- The paper introduces MaskDiff-AD, a framework that computes anomaly scores using masked diffusion models tailored for discrete, categorical, and mixed-type data.
- It employs probe masking and multi-probe averaging to measure reconstruction surprisal, achieving efficient forward-only inference with strong theoretical guarantees.
- Empirical benchmarks on tabular and text datasets demonstrate superior ROC-AUC and PR-AUC performance over traditional and other diffusion-based methods.
Masked Diffusion Modeling for Anomaly Detection: Technical Analysis
Overview
"Masked Diffusion Modeling for Anomaly Detection" (2605.30046) introduces MaskDiff-AD, a forward-only anomaly detection framework leveraging masked diffusion models (MDMs) for discrete, categorical, and mixed-type datasets. The approach exploits the intrinsic structure of MDMs—used extensively for discrete generative modeling—to compute content-sensitive anomaly scores. These scores reflect a sample’s consistency with the normal data distribution based on the model’s reconstruction difficulty for randomly masked coordinates. The paper encompasses methodological innovations, theoretical guarantees, empirical benchmarking on a broad suite of tabular and text datasets, and key ablations that inform practical deployment in AI-based anomaly detection.
Methodological Contributions
Problem Setting and Motivation
Classical anomaly detection typically falters on discrete or mixed-type data because canonical approaches (e.g., kNN, Isolation Forest) presume continuous or Euclidean metric spaces for scoring. This issue exacerbates with the predominance of categorical variables in tabular data and tokens in text sequences. Standard diffusion models—while advancing continuous generative modeling—translate poorly to discrete scenarios due to incompatible noise processes. Masked diffusion models, which have recently gained traction for discrete generation, address this by introducing a masking process: a special absorbing state replaces (masks) features randomly, and models are trained to reconstruct the original values from the partially visible input.
The authors reveal that prior continuous diffusion-based anomaly detection (e.g., DTE [livernoche2024dte]) becomes degenerate under MDMs—the corruption-time posterior collapses and loses discriminative power—necessitating alternative scoring functions.
MaskDiff-AD: Reconstruction Surprisal as Anomaly Score
MaskDiff-AD is predicated on the expectation that normal samples possess mutually predictive features; anomalous samples disrupt this dependency, making their reconstruction, from masked views, less probable under the model trained on only normal data. The method proceeds:
- Probe Masking: For each test sample, generate multiple masked views at a grid of mask rates {τℓ}. Each coordinate is independently replaced by the mask token with probability 1−ατℓ (αt=1−t).
- Reconstruction Scoring: For each masked view x~, compute the average negative log-likelihood (NLL) of the masked coordinates under the predictive conditional models pθ^j(xj∣x~). Aggregate these scores over all masked views and probe levels to obtain a robust, content-sensitive anomaly score.
This approach directly leverages the statistical dependencies learned by the MDM and is fully forward-only—no reverse-time diffusion is required, yielding computational efficiency.
- Non-Parametric Variant: For low-cardinality or small-scale data, the paper introduces a non-parametric estimator for pj(xj∣x~) using a Hamming kernel on the visible coordinates, facilitating training-free anomaly detection via empirical statistics.
- Alternative Training Objective: The authors propose an alternative loss tailored to optimizing test-time detection by matching the probe mask rates; this loss is normalized per masked coordinate and computed at the specific mask grid, thereby aligning training with inference.
