runtime; dual-stream from AR camera modules
- Retail shelf monitoring and planogram compliance
- Sectors: retail, CPG
- What: High-res ROIs on price tags, brand logos, promo compliance; faster audits with partial frames
- Tools/products: Store camera firmware upgrade; analytics backend expecting ROI+context frames
- Assumptions/dependencies: Tag/brand detectors trained on low-res context; camera placement; multi-ROI limits
- Telepathology slide pre-screening (macroscopy level)
- Sectors: healthcare (non-diagnostic support), lab automation
- What: Foveate on regions with potential abnormalities for triage or QA, lowering scan time while preserving diagnostically relevant areas for later full scans
- Tools/products: Slide scanner pre-screen module; LIS integration for triage flags
- Assumptions/dependencies: Regulatory boundaries (support vs. diagnosis); careful validation; sensor supports programmable ROI scan paths
- Streaming/encoding optimization for cloud vision APIs
- Sectors: software, AI platforms
- What: Client-side foveation to reduce upload size while maintaining accuracy for downstream detection/recognition APIs
- Tools/products: SDK that wraps capture + ROI-aware video codecs; server-side API extensions accepting ROI+context inputs
- Assumptions/dependencies: Codec support for ROI priority; consistent end-to-end timestamping of streams
- Privacy-by-design camera configurations
- Sectors: policy, compliance, enterprise IT
- What: Default to low-res global capture; high-res ROI only on explicit triggers (badges, safety events); reduces inadvertent PII capture
- Tools/products: Governance templates; audit logs tied to ROI triggers; DPA-compliant configurations
- Assumptions/dependencies: Clear trigger policies; stakeholder buy-in; auditability of foveation decisions
Long-Term Applications
- Autonomous driving production stacks with foveated sensing
- Sectors: automotive
- What: Full integration of acquisition-time policies into sensor fusion and planning stacks to prioritize small hazards (debris, animals) under bandwidth/power constraints
- Tools/products: ASIL-compliant foveation controllers; simulation-in-the-loop validation
- Assumptions/dependencies: Safety certification; redundancy/failover when policy misallocates ROIs; multi-sensor coordination
- Multi-ROI, hierarchical foveation sensors
- Sectors: semiconductor, imaging
- What: Next-gen sensors supporting dozens of concurrent ROIs with variable frame rates; on-sensor policy execution
- Tools/products: Sensor IP blocks for ROI schedulers; programmable scan controllers
- Assumptions/dependencies: Vendor roadmap; MIPI/CSI extensions for ROI metadata; power-area trade-offs
- Satellite and HAPS remote sensing with selective readout
- Sectors: aerospace, climate, defense
- What: Constellations that capture low-res wide swaths plus high-res ROIs on ships, vehicles, or wildfire fronts to respect downlink budgets
- Tools/products: Task-aware downlink schedulers; ROI-aware ground processing
- Assumptions/dependencies: Pointing constraints; long latency links; physics-informed motion models
- Surgical and micro-robotics vision
- Sectors: healthcare, medical devices
- What: Foveated endoscopes/microscopes that maintain high-res at the tool–tissue interface while keeping global situational context
- Tools/products: Real-time, surgeon-in-the-loop ROI policies; integrated OR video systems
- Assumptions/dependencies: Clinical validation; sterility and safety standards; deterministic latency
- Smart glasses with fully on-device policy and streaming
- Sectors: consumer AR, accessibility
- What: Always-on text/face/object assistance with ultra-low power by foveating acquisition; narration for low-vision users
- Tools/products: Low-power policy accelerators; privacy-preserving on-device models
- Assumptions/dependencies: Battery life; ambient compute budgets; robust low-light performance
- Collaborative multi-camera foveation in factories/warehouses
- Sectors: robotics, IoT
