- The paper introduces an LLM-guided evolutionary pipeline for discovering both CSS and non-CSS bivariate bicycle codes that leverage program synthesis.
- It employs a multi-stage verification approach combining fast rank checks, BP-OSD estimates, and MILP-based minimum distance validation.
- Empirical results reveal a consistent rate–distance tradeoff in codes, demonstrating scalability for high encoding rates and robust error correction.
LLM-Guided Evolutionary Discovery of Bivariate Bicycle Codes
Introduction and Motivation
This work presents a comprehensive study of quantum LDPC code discovery, specifically targeting the bivariate bicycle (BB) and perturbed bivariate bicycle (PBB) families, via a LLM-guided evolutionary pipeline. The approach leverages program synthesis at the generator ansatz level to explore vast algebraic code spaces inaccessible to exhaustively enumerative or gradient-based optimization methods. The context is the search for quantum error-correcting codes with high encoding rates, minimum distance, and favorable circuit-level properties that are crucial for scalable fault-tolerant quantum computing.
Evolutionary Pipeline Architecture
The pipeline combines LLM-driven program mutation with a multi-stage, highly parallelized verification cascade. The LLM proposes semantic diffs to a seed Python generator, which outputs candidate code polynomials (A,B) (or quadruples (A,B,C,D) in the PBB, non-CSS case) for a wide range of lattice dimensions. Candidates are screened in a sequence of steps: initial rapidly-computable rank checks, followed by (optionally) BP-OSD distance estimates, and then rigorous validation via MILP for minimum distance, Tanner graph canonicalization (BLISS), and local Clifford (LC) equivalence filtering for structural redundancy.
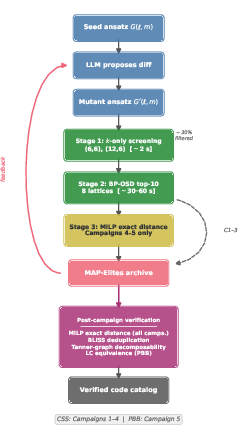
Figure 1: The evolutionary code discovery pipeline, showing LLM mutation, multi-stage validation, population archive via MAP-Elites, and deep structural verification.
This system results in high computational throughput (screening 2×105 candidates in ∼140 hours, costing ∼US\$400 in model inference) and yields generator programs whose algebraic patterns generalize beyond fixed(n,k) targets, facilitating the discovery of novel code families.
Structural Landscape of Discovered Codes
The campaigns (spanning trinomial/CSS and non-CSS ansätze with varying stabilizer weights) produced 97 unique CSS and 368 unique non-CSS PBB codes up to n=360. Structural classification (based on BLISS-canonical colored Tanner graphs) reveals convergence to well-known algebraic motifs (univariate/HGP, x/y-swap) as well as previously unreported mixed-monomial and higher-weight classes.
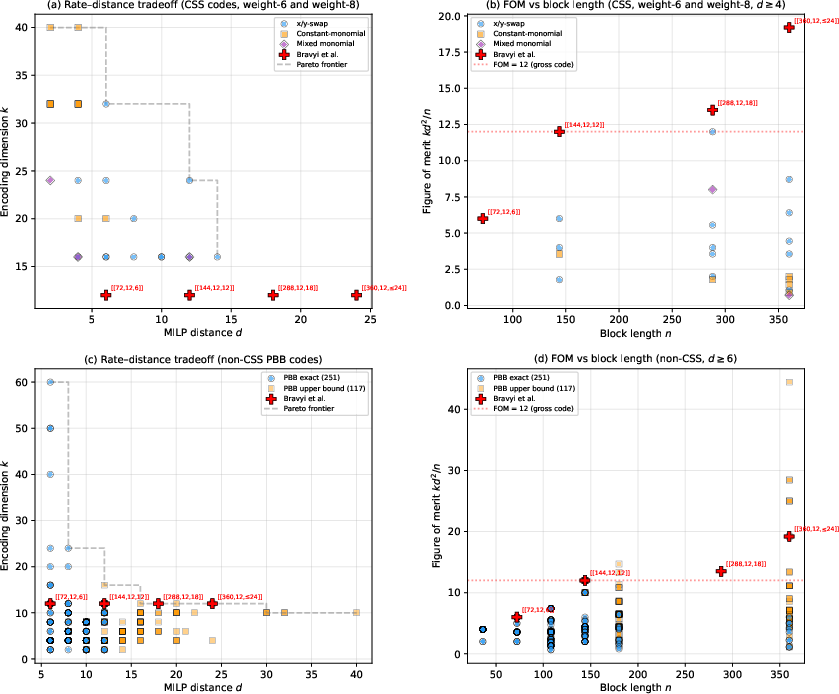
Figure 2: The rate--distance landscape. CSS and PBB (non-CSS) codes populate a similar Pareto frontier, exhibiting an empirical, structural tradeoff curve.
