- The paper introduces UniNote, a unified model that integrates multimodal embedding and relevance ranking in a single framework through a two-stage training process.
- It leverages contrastive supervised fine-tuning of a generative MLLM and RL-based reranking with advanced hard negative mining to optimize retrieval precision.
- Empirical results demonstrate significant recall and efficiency improvements, achieving up to 93.6% recall online and a 23.5% gain in offline retrieval.
UniNote: A Unified Embedding Model for Multimodal Representation and Ranking
Motivation and Framework
Item-to-Item (I2I) retrieval is a core primitive in content platforms, presenting complex requirements given the proliferation of multimodal user-generated items encompassing text, images, videos, and OCR-embedded visual content. Existing paradigms, particularly dual-tower architectures (e.g., CLIP, BLIP), exhibit structural inefficiencies, failing to reconcile global semantic encoding with localized retrieval needs or to integrate relevance ranking without a disjoint reranking pass. Multimodal LLM (MLLM) based approaches, while promising for semantic generalization, neglect granularity and suffer from expensive decoupled ranking pipelines. UniNote is introduced to unify multimodal embedding and ranking in a single model, supporting both coarse-grained global and fine-grained local retrieval, as well as relevance-aware ranking, with scalable deployment in industrial systems (Figure 1).
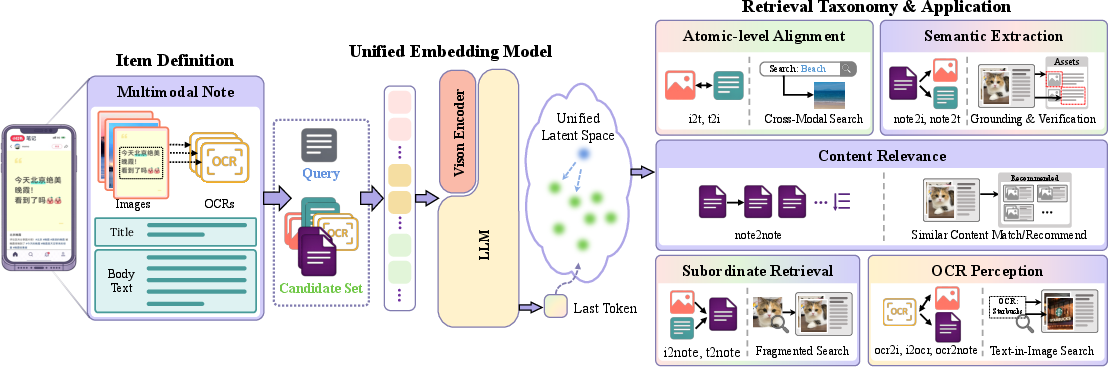
Figure 1: UniNote encodes heterogeneous items into a unified embedding space, supporting cross-modal alignment, localized retrieval, and relevance-aware ranking.
Two-Stage Training Paradigm
UniNote operationalizes its unified philosophy via a two-stage training pipeline (Figure 2). The first stage, Contrastive Supervised Fine-Tuning (SFT), adapts a generative MLLM into a robust embedding model by leveraging the last-token hidden state, optimized via JS divergence between embedding-based and MLLM-derived distributions. Hard negative mining is performed at multiple granularities, integrating global score-based negatives, counterfactual sampling, and rule-based membership subtractions to enforce semantic discrimination.
The second stage employs Relative Reranking via Reinforcement Learning (RL), instantiated with Group Relative Policy Optimization (GRPO). Here, the reward function is hierarchically designed to penalize irrelevant retrievals, reward recall, and optimize both absolute and relative ranking orders, directly shaping the embedding space for relevance-aware listwise ranking. Candidates are sampled via ANN-based pools, and intra-group advantage scores are used to optimize policy via GRPO, maximizing retrieval precision under industrial constraints.
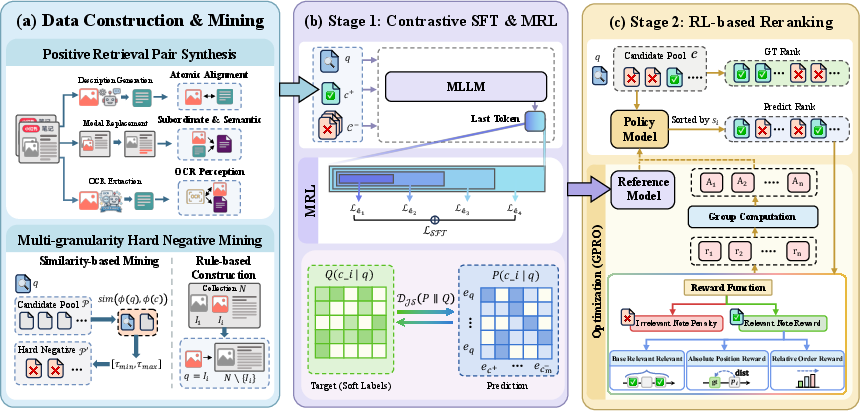
Figure 2: The UniNote pipeline: (a) data construction and hard negative mining; (b) contrastive SFT for base embedding; (c) RL-based reranking for listwise relevance alignment.
Reward Design and Ranking Optimization
The reward function is schematized in Figure 3 and achieves a balance between recall and precision, penalizing noise systematically, assigning base rewards for recall maximization, and deploying distance and order rewards to enforce ranking monotonicity. The reward’s decisive impact is evident in the simulated ranking metric distributions; relevant hit rates dominate reward values, which are further refined by order precision. The RL optimization directly leverages these reward signals to align embedding similarity with semantic overlap.
