- The paper introduces verifiable belief-space neural safety filters that use trusted inference to achieve less conservative safety verification and improve coverage by 1.87%.
- It employs an inference-aware conformal prediction method that certifies safety only in regions with reliable estimation, reducing unnecessary conservatism.
- Experimental results in an 18-dimensional driving simulation demonstrate a 94.3% safe rate and 99.8% task completion, outperforming traditional physical state methods.
Verifiable Belief-Space Neural Safety Filters for Assured Interactive Robotics
Introduction and Motivation
Autonomous robots operating alongside humans must guarantee safety under significant uncertainty, including unobservable human intentions, strategies, and varying levels of rationality. Traditionally, safety filters are implemented to shield robotic task policies, but these filters often operate solely in the physical state space and lack the capability to adapt online as inference about others improves. This leads to excessive conservatism and task inefficiency.
The studied paper introduces a framework for verifiable neural safety filters operating in belief spaces—the space combining physical state information with a robot's internal belief about other agents' latent types or intentions. The central contribution is a permissive, inference-aware safety verification procedure that allows robots to act less conservatively where their inference mechanisms are reliable, while maintaining high-probability safety guarantees even in the presence of neural approximation errors and imperfect inference (2606.02562).
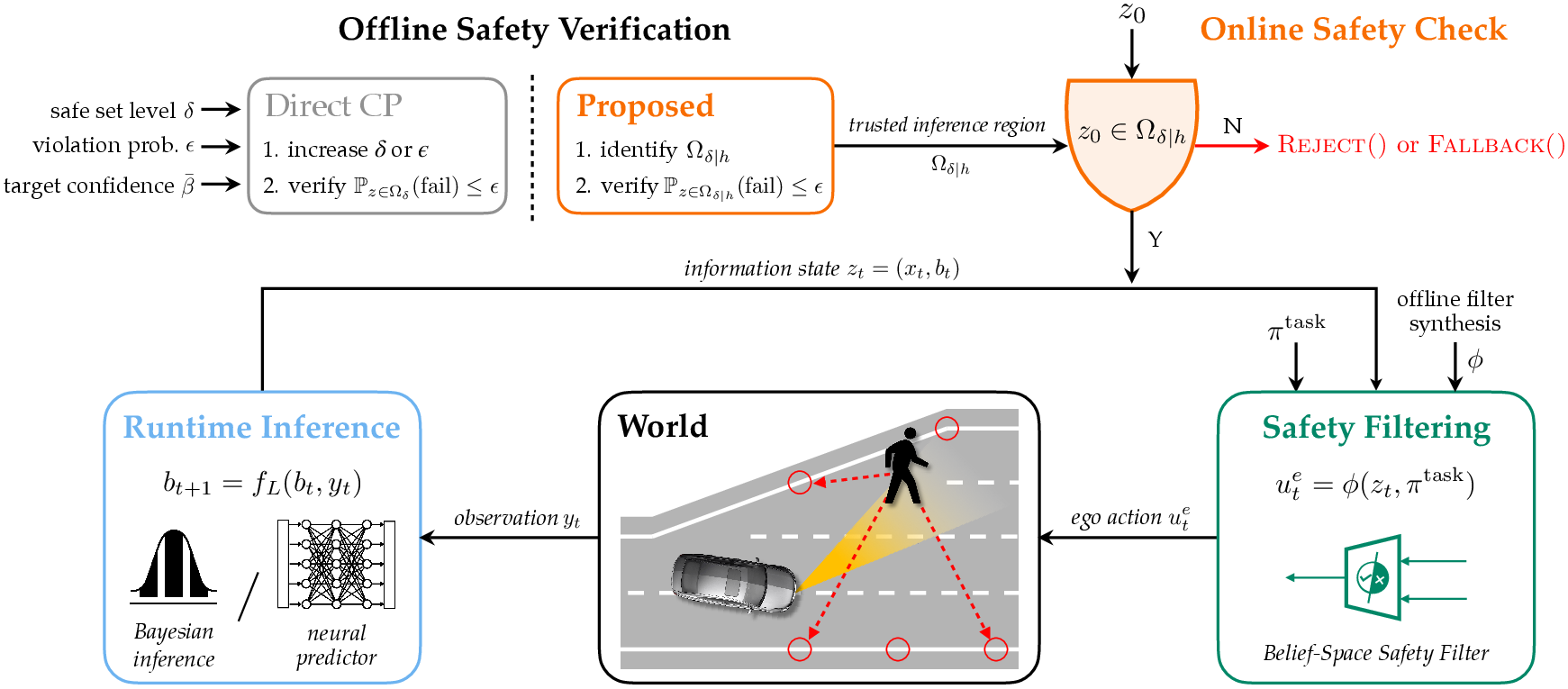
Figure 1: System overview highlighting offline verification of the belief-space safety filter and its online deployment; the approach yields a more permissive certified safe set than direct conformal prediction baselines.