Empirical analysis identifies a rate--distance tradeoff that persists across code weight, algebraic generator family, and even the CSS/non-CSS divide. For standard (weight-6) CSS bivariate bicycle codes, encoding rates above k=24 (for n=288) universally imply (A,B,C,D)0, while codes with verified (A,B,C,D)1 ((A,B,C,D)2) are limited to (A,B,C,D)3. Similar constraints manifest for PBB codes, and even for mixed-monomial and higher-weight extensions, no code surpasses the existing Pareto envelope.
Rigorous Verification Methodology
A core contribution is the pipeline's multi-level exact verification of minimum distance, using MILP to overcome the severe overestimation of BP-OSD decoders (overestimation factors up to (A,B,C,D)4 for high-(A,B,C,D)5 codes with (A,B,C,D)6). The methodology includes per-logical MILP with tunable timeouts, group-theoretic code equivalence checks (BLISS), decomposability detection, and explicit LC (Hadamard and S) equivalence analysis for purportedly non-CSS codes. For PBB, an adaptive tiered pipeline combining enumeration, MILP, and achievable-syndrome sampling for BP-OSD is necessary, since the logical coset space is generally not surjective in non-CSS constructions.
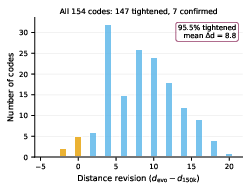
Figure 3: Tightening of distance estimates for 154 candidates—MILP validation discovers substantial overestimates in BP-OSD bounds especially for high-rate codes.
Numerical and Practical Results
- Among the 465 codes, the most relevant for quantum memories are the indecomposable CSS (A,B,C,D)7 ((A,B,C,D)8, all shifts (A,B,C,D)9 for local connectivity), the non-CSS PBB 2×1050 (matching the gross code's FOM 2×1051), and mixed-monomial weight-8 CSS codes encoding up to 2×1052 at 2×1053, 2×1054.
- BP-OSD fails to detect the minimal weight in the overwhelming majority of high-2×1055 samples; reliable claims for minimum distance require MILP, as stochastic syndrome decoding misses vast numbers of low-weight logicals even with 2×1056 trials.
- Block-level logical error rate simulations (BP-OSD decoding) confirm that only codes with 2×1057 achieve gross-code-level pseudo-thresholds; the non-CSS codes provide marginal improvements only under highly biased noise models.
Theoretical and Methodological Implications
The empirical rate--distance tradeoff suggests a possible structural limitation inherent in bivariate bicycle constructions over 2×1058, with all discovered codes saturating an envelope consistent with 2×1059 scaling. The pipeline methodology, grounded in LLM-guided program evolution and exact combinatorial verification, provides a blueprint for exploring complex, non-differentiable search spaces where symbolic mutation discovers generalizable construction principles rather than isolated optimal codes.
Discussion of Pipeline Insights and Limitations
Pipeline design decisions proved essential: segregating fast exact invariants (rank) from expensive fitness proxies (distance), and deferring exact MILP verification to a post-processing phase (or for top-k candidates) dramatically increased effective search volume. LLM mutations enabled generalization across block lengths, often independently reinvoking known algebraic constructions, and sidestepped the over-specialization seen in classical GA or random search.
Limiting factors include search space restriction (CSS, ∼0 only for some grids; major non-CSS structures with ∼1 excluded for computational feasibility), lack of full circuit-level decoder co-design, and LC-equivalence incompleteness for PBB codes (enumeration feasible only under certain Clifford subgroups due to exponential scaling).
Future Outlook
Research directions include expanding non-CSS and higher-rank abelian group constructions, integrating Bayesian/gradient-free optimization signals, and, crucially, carrying out circuit-level noise simulations to assess actual threshold behaviors and syndromic extraction feasibility for LLM-discovered codes. There is also a need to adapt the pipeline for efficient scaling to ∼2 using improved parallelization and advanced integer programming.
Conclusion
This paper rigorously demonstrates the practical value and scalability of LLM-guided program evolution for quantum code discovery, combining algebraic generality with post-hoc MILP certification, and sets a strong verification standard for future work in quantum LDPC code design. The results highlight both the practical code families accessible via algebraic program search and the persistent structural constraints faced within specific stabilizer code architectures (2606.02418).
References
- "Evolutionary Discovery of Bivariate Bicycle Codes with LLM-Guided Search" (2606.02418)