- The paper presents a unified text-guided counting task using a dual-branch model that combines region-level sparse and pixel-level dense counting to reduce error.
- The paper introduces CLOC, a large-scale benchmark with 220,000 images, 619 categories, and 15 million instances for robust cross-domain evaluation.
- The paper demonstrates that Complementary Count Fusion effectively merges outputs from both branches, enhancing interpretability and cross-domain stability.
Count Anything: A Generalist Framework for Cross-Domain Text-Guided Object Counting
Introduction and Motivation
"Count Anything" (2605.30846) addresses the persistent fragmentation in object counting research caused by the prevalence of domain-specific datasets and specialized models. While vision foundation models have demonstrated robust cross-domain generalization in detection and segmentation, object counting remains tied to closed scenarios, limiting transferability across scales, categories, and density regimes. This work proposes a unified text-guided instance-grounded counting task, coupled with CLOC—a large-scale, multi-source, cross-domain object counting benchmark designed to span General Scene, Remote Sensing, Histopathology, Cellular Microscopy, Agriculture, and Microbiology. The framework introduces a dual-branch modeling strategy, integrating region-level sparse enumeration and pixel-level dense recall, to bridge the representation gap encountered in current counting paradigms.
CLOC: Cross-Domain Large-Scale Object Counting Benchmark
The CLOC dataset is constructed via systematic reorganization of diverse public detection, segmentation, and counting datasets into a unified category-conditional counting format. CLOC comprises approximately 220,000 images, 619 categories, and 15 million annotated object instances, covering a broad array of visual domains and target-count densities.

Figure 1: Representative visual examples from the six visual domains of CLOC, illustrating substantial heterogeneity in domain appearance, density, and annotation.
Notably, CLOC harmonizes heterogeneous annotation protocols through rigorous instance audit and conversion, ensuring one-instance-one-count consistency. Its statistical distribution exhibits a marked long-tail in both category occurrence and target counts, critical for robust generalization evaluation.
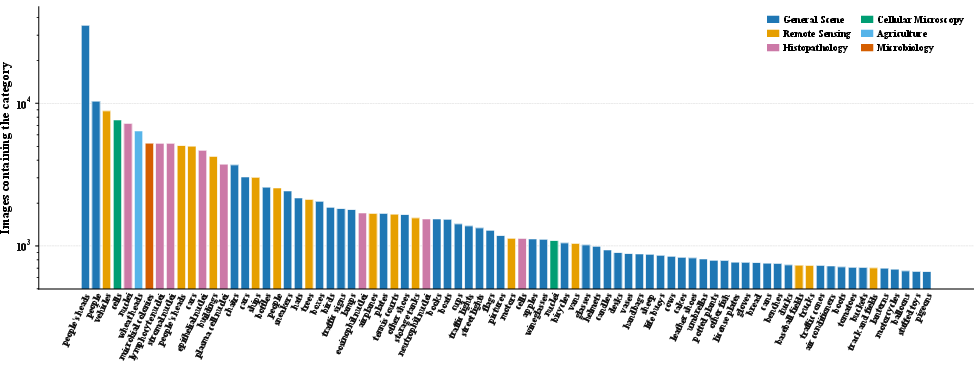
Figure 2: Category-level image frequency distribution for the 80 most common categories, color-coded by domain and plotted on a logarithmic scale.
CLOC encodes text-guided counting as inference over (image, query) pairs, expecting the model to enumerate all instances matching the provided text query—a concrete instantiation of open-vocabulary counting. The dataset construction pipeline encompasses data aggregation, countability auditing, instance format normalization, category unification, stratified sample augmentation (cropping, stitching), and a split strategy explicitly enforcing non-overlapping semantic category groups for unseen evaluation scenarios.