The problem setup considers an "ego" robot dynamically interacting with adversarial or strategic opponents. Crucially, the robot's policies depend on both observed states and beliefs over latent opponent types (e.g., goals, willingness to cooperate), which evolve through online inference.
The methodology augments the robot's state with its belief, forming an information state zt=(xt,bt) governed by joint dynamics
zt+1=F(zt,ute,uto).
This allows the safety analysis (typically via Hamilton–Jacobi reachability) to account for the robot's ability to reduce uncertainty during interaction and thus dynamically adapt the set of safe actions.
Classic approaches, such as synthesizing safety sets via physical state only, treat opponent behavior as maximally adversarial everywhere—resulting in unnecessarily small safe sets and overly defensive behavior. The belief-space approach considers the robot's inference process, "shrinking" the set of admissible opponent actions wherever the belief is concentrated, thereby enabling substantially more permissive filtering.

Figure 2: Running example of vehicle–pedestrian interaction with robot uncertainty over opponent goals and types; adversarial behaviors may intentionally confuse the robot’s inference, challenging safety analysis.
The paper operationalizes this in a high-dimensional vehicle–pedestrian benchmark, modeling both semantic and goal uncertainties for the opponent, and demonstrates that a belief-space safety filter achieves a 94.3% empirical safe rate and 99.8% task completion, compared to only 77.7% and 37.6% for the purely physical state approach—a robust numerical claim.
While neural approximations (via deep RL or supervised learning) enable scaling up safety-filter synthesis, they eliminate formal guarantees. Standard conformal prediction (CP) procedures offer probabilistic safety guarantees by sampling system trajectories and checking empirical violation rates relative to a coverage parameter ϵ. However, naively applying CP in information space conflates failures due to inference errors with failures of the safety filter itself. Since inference errors may occur rarely in certain regions but CP shrinks the entire safe set uniformly, significant conservativeness results. This aspect is particularly pronounced in high-dimensional, adversarial scenarios.
The key insight in the paper is to separate the verification regions by inference quality: only certify the system in regions where inference is trusted (i.e., the inference mechanism is empirically unlikely to miss the opponent’s action in its predicted bound). This is accomplished by constructing a classifier or score function hL(z) that predicts inference reliability; only initial states z0 with hL(z0)≥0 are included in the "trusted inference region." The CP procedure then samples rollouts exclusively from this region, resulting in much less conservative safe sets.
The verification framework, termed the Joint Inference–Safety Test (JIST), is formalized as follows:
- Define the trusted inference region Ωδ∣h={z:V(z)≥δ,hL(z)≥0}.
- Verify the high-probability safety guarantee within Ωδ∣h via CP, tracking the number of failures k out of N rollouts and setting confidence and coverage parameters zt+1=F(zt,ute,uto).0 accordingly.
The theoretical justification follows standard exchangeability and i.i.d. assumptions in conformal prediction; within this regime, the approach provides rigorous, distributional guarantees.
Experimental Results
Empirical studies in an 18-dimensional simulated interactive driving scenario with a deceptive opponent demonstrate several strong, quantifiable claims:
- For a fixed zt+1=F(zt,ute,uto).1 and zt+1=F(zt,ute,uto).2, the direct CP procedure certifies safety coverage zt+1=F(zt,ute,uto).3 with 438 failures, while JIST achieves zt+1=F(zt,ute,uto).4 with only 107 failures—improving guaranteed coverage by 1.87% at the same base safe set level.
- The rejection rate (probability of rolling an initial state outside the certified safe set) for JIST remains close to the system’s false inference rate (~4.7%), much lower than the rate for direct CP, which grows rapidly as stricter zt+1=F(zt,ute,uto).5 are required for coverage parity.