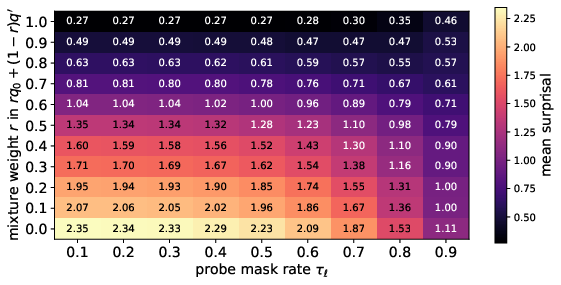
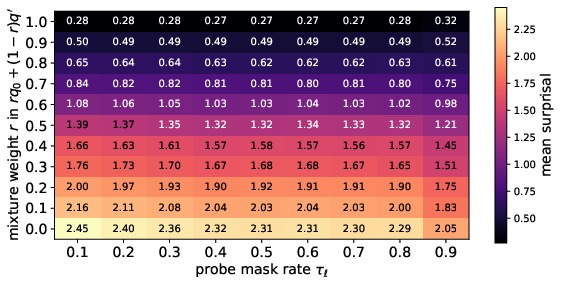
Figure 1: Synthetic heatmaps comparing the expectation of reconstruction anomaly scores (both non-parametric and parametric) under mixtures of nominal and anomalous samples as mask rates and anomaly mix rate vary.
Theoretical Analysis
Rigorous analysis underpins the construction of the anomaly score. The Type-I (false positive) and Type-II (false negative) errors are theoretically bounded in terms of (a) the separation between mean reconstruction scores of nominal and anomalous distributions, (b) the approximation error of the reconstruction model, and (c) the number of probe levels and masked views. If the predictive (conditional) models are near-optimal, the probability of error decays exponentially with the number of probes/views, and the score gap is dominated by the Kullback-Leibler divergence between conditional distributions under q0 and the alternative q′, validating the approach’s statistical power.
Empirical Benchmarking and Results
MaskDiff-AD is benchmarked on fourteen categorical/mixed-type tabular datasets and four discrete text anomaly detection datasets, comprising:
- Tabular: Diverse public datasets (from ADBench, UADAD) spanning finance, healthcare, network intrusion, and manufacturing, with high categorical or mixed-type feature loads.
- Text: Spam detection, news categorization, review filtering tasks, employing token level modeling.
Baselines include a comprehensive suite of classical, modern, and diffusion-based anomaly detectors (kNN, Isolation Forest, ECOD, COPOD, MCM, ICL, DRL, DTE variants, and others).
Key empirical findings:
- Tabular Domains: Parametric MaskDiff-AD achieves the best overall mean rank across both ROC-AUC and PR-AUC metrics, consistently outperforming classical baselines and DTE-based models, with the non-parametric variant also ranking highly. Notably, performance is strong even on challenging mixed-type and high-cardinality tasks.
- Text Domains: MaskDiff-AD gives high accuracy on short-sequence detection tasks (Email/SMS spam) but is outperformed by large pre-trained embedding methods (e.g., OpenAI embeddings plus GNN-based detection) on longer, richer texts, indicating domain-specific model limitations.
Detailed sensitivity analyses demonstrate that the anomaly score’s discriminative power depends on the probe mask rate (masking too little or too much erodes detection performance), but aggregation over a uniform mask grid (multi-probe averaging) yields robust, dataset-independent performance.
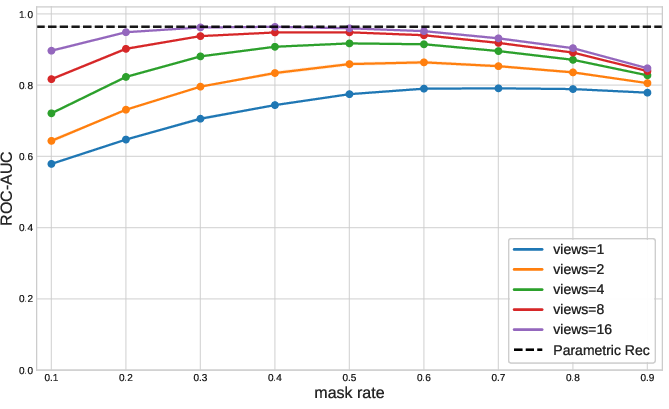
Figure 2: ROC-AUC performance across various probe mask rates on the Vehicle Claims dataset, illustrating sensitivity and the effect of multi-probe averaging.