- What: Cameras coordinate ROIs to avoid redundant high-res readouts and cover multiple points of interest
- Tools/products: Edge orchestration service; ROI scheduling protocol across cameras
- Assumptions/dependencies: Time sync; standardized ROI APIs; network QoS
- Foveated video codecs and standards
- Sectors: standards bodies, telecom
- What: New profiles that treat ROI tiles as primary enhancement layers; metadata for predictive ROI signaling end-to-end
- Tools/products: ROI-aware AV1/H.266 modes; RTP extensions; standards proposals
- Assumptions/dependencies: Industry adoption; interoperability testing
- Wildlife and behavioral science at scale
- Sectors: academia, conservation
- What: Long-duration monitoring with low-res habitat context and high-res ROIs on rare events (feeding, predation, tagging)
- Tools/products: Solar-powered foveated camera traps; event-driven data management
- Assumptions/dependencies: On-device robustness; sparse-event policy tuning; extreme environments
- Medical imaging pre-acquisition triage beyond slides (e.g., portable ultrasound)
- Sectors: healthcare
- What: Probe guidance that allocates higher sampling to suspected pathologies while keeping coarse context
- Tools/products: Foveated sampling sequences; operator feedback UIs
- Assumptions/dependencies: Regulatory approval; hardware co-design; clinician workflow integration
- Data minimization policies for public deployments
- Sectors: policy, governance
- What: Regulatory frameworks that incentivize acquisition-time data minimization (ROI-only high-res) for public cameras
- Tools/products: Compliance checklists; certification schemes
- Assumptions/dependencies: Legible audit trails; agreed definitions of “task-relevant” ROI; civil society engagement
- Foundation-model-aware foveation
- Sectors: AI platforms, software
- What: Policies conditioned by large vision-LLMs to prioritize semantically rich ROIs for downstream reasoning under limited pixels
- Tools/products: VLM-conditioned attention policies; prompts-to-foveation APIs
- Assumptions/dependencies: Efficient small-footprint VLMs; latency constraints; robustness to prompt ambiguity
- Edge-to-cloud ROI marketplaces for bandwidth trading
- Sectors: telecom, cloud
- What: Dynamic pricing where devices “buy” bandwidth bursts to send more ROIs during rare critical events
- Tools/products: Network APIs exposing ROI priority lanes; SLA monitoring
- Assumptions/dependencies: Network slicing; billing systems; fairness and abuse prevention
Cross-Cutting Assumptions and Dependencies
- Hardware availability: Dual-stream, programmable-ROI sensors (e.g., 200 MP class) or equivalents; firmware exposing ROI controls; support for multiple ROIs per frame in future devices.
- Real-time constraints: The policy must execute within tight deadlines; ROI reposition latency and rolling shutter effects must be modeled; reliable timestamping across FFoV and ROI streams.
- Model readiness: Lightweight saliency/motion modules trained per task; compatibility with downstream perception models expecting ROI+context inputs.
- Environmental robustness: Variable lighting, motion blur, occlusions; tasks with highly stochastic events reduce benefits of prediction.
- Power and thermal budgets: Especially on mobile/AR/UAV devices; may require hardware acceleration or low-power variants of the policy.
- Privacy and governance: Clear trigger policies, audit logs of ROI decisions, and compliance with local data protection rules when capturing high-res ROIs.
- Integration costs: ISP/driver changes, codec/streaming updates, and middleware to synchronize ROI metadata through existing pipelines.
These applications leverage the paper’s central innovations—acquisition-time, policy-driven foveation with demonstrated 30 fps operation on a 200 MP dual-stream sensor and consistent downstream task gains under 6–16× pixel budget reductions—to unlock practical deployments today and to guide sensor, systems, and policy co-design for future platforms.