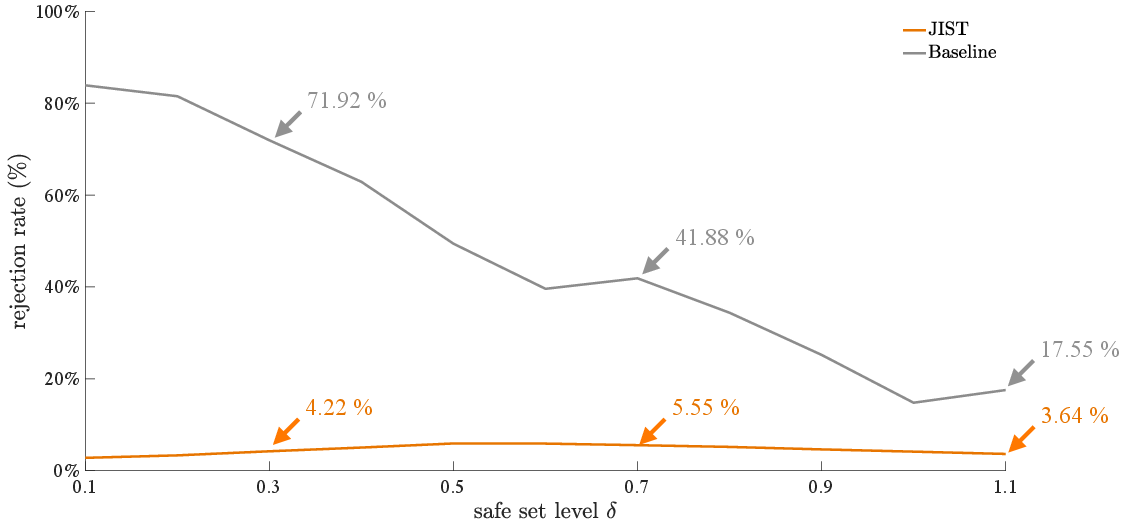
Figure 3: Rejection rates for direct CP and inference-aware JIST as a function of base safety level zt+1=F(zt,ute,uto).6 highlight the lower conservativeness of the inference-aware approach.
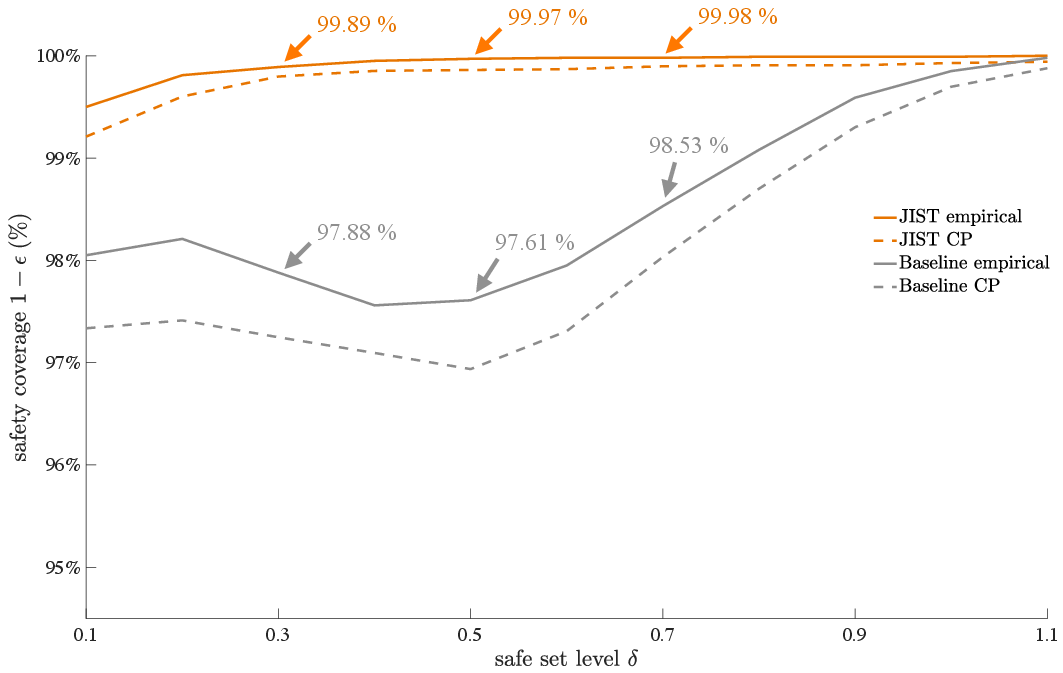
Figure 4: Safety coverage achieved at various safe set levels; JIST consistently certifies tighter coverage than the baseline.