Ablation and Sensitivity Analysis
Further explorations evaluate the effect of probe mask rate τ:
- Single Probe Sensitivity: ROC-AUC peaks at intermediate mask rates, suggesting a bias-variance tradeoff—the right amount of masking reveals violations of dependency structure without overwhelming the predictive context.
- Dataset Variation: The optimal mask rate is not universal; multi-probe aggregation is therefore preferred for generality.
- Nonparametric vs. Parametric: The empirical kernel approach performs comparably for small-scale binary-structured data but loses expressivity for complex/high-cardinality domains where deep conditional parameterization is advantageous.
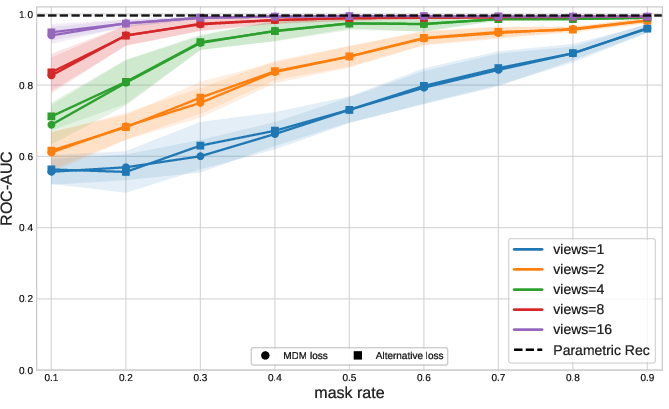
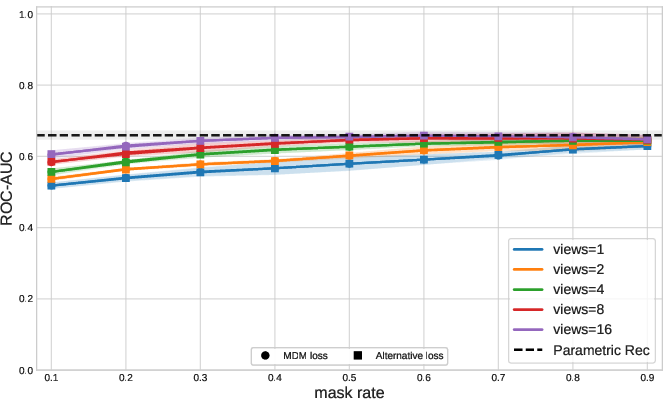
Figure 3: Additional datasets (U2R and Bank) replicate the trend of dataset-dependent mask rate sensitivity, justifying multi-probe design.
Practical and Theoretical Implications
The practical implication is a scalable, interpretable, and modular anomaly detection pipeline for complex, discrete data, compatible with both parametric neural models and non-parametric estimators. Theoretically, MaskDiff-AD validates reconstruction-based anomaly scoring for discrete domains, advancing over approaches built for continuous geometry or generative likelihoods. The forward-only inference ensures efficiency and makes MaskDiff-AD appealing for real-world, online, or resource-constrained applications.
Limitations and Future Prospects
While highly competitive on tabular and short-sequence tasks, MaskDiff-AD exhibits performance degradation on tasks requiring long-sequence contextualization (e.g., AGNews). This limitation is attributed to the simplicity of the token-level reconstruction model, suggesting an avenue for incorporating larger, pretrained backbone architectures, adaptive masking strategies, domain-specific conditioning (e.g., for time-series, molecules, or graphs), and semi-supervised anomaly ranking.
Conclusion
Masked Diffusion for Anomaly Detection establishes a robust, theoretically justified, and empirically effective strategy for anomaly detection in discrete and mixed-type data by leveraging the reconstruction difficulty under an MDM trained solely on nominal data. The approach is notable for its simplicity, efficient forward-only scoring, and strong empirical results. It sets a technical precedent for future research in discrete generative modeling for anomaly detection, including extensions to structured data, adaptive masking, and synergistic integration with LLMs.