Glossary
- Active SLAM: A variant of Simultaneous Localization and Mapping where the agent plans sensing actions to gather informative observations. "active SLAM systems"
- Active vision: A paradigm where sensing actions are chosen to improve perception and reduce uncertainty. "Active vision studies how sensing actions can be chosen to improve perception"
- Bayer-raw: Unprocessed image data captured through a Bayer color filter mosaic on the sensor. "dual-stream Bayer-raw video"
- Categorical distribution: A probability distribution over discrete categories, used here to model object selection at each timestep. "a categorical distribution over objects at each future timestep"
- Constant-velocity Kalman Filter: A Kalman Filter that assumes constant velocity dynamics to predict object motion. "We use a constant-velocity Kalman Filter to propagate this state forward:"
- Constant-velocity model: A motion assumption that objects continue at a constant velocity over short horizons. "a simple constant-velocity model provides a sufficiently accurate"
- Dual-stream acquisition: Simultaneous sensor readout of two video streams, typically a low-resolution context and high-resolution ROI. "supports dual-stream acquisition"
- Dual-stream sensors: Image sensors capable of outputting multiple simultaneous streams (e.g., global context and high-res ROIs). "Emerging dual-stream sensors with hundreds of millions of pixels"
- Eccentricity-dependent acuity: The decrease in visual acuity with increasing retinal eccentricity from the fovea. "ec-cen-tric-i-ty-dependent acuity of the retina"
- Ego vehicle: The vehicle equipped with the camera in a driving dataset or scenario. "as the ego vehicle moves"
- Event-based sensors: Asynchronous vision sensors that output events triggered by intensity changes rather than full frames. "event-based sensors"
- Full Field-of-View (FFoV): The entire sensor field imaged as a low-resolution global context stream. "Full Field-of-View (FFoV) context stream"
- Foveated imaging: Variable-resolution acquisition that allocates high detail to selected regions while maintaining lower detail elsewhere. "We introduce a real-time, predictive, and task-aware foveated imaging system"
- Hungarian matching algorithm: An algorithm for optimal assignment used here to associate detections across frames. "using the Hungarian matching algorithm"
- Intersection-over-Union (IoU): A metric measuring overlap between predicted and ground-truth regions, used for evaluation. "Intersection-over-Union (IoU)"
- Level-of-detail: A graphics technique that adjusts rendering or acquisition detail based on perceptual or task relevance. "guide level-of-detail and sampling decisions"
- Multi-aperture: Optical designs using multiple apertures to realize spatially varying resolution. "multi-aperture and wide-angle lens designs"
- Next-best-view: Planning the next viewpoint to maximize information gain for tasks like reconstruction or understanding. "next-best-view methods"
- Permutation-invariant: A model property where outputs are independent of the input order, important for set reasoning. "perform permutation-invariant global object reasoning"
- Pixel binning: Combining charge from adjacent pixels to reduce resolution and bandwidth while improving signal-to-noise. "through pixel binning or subsampling"
- Pixel throughput budget: A limit on the number of pixels that can be read or processed per unit time. "strict pixel throughput budget"
- Policy-based Recurrent Attention Models (RAM): Sequential attention models that learn where to attend via a policy over glimpses. "Policy-based Recurrent Attention Models (RAM)"
- Receding-horizon control: A control strategy that plans over a horizon but executes only a portion before replanning. "receding-horizon control"
- Region-of-Interest (ROI): A selected subregion of the image targeted for high-resolution capture or processing. "Region-of-Interest (ROI) crops"
- Saccading: Rapid gaze shifts; in this context, abrupt jumps of the high-resolution ROI between targets. "saccading scanpaths"
- Scanpath: The sequence of fixations or attended regions over time. "is referred to as a scanpath"
- Sensor attention policy: A learned policy that decides which pixels or regions the sensor should acquire at high resolution. "sensor attention policy"
- Set Transformer: A transformer architecture designed for sets, enabling permutation-invariant reasoning over object tokens. "Set Transformer encoder"
- Smooth pursuit: Continuous gaze tracking of moving targets; here, smoothly following targets with the ROI. "smooth pursuit behavior"
- Softmax: A normalization function that converts logits to probabilities for categorical decisions. "softmax"
- Temporal downsampling: Reducing frame rate to save bandwidth while retaining spatial resolution. "Temporal downsampling reduces the frame rate"
- Temporal skipping operator: An operator that selects frames at a defined stride and offset, effectively skipping frames. "temporal skipping operator"
- Tracking-by-detection: Tracking paradigm that links per-frame detections into trajectories. "tracking-by-detection algorithms"
- Transformer-based perception models: Vision models using transformer architectures, often with quadratic scaling in input resolution. "transformer-based perception models"
- YOLO-style: Refers to one-stage, real-time object detectors inspired by YOLO architectures. "YOLO-style saliency detector"
Collections
Sign up for free to add this paper to one or more collections.