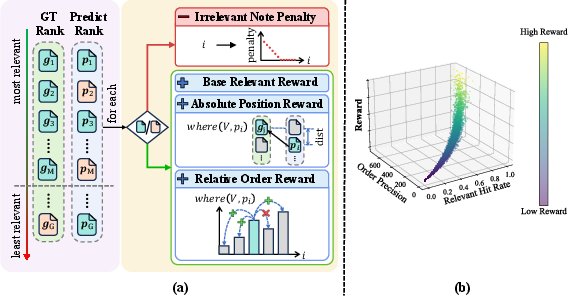
Figure 3: Reward function components and distribution: irrelevance penalty, base relevant reward, position-based rewards, and their joint effect on ranking quality.
Matryoshka Representation Learning for Flexible Deployment
UniNote supports Matryoshka Representation Learning (MRL), enabling multi-dimensional embedding outputs (64, 512, 1024, 4096) to balance retrieval performance and system efficiency. As shown in Figure 4, recall rates increase with feature dimension, yet even at dimension 512, performance converges to full-dimension capability. The model demonstrates graceful degradation: truncation to dimension 64 retains substantial retrieval quality (≈70%), offering cost-effective deployment for high-throughput, low-latency applications.
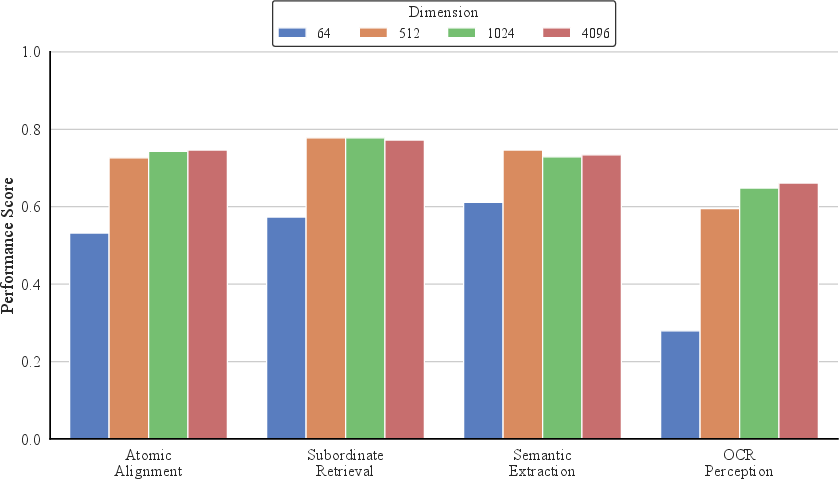
Figure 4: Recall vs. feature dimension: Matryoshka embeddings enable precision trade-offs for diverse deployment settings.
Empirical Results
UniNote is evaluated on Xiaohongshu’s large-scale multimodal corpus (66k notes, 500k items). Across ten retrieval categories—atomic alignment, subordinate retrieval, semantic extraction, OCR perception, and content relevance—UniNote achieves state-of-the-art recall on all but I2OCR, with dominant improvements notably in local-to-global and global-to-local tasks (e.g., image/text-to-note, OCR-to-note). Baseline methods (RzenEmbed, Qwen3VL-Embedding) fail to model hierarchical relationships and suffer in bidirectional recall tasks. Ablation studies confirm the necessity of advanced hard negative mining and RL-based relevance alignment; recall gains of 16.3% in total and precision increments of 3.4% in Note2Note tasks demonstrate the synergy of UniNote’s training regime.
Deployment and Practical Impact
The online and offline deployment pipeline (Figure 5) validates UniNote in real-world high throughput (online) and large gallery (offline) scenarios. Online, UniNote matches incoming notes against reference galleries, achieving up to 93.6% recall with a single embedding extraction—reducing storage and compute by 9.2x compared to CLIP-based baselines. Offline, retrieval from massive historical libraries delivers a 23.5% gain in relevant recall at equal compute, and unified note representation reduces duplicate recalls. These results substantiate UniNote’s superiority in cost-effective, scalable retrieval for heterogeneous content streams.
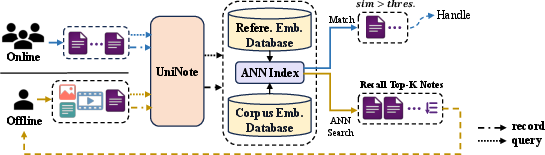
Figure 5: UniNote deployment: real-time corpus embedding and query verification (online); batch sample updating and large-scale retrieval (offline).
Implications and Future Prospects
UniNote’s architecture—unifying retrieval and ranking in a single embedding space—addresses multiple industrial bottlenecks: latency, relevance, and multimodality. The two-stage paradigm enhances granularity, discriminability, and listwise ranking precision without incurring computational reranking overhead. The Matryoshka embedding mechanism further points toward adaptive representation, enabling dynamic trade-offs between accuracy and efficiency.
Theoretically, UniNote demonstrates the viability of RL-based direct relevance optimization in embedding models, suggesting future directions in leveraging policy-guided reward shaping for other multimodal retrieval and ranking tasks. Further developments may explore more sophisticated reward functions—incorporating user feedback or domain-specific relevance constraints—and hierarchical representation learning to better capture nested structure in complex items.
Conclusion
UniNote represents a robust advance in multimodal item-to-item retrieval, systematically reconciling global representation and fine-grained local retrieval, and unifying relevance-aware ranking within a single embedding model. The framework achieves state-of-the-art recall and efficiency across diverse industrial scenarios, with empirical results validating its practical viability and theoretical potential for RL-based embedding optimization. The unified retrieval-ranking embedding space and Matryoshka dimensioning offer scalable, adaptive deployment for heterogeneous content platforms, indicating promising future extensions in multimodal retrieval architectures and reinforcement-driven embedding learning (2605.29287).