Figure 3: Overview of the CLOC construction pipeline, visualizing sequential stages of annotation harmonization, category consolidation, and splitting.
Model Architecture: The Count Anything Framework
The proposed model employs a dual-granularity instance enumeration strategy. Rather than relying on monolithic density maps or bounding-box regression, it predicts a set of spatially grounded instance points, supporting both cardinality estimation and interpretable localization.
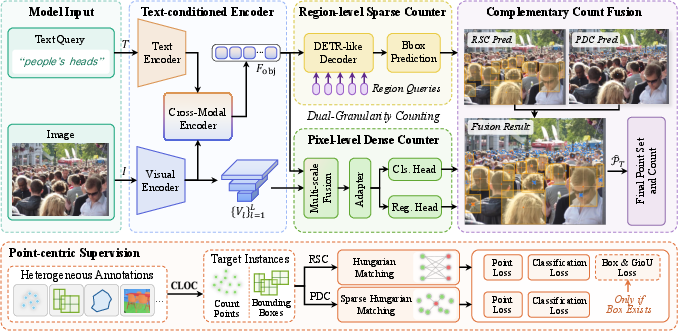
Figure 4: Overall framework of Count Anything, integrating a Text-Conditioned Encoder with dual counting branches and Complementary Count Fusion.
Training utilizes point-centric supervision to accommodate heterogeneous input annotation regimes—leveraging available bounding boxes for regression, relying on point annotations otherwise, and employing soft quality-based classification targets in region-specific branches.
Empirical Evaluation and Analysis
Count Anything is evaluated on CLOC and benchmarked against state-of-the-art text-guided and few-shot counting approaches as well as generalist detection/segmentation models. Experimental results demonstrate a pronounced margin in accuracy and cross-domain stability.

Figure 6: Qualitative comparison of counting predictions by Count Anything and baselines, illustrating closer alignment to ground truth across domains and densities.
On the full CLOC test set, Count Anything achieves MAE 9.34, RMSE 33.34, and NAE 0.75—representing a drastic reduction in error compared to competitive methods including CLIP-Count, VLCounter, and foundation model-driven detectors. This advantage persists across challenging domains (e.g., Histopathology, Microbiology) and high-density crowd counting, where pure detection and density-estimation models experience marked degradation.
Ablations underscore the necessity of both the RSC and PDC branches, as omitting either leads to significant performance drops. The effectiveness of Complementary Count Fusion is empirically supported—where direct union of prediction sets yields increased duplication errors.
Scaling analysis reveals that data size and domain diversity in CLOC linearly enhance generalist model robustness, affirming CLOC as an essential resource for future research.
Implications and Future Directions
The unified paradigm and architectural design in "Count Anything" represent a decisive shift toward open-world, interpretable, and generalizable counting. The point-set output format enables integrated support for downstream tasks such as instance selection, localization error diagnosis, and interactive counting correction. The decoupling of region-level and pixel-level predictors positions the model to adapt to the inherently multi-scale and heterogeneous nature of real counting applications.
Practically, this framework enables robust, user-customizable counting in domains previously inaccessible to specialist models, notably in scientific imaging and remote observation. Theoretically, the formulation highlights the necessity for hybrid spatial representations and revisits instance definition and supervision in multi-source, weakly labeled settings.
Potential directions include:
- Enhanced prompt conditioning leveraging large multimodal LLMs to better resolve semantic ambiguity,
- Incorporation of uncertainty estimates and active error-correction,
- More adaptive fusion mechanisms, potentially leveraging learned cross-branch attention rather than parameter-free heuristics,
- Expansion of CLOC with additional fine-grained categories, advanced domain balancing, or more natural-language-rich query scenarios.
Conclusion
"Count Anything" establishes both a methodological and data-centric foundation for generalist, instance-grounded text-guided counting. Through CLOC and its associated dual-granularity framework, the work sets a new standard for cross-domain, category-agnostic counting and paves the way for developments in open-world visual understanding, real-world automation, and systematic benchmarking of foundation models for counting tasks.