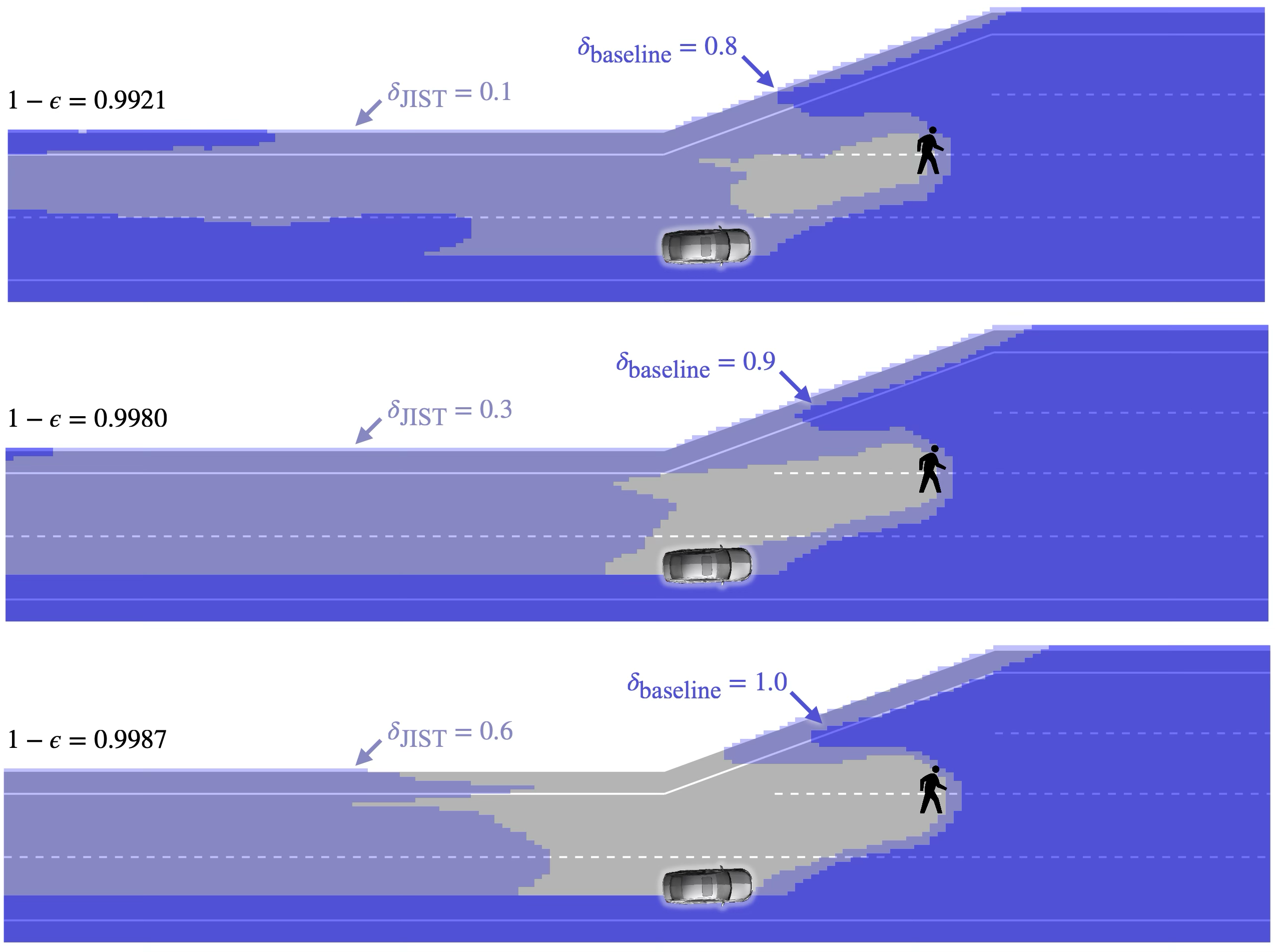
Figure 5: Certified safe set slices; JIST certifies a markedly larger region for the same coverage threshold compared to direct CP.
Scope, Limitations, and Future Directions
The presented methodology is only as strong as the inference module and the learned classifier zt+1=F(zt,ute,uto).7; significant errors in inference or miscalibration could negate the advantage of the approach. The guarantees are distributional (not worst-case) and depend on standard assumptions inherent in conformal prediction; further, the CP guarantees hold with respect to trajectory distributions induced by fixed opponent policies.
Possible extensions include:
- Adaptive CP variants to handle distribution shift induced by closed-loop interactions.
- Integration of more sophisticated learned inference models.
- Iterative design loops where verification outcomes inform filter/inference module parameter tuning.
- Generalization to safety filtering in learned latent spaces (e.g., vision-based policies).
- Layered safety architectures yielding robust fallback when inference is unreliable.
Conclusion
This work establishes a principled, scalable framework for certifying closed-loop safety of belief-space neural safety filters in interactive robotic settings under uncertainty. By conditioning verification on inference reliability, the framework achieves significantly more permissive certified safe sets and demonstrably higher task efficiency with high safety. The approach is positioned as a unifying and extensible template toward rigorous certification of permissive safety in learning-enabled, inference-rich robotic systems (2606.02562).

